
Boosting&kmeans&特征工程
文章目录
古语云:三个臭皮匠,顶一个诸葛亮。而在机器学习领域,集成算法Boosting就是一个活生生的实例。Boosting和之前介绍过的Bagging相似,都是集成算法之一。Boosting通过整合多个弱分类器,从而形成一个强分类器。具体如何构造,还需要有严谨的理论基础。
在1990年,RobertSchapire最先构造出了一种多项式级的算法,该算法可将若分类器组合成强分类器,即Boosting算法。一年后,Yoav Freund提出了一种效率更高的Boosting算法。但是这两个最初的Boosting算法存在缺陷:都要求实现知道弱学习算法学习正确率的下限。到了1995年,Freund和Schapire改进了Boosting算法,提出了AdaBoost(Adaptive Boosting)算法。该算法的优点:效率和Freund与1991年提出的Boosting算法几乎相同,但不需要任何关于弱学习器的先验知识,因而更加容易应用到实际问题中。
随后,两位创始人更进一步提出了AdaBoost.M1,AdaBoost.M2等算法,在机器学习领域受到了极大关注。Boosting在人脸识别、文本分类中应用较多。
Adaboost采用迭代的思想,每次迭代只训练一个弱分类器,训练好的弱分类器将参与下一次迭代的使用。也就是说,在第N次迭代中,一共就有N个弱分类器,其中N-1个是以前训练好的,其各种参数都不再改变,本次训练第N个分类器。其中弱分类器的关系是第N个弱分类器更可能分对前N-1个弱分类器没分对的数据,最终分类输出要看这N个分类器的综合效果。
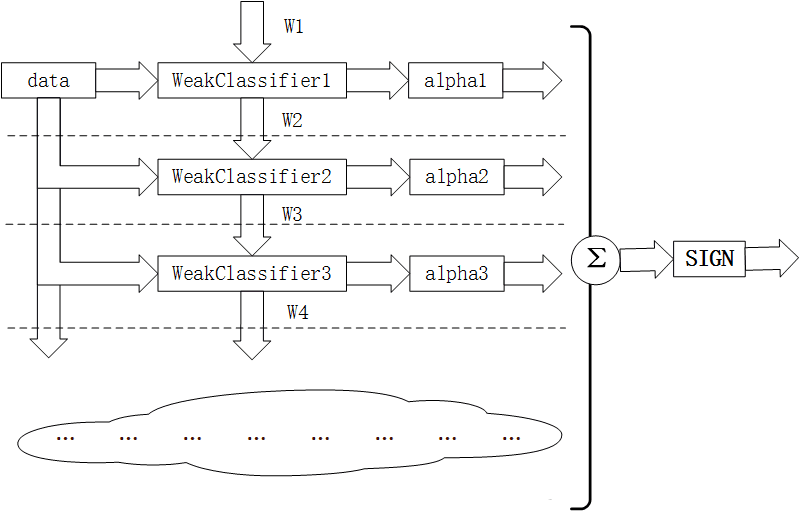
输入: 训练集 D = { (x_1,y_1),(x_2,y_2),\cdots,(x_m,y_m) }D={(x1,y1),(x2,y2),⋯,(xm,ym)}
基学习算法 \mathcal{L}L
训练轮数TT
过程:
D_1(x) = \frac{1}{m}D1(x)=m1
for \quad t = 1,2,\cdots,T \quad dofort=1,2,⋯,Tdo
\qquad h_t = \mathcal{L}(D,D_t)ht=L(D,Dt)
\qquad \epsilon_t = P_{x-D_t} (h_t(x) \neq f(x))ϵt=Px−Dt(ht(x)=f(x))
\qquad if \quad \epsilon_t > 0.5 \quad then \ breakifϵt>0.5then break
\qquad \alpha_t = \frac{1}{2} \ln{\left( \frac{1 - \epsilon_t}{\epsilon_t} \right)}αt=21ln(ϵt1−ϵt)
\qquad \begin{array}{c} & D_{t+1}(x) &=& \frac{D_t(x)}{Z_t} \times \begin{cases} \exp(-\alpha_t), & if \ h_t(x) = f(x) \ \exp(\alpha_t),& if \ h_t(x) \neq f(x) \end{cases} \ \ & &=& \frac{D_t(x) \exp(-\alpha_t f(x) h_t(x))}{Z_t} \end{array}Dt+1(x)==ZtDt(x)×{exp(−αt),exp(αt),if ht(x)=f(x)if ht(x)=f(x)ZtDt(x)exp(−αtf(x)ht(x))
end \ forend for
输出: H(x) = sign \left( \sum_{t=1}^T \alpha_t h_t(x) \right)H(x)=sign(∑t=1Tαtht(x))
这里对上述算法过程进行说明:
首先有训练集DD,且给每个样本的初始权重为 \frac{1}{m}m1
,然后开始迭代提升,逐步改变分类错误样本的权重.
对每一次迭代来说,第一步就是在 D_t(x)Dt(x) 数据集上训练一个分类器 h_tht,也就是算法中的(3)步;该分类器可以是决策树、SVM或logistic等等; D_t(x)Dt(x)是第tt步时的训练集分布,与初始训练集的不同就是每个样本的权重进行了重新分配.
(4)步是计算新训练的分类器的误差率.
(5)步是判断tt次迭代训练的分类器是否比随机猜测更好,如果得到的分类器比随机猜测坏的话就直接退出训练.
(6)(7)步是根据当前分类器的分类误差来更新每个样本的权重,以便下一轮弱分类器的训练;其中f(x),h_t(x) \in { -1,+1 }f(x),ht(x)∈{−1,+1}
最后输出这一步是加权多数表决的过程, sign()sign()是符号函数,即
sign(z) = \begin{cases} 1, & z > 0 \ 0, & z = 0 \ -1, & z < 0 \end{cases}sign(z)=⎩⎪⎨⎪⎧1,0,−1,z>0z=0z<0
前面我们将了算法过程,其中涉及到几个公式,既然是学习,我们就需要知其然知其所以然。
AdaBoost算法有多种推导方式,其中比较容易理解的是基于“加性模型”(additive model),即基学习器的线性组合:
H(x) = \sum_{t=1}^T \alpha_t h_t(x)H(x)=t=1∑Tαtht(x)
来最小化指数损失函数:
l_{exp}(H|D) = E_{x \approx D} \left[ e^{-f(x) H(x)} \right]lexp(H∣D)=Ex≈D[e−f(x)H(x)]
若H(x)H(x)能令指数损失函数最小化,则考虑损失函数对H(x)H(x)的偏导为零:
\begin{array}{c} & \frac{\partial l_{exp}(H|D) }{\partial H(x)} &=& E_{x \approx D} \left[ e^{-f(x) H(x)} * (- f(x)) \right] \ & &=& -e^{-H(x)} P(f(x) = 1 | x) + e^{H(x)} P(f(x)=-1 | x) \ &&=&0 \end{array}∂H(x)∂lexp(H∣D)===Ex≈D[e−f(x)H(x)∗(−f(x))]−e−H(x)P(f(x)=1∣x)+eH(x)P(f(x)=−1∣x)0
可解得
H(x) = \frac{1}{2} \ln{\frac{P(f(x) = 1 | x)}{P(f(x) = -1 | x)}}H(x)=21lnP(f(x)=−1∣x)P(f(x)=1∣x)
因此有
\begin{array}{c} & sign(H(x)) &=& sign \left( \frac{1}{2} \ln{\frac{P(f(x) = 1 | x)}{P(f(x) = -1 | x)}} \right) \ &&=& \begin{cases} 1, & P(f(x) = 1 | x) > P(f(x) = -1 |x) \ -1, & P(f(x) = 1 | x) < P(f(x) = -1 |x) \end{cases} \ &&=& \arg \max_{y \in {-1,1}} P(f(x) = y |x) \end{array}sign(H(x))===sign(21lnP(f(x)=−1∣x)P(f(x)=1∣x)){1,−1,P(f(x)=1∣x)>P(f(x)=−1∣x)P(f(x)=1∣x)<P(f(x)=−1∣x)argmaxy∈{−1,1}P(f(x)=y∣x)
这意味着若指数损失函数最小化,则分类错误率也将最小化;这说明指数损失函数是分类任务原0/10/1损失函数的一致的替代损失函数.因为指数损失函数数学性质更好.
上面一步说明了指数损失函数是有效的.下面考虑当基分类器 h_tht基于分布D_tDt产生后,该基分类器的权重\alpha_tαt应使得\alpha_t h_tαtht最小化指数损失函数:
\begin{array}{c} & l_{exp}(\alpha_t h_t | D_t) &=& E_{x \approx D_t} \left[ e^{-f(x) \alpha_t h_t(x)} \right] \ &&=& E_{x \approx D_t} \left[ e^{-\alpha_t} I(f(x) = h_t(x)) + e^{\alpha_t} I(f(x) \neq h_t(x)) \right] \ &&=& e^{-\alpha_t} P_{x \approx D_t} (f(x) = h_t(x)) + e^{\alpha_t} P_{x \approx D_t} (f(x) \neq h_t(x)) \ &&=& e^{-\alpha_t}(1 - \epsilon_t) + e^{\alpha_t} \epsilon_t \end{array}lexp(αtht∣Dt)====Ex≈Dt[e−f(x)αtht(x)]Ex≈Dt[e−αtI(f(x)=ht(x))+eαtI(f(x)=ht(x))]e−αtPx≈Dt(f(x)=ht(x))+eαtPx≈Dt(f(x)=ht(x))e−αt(1−ϵt)+eαtϵt
其中\epsilon_t = P_{x \approx D_t}(h_t(x) \neq f(x))ϵt=Px≈Dt(ht(x)=f(x)) . 考虑指数损失函数的导数:
\frac{\partial l_{exp}(\alpha_t h_t | D_t)}{\partial \alpha_t} = -e^{-\alpha_t}(1 - \epsilon_t) + e^{\alpha_t} \epsilon_t = 0∂αt∂lexp(αtht∣Dt)=−e−αt(1−ϵt)+eαtϵt=0
解得:
\alpha_t = \frac{1}{2} \ln{\left( \frac{1 - \epsilon_t}{\epsilon_t} \right)}αt=21ln(ϵt1−ϵt)
这就是上面算法过程中第 (6) 步中的权值更新公式.
其中, I(z) = \begin{cases} 1, & z = true; \ 0, & z = false; \end{cases}I(z)={1,0,z=true;z=false;为示性函数.
AdaBoost算法在获得H_{t-1}Ht−1之后样本分布将进行调整,并学习下一轮基学习器 h_tht,并且使得H_{t-1} + h_tHt−1+ht比H_{t-1}Ht−1的效果更好,即最小化
\begin{array}{c} & l_{exp}(H_{t-1} + h_t | D) &=& E_{x \approx D} \left[ e^{-f(x) (H_{t-1}(x) + h_t(x))} \right] \ &&=& E_{x \approx D} \left[ e^{-f(x) H_{t-1}(x)} e^{-f(x) h_t(x)} \right] \end{array}lexp(Ht−1+ht∣D)==Ex≈D[e−f(x)(Ht−1(x)+ht(x))]Ex≈D[e−f(x)Ht−1(x)e−f(x)ht(x)]
单独考虑e^{-f(x) h_t(x)}e−f(x)ht(x)
\because e^x = 1 + x + \frac{x^2}{2!} + \frac{x^3}{3!} + \cdots = \sum_{n=0}^{\infty} \frac{x^n}{n!} \ 又 \because f(x),h_t(x) \in { -1,+1 } \ \therefore e^{-f(x) h_t(x)} \approx 1 - f(x)h_t(x) + \frac{f^2(x) h_t^2(x)}{2} \ = 1 - f(x)h_t(x) + \frac{1}{2}∵ex=1+x+2!x2+3!x3+⋯=n=0∑∞n!xn又∵f(x),ht(x)∈{−1,+1}∴e−f(x)ht(x)≈1−f(x)ht(x)+2f2(x)ht2(x)=1−f(x)ht(x)+21
所以指数损失函数可以转换为:
l_{exp} (H_{t-1} + h_t | D) \approx E_{x \approx D} \left[ e^{-f(x) H_{t-1}(x)} \left( 1 - f(x)h_t(x) + \frac{1}{2} \right) \right]lexp(Ht−1+ht∣D)≈Ex≈D[e−f(x)Ht−1(x)(1−f(x)ht(x)+21)]
于是理想的基学习器为:
\begin{array}{c} & h_t(x) &= & arg \min_{h} l_{exp} (H_{t-1} + h_t | D) \ &&=& arg \min_{h} E_{x \approx D} \left[ e^{-f(x) H_{t-1}(x)} \left( 1 - f(x)h_t(x) + \frac{1}{2} \right) \right] \ &&=& arg \max_{h} E_{x \approx D} \left[ e^{-f(x) H_{t-1}(x)} f(x)h_t(x) \right] \ &&=& arg \max_{h} E_{x \approx D} \left[ \frac{e^{-f(x) H_{t-1}(x)}}{E_{x \approx D} \left[ e^{-f(x) H_{t-1}(x)} \right]} f(x)h_t(x) \right] \end{array}ht(x)====argminhlexp(Ht−1+ht∣D)argminhEx≈D[e−f(x)Ht−1(x)(1−f(x)ht(x)+21)]argmaxhEx≈D[e−f(x)Ht−1(x)f(x)ht(x)]argmaxhEx≈D[Ex≈D[e−f(x)Ht−1(x)]e−f(x)Ht−1(x)f(x)ht(x)]
需要注意的是,E_{x \approx D} \left[ e^{-f(x) H_{t-1}(x)} \right]Ex≈D[e−f(x)Ht−1(x)]是一个常数,已知的,因为在 tt轮迭代时,前面的 H_{t-1}(x)Ht−1(x)已经知道了,其实e^{-f(x) H_{t-1}(x)}e−f(x)Ht−1(x)也是已知的了.
于是令D_tDt表示一个分布
D_t(x) = \frac{D(x) e^{-f(x) H_{t-1}(x)}}{E_{x \approx D} \left[ e^{-f(x) H_{t-1}(x)} \right]}Dt(x)=Ex≈D[e−f(x)Ht−1(x)]D(x)e−f(x)Ht−1(x)
根据数学期望的定义,这等价于令
\begin{array}{c} & h_t(x) &=& arg \max_{h} E_{x \approx D} \left[ \frac{e^{-f(x) H_{t-1}(x)}}{E_{x \approx D} \left[ e^{-f(x) H_{t-1}(x)} \right]} f(x)h_t(x) \right] \ &&=& arg \max_{h} E_{x \approx D_t} [f(x)h(x)] \end{array}ht(x)==argmaxhEx≈D[Ex≈D[e−f(x)Ht−1(x)]e−f(x)Ht−1(x)f(x)ht(x)]argmaxhEx≈Dt[f(x)h(x)]
注意这里的数据集已经变了,由DD变成了D_tDt,两者的差别是分布已由D_t(x)Dt(x)的表达式更新了.
由于f(x),h(x) \in {-1,1}f(x),h(x)∈{−1,1},有
f(x)h(x) = 1 - 2*I(f(x) \neq f(x))f(x)h(x)=1−2∗I(f(x)=f(x))
则理想的基学习器为:
h_t(x) = arg \min_{h} E_{x \approx D_t} [I(f(x) \neq h(x))]ht(x)=arghminEx≈Dt[I(f(x)=h(x))]
由此可见,理想的h_tht将在分布D_tDt下最小化分类误差.因此,弱分类器将基于分布D_tDt来训练,且针对D_tDt的分类误差应小于 0.5 . 这在一定程度上类似“残差逼近”的思想。
考虑到D_tDt和D_{t+1}Dt+1的关系,有
\begin{array}{c} & D_{t+1}(x) &=& \frac{D(x) e^{-f(x)H_t(x)}}{E_{x \approx D} \left[ e^{-f(x) H_t(x)} \right]} \ &&=& \frac{D(x) e^{-f(x) H_{t-1}(x)} e^{-f(x) \alpha_t h_t(x)}}{E_{x \approx D} \left[ e^{-f(x) H_t(x)} \right]} \ &&=& D_t(x) \cdot e^{ef(x) \alpha_t h_t(x)} \frac{E_{x \approx D} \left[ e^{-f(x) H_{t-1}(x)} \right]}{E_{x \approx D} \left[ e^{-f(x) H_t(x)} \right]} \end{array}Dt+1(x)===Ex≈D[e−f(x)Ht(x)]D(x)e−f(x)Ht(x)Ex≈D[e−f(x)Ht(x)]D(x)e−f(x)Ht−1(x)e−f(x)αtht(x)Dt(x)⋅eef(x)αtht(x)Ex≈D[e−f(x)Ht(x)]Ex≈D[e−f(x)Ht−1(x)]
这就是上述算法过程中第 (7) 步的由来。
Gradient Boosting Modeling (梯度提升模型) 就是构造这些弱分类器的一种方法。它指的不是某个具体的算法,而是一种思想.
我们先从普通的梯度优化问题入手来理解
find \ \hat{x} = arg \min_{x} f(x)find x^=argxminf(x)
针对这种问题,有个经典的算法叫 Steepest Gradient Descent ,也就是最深梯度下降法。算法的大致过程是:
给定一个起始点x_0x0
对i = 1,2,\cdots,Ki=1,2,⋯,K分别做如下迭代:
\qquad x_i = x_{i-1} + \gamma_{i-1} \times g_{i-1}xi=xi−1+γi−1×gi−1
其中g_{i-1} = -\frac{\partial f}{\partial x} |{x = x{i-1}}gi−1=−∂x∂f∣x=xi−1表示ff在x_{i-1}xi−1点的梯度
直到|g_{i-1}|∣gi−1∣足够小,或者是|x_i - x_{i-1}|∣xi−xi−1∣足够小
以上迭代过程可以理解为: 整个寻优的过程就是小步快跑的过程,每跑一小步,都往函数当前下降最快的那个方向走一点,直到达到可接受的点.
我们将这个迭代过程展开得到寻优的结果:
x_k = x_0 + \gamma_1 g_1 + \gamma_2 g_2 + \cdots + \gamma_k g_kxk=x0+γ1g1+γ2g2+⋯+γkgk
这个形式是不是与最开始我们要求的F_m(x)Fm(x)类似;构造F_m(x)Fm(x)本身也是一个寻优的过程,只不过我们寻找的不是一个最优点,而是一个最优的函数。
寻找最优函数这个目标,也是定义一个损失函数来做:
find \ F_m = arg \ \min_{F} L(F) = arg \ \min_{F} \sum_{i=0}^N Loss(F(x_i),y_i)find Fm=arg FminL(F)=arg Fmini=0∑NLoss(F(xi),yi)
其中, Loss(F(x_i),y_i)Loss(F(xi),yi)表示损失函数Loss()Loss()在第ii个样本上的损失值, x_i,y_ixi,yi分别表示第 ii 个样本的特征和目标值.
类似最深梯度下降法,我们可以通过梯度下降法来构造弱分类器 f_1,f_2,\cdots,f_mf1,f2,⋯,fm只不过每次迭代时,令:
g_i = -\frac{\partial L}{\partial F}|{F=F{i-1}}gi=−∂F∂L∣F=Fi−1
即损失函数L()L()对FF求取梯度.
但是函数对函数求导不好理解,而且通常都无法通过上述公式直接求解。于是就采取一个近似的方法,把函数F_{i-1}Fi−1理解成在所有样本上的离散的函数值,即:
\left[ F_{i-1}(x_1),F_{i-1}(x_2),\cdots,F_{i-1}(x_N) \right][Fi−1(x1),Fi−1(x2),⋯,Fi−1(xN)]
这是一个NN维向量,然后计算:
\hat{g}i(x_k) = -\frac{\partial L}{\partial F(x_k)}|{F = F_{i-1}},k = 1,2,\cdots,Ng^i(xk)=−∂F(xk)∂L∣F=Fi−1,k=1,2,⋯,N
这是一个函数对向量的求导,得到的也是一个梯度向量。注意,这里求导时的变量还是函数F,不是样本x_kxk只不过对F(x_k)F(xk)求导时,其他的x_ixi都可以看成常数。
严格来说\hat{g}_i(x_k),k = 1,2,\cdots,Ng^i(xk),k=1,2,⋯,N只是描述了g_igi在某些个别点(所有的样本点)上值(连续函数上的离散点),并不足以表达g_igi ,但我们可以通过函数拟合的方式从\hat{g}_i(x_k)g^i(xk)构造g_igi ,这样我们就通过近似的方法得到函数对函数的导数了.
因此,GBM 的过程可以总结为:
选择一个起始常量函数 f_0f0
对i=1,2,\cdots,Ki=1,2,⋯,K分别做如下迭代:
计算离散梯度值\hat{g}{i-1}(x_j) = -\frac{\partial L}{\partial F(x_j)}|{F = F_{i-1}},j = 1,2,\cdots,Ng^i−1(xj)=−∂F(xj)∂L∣F=Fi−1,j=1,2,⋯,N
对\hat{g}{i-1}(x_j)g^i−1(xj)做函数拟合得到 g{i-1}gi−1
通过 line search 得到\gamma_{i-1} = arg \ \min L(F_{i-1} + \gamma_{i-1} g_{i-1})γi−1=arg minL(Fi−1+γi−1gi−1)
令F_i = F_{i-1} + \gamma_{i-1} g_{i-1}Fi=Fi−1+γi−1gi−1
直到|\hat{g}_{i-1}|∣g^i−1∣足够小,或者迭代次数完毕
这里常量函数 f_0f0通常取样本目标值的均值,即
f_0 = \frac{1}{N} \sum_{i=0}^N y_if0=N1i=0∑Nyi
在上述算法过程中,如何通过\hat{g}{i-1}(x_j),j = 1,2,\cdots,Ng^i−1(xj),j=1,2,⋯,N构造拟合函数 g{i-1}gi−1呢,这里我们用的就是 Decision Tree(决策树)了.
所以理解 GBDT,重点是先理解 Gradient Boosting,其次才是 Decision Tree;也就是说 GBDT 是 Gradient Boosting 的一种具体实现,这个拟合函数也可以改用其他的方法,只不过决策树好用一点。
从对 GBM 的描述里可以看到 Gradient Boosting 过程和具体用什么样的弱分类器是完全独立的,可以任意组合,因此这里不再刻意强调用决策树来构造弱分类器,转而我们来仔细看看弱分类器拟合的目标值,即梯度\hat{g}_{i-1}(x_j)g^i−1(xj) ,之前我们已经提到过
\hat{g}i(x_k) = -\frac{\partial L}{\partial F(x_k)}|{F = F_{i-1}},k = 1,2,\cdots,Ng^i(xk)=−∂F(xk)∂L∣F=Fi−1,k=1,2,⋯,N
因此\frac{\partial L}{\partial F(x_k)}∂F(xk)∂L很重要,以平方差损失函数为例,得:
\frac{\partial L}{\partial F(x_k)}|{F = F{i-1}} = 2(F_{i-1}(x_k) - y_k)∂F(xk)∂L∣F=Fi−1=2(Fi−1(xk)−yk)
忽略 2 倍,后面括号中正是当前已经构造好的函数F_{i-1}Fi−1在样本上和目标值y_kyk 之间的差值.
如果我们换一个损失函数,比如绝对差:
Loss(F(x_i),y_i) = |F(x_i) - y_i|Loss(F(xi),yi)=∣F(xi)−yi∣
这个损失函数的梯度是个符号函数:
\frac{\partial L}{\partial F(x_k)}|{F = F{i-1}} = sign(F_{i-1}(x_k) - y_k)∂F(xk)∂L∣F=Fi−1=sign(Fi−1(xk)−yk)
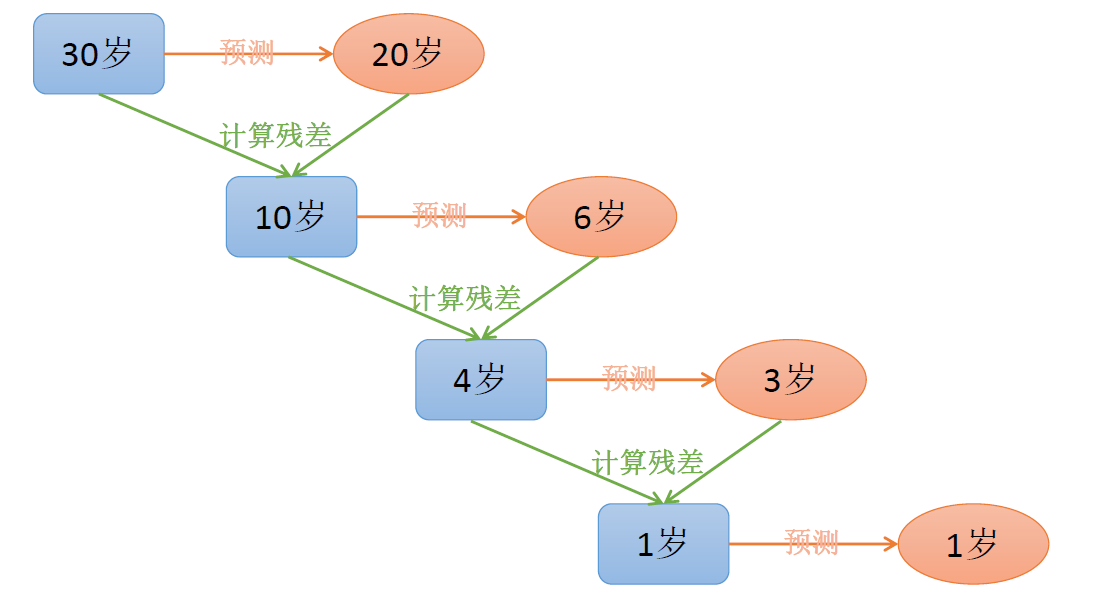
由此可以看到,只有当损失函数为平方差函数时,才能说 GBDT 是通过拟合残差来构造弱分类器的
GBDT 直观理解:每一轮预测和实际值有残差,下一轮根据残差再进行预测,最后将所有预测相加,就是结果。
GBDT 原始版本的算法框架:
输入:{ (x_i,y_i) }_1^N, K,L,\cdots{(xi,yi)}1N,K,L,⋯
初始化 f_0f0
for \quad k = 1 \ to \ K \quad dofork=1 to Kdo
\qquad \hat{y}i = -\frac{\partial L(y_i,F{k-1}(x_i))}{\partial F_{k-1}},i = 1,2,\cdots,Ny^i=−∂Fk−1∂L(yi,Fk−1(xi)),i=1,2,⋯,N
\qquad {R_j,b_j}1{J*} = arg \min{{R_j,b_j}1^J} \sum{i=1}^N \left[ \hat{y}_i - f_k(x_i;{R_j,b_j}_1^J) \right]2{Rj,bj}1J∗=arg{Rj,bj}1Jmini=1∑N[yi−fk(xi;{Rj,bj}1J)]2
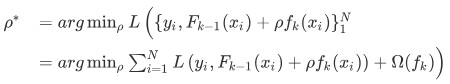
\qquad 令 \ f_k = \rho^* f_k,F_k = F_{k-1} + f_k令 fk=ρ∗fk,Fk=Fk−1+fk
endend
其中:
{(x_i,y_i)}_1^N{(xi,yi)}1N 表示NN个样本;
f_kfk表示第kk棵决策树,这棵决策树的预测值为f_k = \sum_{j=1}^J b_jfk=∑j=1Jbj
KK表示总共要生成的决策树数量;
JJ表示叶子节点的数量;
F_{k-1}(x_i)Fk−1(xi)表示前k-1k−1棵决策树综合得到的结果,即 F_{k-1} = \sum_{i=1}^{k-1} f_iFk−1=∑i=1k−1fi;
L(y_i,F_{k-1}(x_i))L(yi,Fk−1(xi))表示损失函数;
{R_j,b_j}_1^J{Rj,bj}1J表示一个划分, R_jRj表示叶子节点jj上的样本集合,b_jbj表示该叶子节点上的样本输出值. 该过程就是在函数空间的梯度下降,不断减去\frac{\partial L}{\partial F}∂F∂L ,就能得到 \min_F L(F)minFL(F)
下面解释一下上面的关键步骤:
第三步: \hat{y}iy^i 被称作响应(response),它是一个和残差y_i - F{k-1}(x_i)yi−Fk−1(xi)正相关的变量.
第四步: 使用平方误差训练一棵决策树 f_kfk,拟合数据 {x_i,\hat{y}_i}_1N{xi,yi}1N,注意这里是\hat{y}_iy^i ,拟合的是残差.
第五步: 进行线性搜索(line search),有的称作 Shrinkage ;上一步的ff是在平方误差下学到的,这一步进行一次 line search,让ff乘以步长\rhoρ后最小化LL .

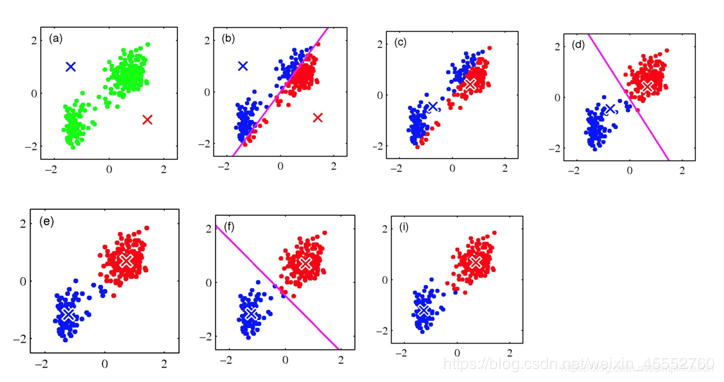
kmeans++ 选取初始点:
1、从输入的数据点集合(要求有k个聚类)中随机选择一个点作为第一个聚类中心;
2、对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x);
3、选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大;
4、重复2和3直到k个聚类中心被选出来;
5、利用这k个初始的聚类中心来运行标准的k-means算法。
kmeans算法是EM算法的一个特例
机器学习中,频率派经常会通过最大似然函数来求模型中的参数,但是有些模型中包含有不可见的隐变量Z,这样再通过最大似然求解就非常困难。一般如果模型中包含隐变量,我们就会使用加强版的最大似然-EM算法来求参数。常见包含隐参数的模型有高斯混合模型,隐马尔科夫模型,PLSA模型等等。下面我们以高斯混合模型为例来阐述为何有隐变量我们无法使用最大似然来估计参数。
首先我们先看看GMM的对数似然函数,单个高斯模型的参数我们用\theta=(u,\Sigma)θ=(u,Σ),表示,而在GMM模型中\piπ是隐变量:
lnp(X|\pi,\theta)=\sum_{n=1}^Nln\sum_{\pi} p(x_n,\pi|\theta)=\sum_{n=1}Nln\sum_{k=1}K \pi_kN(x_n|u_k,\Sigma_k)lnp(X∣π,θ)=n=1∑Nlnπ∑p(xn,π∣θ)=n=1∑Nlnk=1∑KπkN(xn∣uk,Σk)
由于对数里面有加和,直接对p(X|\theta)p(X∣θ)求最值很困难,我们可以试想下,如果隐变量\piπ是可以观测的,也就是知道每个数据点是由哪几个分布生成的,那么我们求解就会很方便,但关键的是\piπ是隐变量,我们没法观测到。但是我们可以用它的期望来表示。因此,只要将隐变量用它的期望表示就得到了大名鼎鼎的EM算法。具体过程如下:
lnp(X|\theta)lnp(X∣θ)是我们的原始似然函数,加入隐变量Z后可以写成ln\sum_Zp(X,Z|\theta)ln∑Zp(X,Z∣θ),我们先初始化模型的参数,由于隐变量无法观测到,我们用参数来得到它的后验p(Z|X,\theta_{old})p(Z∣X,θold),然后我们通过隐藏变量的期望得到新的complete-data likelihood:
Q(\theta,\theta_{old})=\int lnp(X,Z|\theta)p(Z|X,\theta_{old})dZQ(θ,θold)=∫lnp(X,Z∣θ)p(Z∣X,θold)dZ
以上就是E 步,当我们得到期望后就可以求出Q函数的最优解,也就是新的参数\theta=argmaxQ(\theta,\theta_{old})θ=argmaxQ(θ,θold),注意这个Q函数是包含隐变量的complete-data的似然函数,并不是我们一开始的似然函数,所以通过complete-data likelihood是可解析出新的参数。当我们将新的参数 \thetaθ再带入Q 函数不断就开始了第二轮迭代。
下面我们将来看看EM算法是怎么推导的:
先回顾优化理论中的一些概念。设f是定义域为实数的函数,如果对于所有的实数x,f’’(x)\geq 0f′′(x)≥0,那么f是凸函数。当x是向量时,如果其Hessian矩阵H是半正定的H\succeq 0H⪰0,那么f是凸函数。如果f’’(x)\geq 0f′′(x)≥0或者H\succeq 0H⪰0,那么称f是严格凸函数。
如果f是凸函数, 通过Jensen不等式我们知道:
f(\sum_{i=1}^n \lambda_ix_i)\leq \sum_{i=1}^n \lambda_if(x_i)\quad \lambda_i\geq 0\quad\sum_{i=1}^n\lambda_i=1f(i=1∑nλixi)≤i=1∑nλif(xi)λi≥0i=1∑nλi=1
如果x_ixi将看成随机变量,而将\lambda_iλi认为是x_ixi的出现概率则有:
f(E(x)) \leq E[f(x)]f(E(x))≤E[f(x)]
特别地,如果f是严格凸函数,那么当且仅当x=E[x]x=E[x]恒成立时,也就是说X是常量,有
E[f(x)]=f(E(x))E[f(x)]=f(E(x))
我们现在已经知道了Jensen不等式,假设给定的训练样本是{x_1,x_2,…,x_n}x1,x2,…,xn,样例间独立,我们想找到每个样例隐含的类别z_izi,能使得似然估计最大:
\begin{aligned} \ell(\theta) &= \sum_{i=1}^mlogp(x|\theta)\ &= \sum_{i=1}^mlog\sum_zp(x,z|\theta) \end{aligned}ℓ(θ)=i=1∑mlogp(x∣θ)=i=1∑mlogz∑p(x,z∣θ)
第一步是对极大似然取对数,第二步是对每个样例的每个可能类别z求联合分布概率和。但是直接求\thetaθ一般比较困难,因为有隐变量z存在,但是一般确定了z后,求解就容易了。EM是一种解决存在隐变量优化问题的有效方法。既然不能直接最大化\ell(\theta)ℓ(θ),我们可以不断地建立对数似然\ell(\theta)ℓ(θ)的下界(E步),然后优化下界(M步)
对于每一个样例i,让Q_iQi表示该样例隐变量z的某种分布,Q_iQi满足的条件是\sum_z Q_i(z)=1,Q_i(z)>0∑zQi(z)=1,Qi(z)>0。(如果z是连续性的,那么是概率密度函数,需要将求和符号换做积分符号)。比如要将班上学生聚类,假设隐藏变量z是身高,那么Q_iQi就是连续的高斯分布。如果按照隐藏变量是男女,那么就是伯努利分布了。可以由前面阐述的内容得到下面的公式:
\begin{aligned} \ell(\theta) &= \sum_{i=1}^mlog\sum_zp(x,z|\theta)\ &= \sum_{i=1}^mlog\sum_zQ_i \frac{p(x,z|\theta)}{Q_i}\ &\geq \sum_{i=1}^m\sum_z Q_i log \frac{p(x,z|\theta)}{Q_i} \end{aligned}ℓ(θ)=i=1∑mlogz∑p(x,z∣θ)=i=1∑mlogz∑QiQip(x,z∣θ)≥i=1∑mz∑QilogQip(x,z∣θ)
上式中第2步到第3步利用了Jensen不等式,考虑到loglog是凹函数(二阶导数小于0),而且\sum_zQ_i \frac{p(x,z|\theta)}{Q_i}∑zQiQip(x,z∣θ)是函数\frac{p(x,z|\theta)}{Q_i}Qip(x,z∣θ)在Q_iQi分布下的期望,所以logE[ \frac{p(x,z|\theta)}{Q_i}]\geq E[log \frac{p(x,z|\theta)}{Q_i}]logE[Qip(x,z∣θ)]≥E[logQip(x,z∣θ)]。
首先我们令\ell’(\theta)=\sum_{i=1}^m\sum_z Q_i log \frac{p(x,z|\theta)}{Q_i}ℓ′(θ)=∑i=1m∑zQilogQip(x,z∣θ)。上述过程可以看作\ell’(\theta)ℓ′(θ)是\ell(\theta)ℓ(θ)是的下界。对于Q_iQi的选择,有多种可能,哪种更好呢?假设\thetaθ已经给定,那么\ell’(\theta)ℓ′(θ)的值就决定于Q_iQi和p(x,z)p(x,z)了。我们可以通过调整这两个概率使下界不断上升,以逼近\ell(\theta)ℓ(θ)的真实值,那么什么时候算是调整好了呢?当不等式变成等式时,说明我们调整后的概率能够使\ell’(\theta)=\ell(\theta)ℓ′(θ)=ℓ(θ)了。按照这个思路,我们要找到等式成立的条件。根据Jensen不等式,要想让等式成立,需要让随机变量变成常数值,这里得到:
\frac{p(x,z|\theta)}{Q_i}=c \qquad (1)Qip(x,z∣θ)=c(1)
c为常数,不依赖于z_izi。对此式子做进一步推导,我们知道\sum_z Q_i(z)=1∑zQi(z)=1,那么也就有\sum_z p(x,z|\theta)=c∑zp(x,z∣θ)=c(多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c),将\sum_z p(x,z|\theta)=c∑zp(x,z∣θ)=c带入(1)式:
\begin{aligned} Q_i(z) &= \frac{p(x,z|\theta)}{c}\ &= \frac{p(x,z|\theta)}{\sum p(x,z|\theta)}\ &= p(z|x,\theta) \qquad (2) \end{aligned}Qi(z)=cp(x,z∣θ)=∑p(x,z∣θ)p(x,z∣θ)=p(z∣x,θ)(2)
至此,我们推出了在固定参数\thetaθ后,Q_i(z)Qi(z)的计算公式就是后验概率p(z|x,\theta)p(z∣x,θ),解决了Q_i(z)Qi(z)如何选择的问题。这一步就是E步,建立\ell(\theta)ℓ(θ)的下界。接下来的M步,就是在给定Q_i(z)Qi(z)后,调整参数\thetaθ,取极大化\ell(\theta)ℓ(θ)的下界(在固定Q_i(z)Qi(z)后,调整\thetaθ,使下界还可以调整的更大)。
将(2)式带入\ell’(\theta)ℓ′(θ)继续推导至简单形式:
\begin{aligned} \theta_{t+1} &= argmax_\theta \ell’(\theta)\ &= argmax_\theta \sum_{i=1}^m\sum_z Q_i log \frac{p(x,z|\theta)}{Q_i}\ &= argmax_\theta \sum_{i=1}^m\sum_zp(z|x,\theta_{t}) log \frac{p(x,z|\theta)}{p(z|x,\theta_{t})}\ &= argmax_\theta \sum_{i=1}^m\sum_zp(z|x,\theta_{t})logp(x,z|\theta)-p(z|x,\theta_{t})logp(z|x,\theta_{t}) \end{aligned}θt+1=argmaxθℓ′(θ)=argmaxθi=1∑mz∑QilogQip(x,z∣θ)=argmaxθi=1∑mz∑p(z∣x,θt)logp(z∣x,θt)p(x,z∣θ)=argmaxθi=1∑mz∑p(z∣x,θt)logp(x,z∣θ)−p(z∣x,θt)logp(z∣x,θt)
因为p(z|x,\theta_{t})logp(z|x,\theta_{t})p(z∣x,θt)logp(z∣x,θt)中的\theta_{t}θt都是定值,所以对\thetaθ求偏导时,会消掉,因此M步最大化的只有第一项sum_z p(z|x,\theta_{t})logp(x,z|\theta)sumzp(z∣x,θt)logp(x,z∣θ),即complete-data关于隐变量z的期望E_{z|x,\theta_t}[logp(x,z|\theta)]Ez∣x,θt[logp(x,z∣θ)]。
那么一般的EM算法的步骤如下:
初始化\theta_{old}θold
E步:对于每一个ii,计算p(z_i|x_i,\theta)p(zi∣xi,θ),求complete-data liklihood Q(\theta,\theta_{old})=\sum_z logp(x,z|\theta)p(z|x,\theta_{old})dzQ(θ,θold)=∑zlogp(x,z∣θ)p(z∣x,θold)dz
M步:更新参数 \theta=argmax_\theta Q(\theta,\theta_{old})θ=argmaxθQ(θ,θold)
跳转到第2步
何为特征工程呢?顾名思义,就是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。
本质上讲,特征工程是一个表示和展现数据的过程;实际工作中,特征工程的目的是去除原始数据中的杂质和冗余,设计更高效的特征以刻画求解的问题与预测模型之间的关系。
特征工程的重要性有以下几点:
特征越好,灵活性越强。好的特征的灵活性在于它允许你选择不复杂的模型,同时运行速度也更快,也更容易和维护。
特征越好,构建的模型越简单。好的特征可以在参数不是最优的情况,依然得到很好的性能,减少调参的工作量和时间,也就可以大大降低模型复杂度。
特征越好,模型的性能越出色。特征工程的目的本来就是为了提升模型的性能。
首先需要对数据进行预处理,一般常用的两种数据类型:
结构化数据。结构化数据可以看作是关系型数据库的一张表,每列都有清晰的定义,包含了数值型和类别型两种基本类型;每一行数据表示一个样本的信息。
非结构化数据。主要是文本、图像、音频和视频数据,其包含的信息无法用一个简单的数值表示,也没有清晰的类别定义,并且每个数据的大小互不相同。
这里主要介绍结构化数据和图像数据两种数据的数据预处理方法。
数据的缺失主要包括记录的缺失和记录中某个字段信息的缺失,两者都会造成分析结果的不准确。
缺失值产生的原因:
信息暂时无法获取,或者获取信息的代价太大。
信息被遗漏,人为的输入遗漏或者数据采集设备的遗漏。
属性不存在,在某些情况下,缺失值并不意味着数据有错误,对一些对象来说某些属性值是不存在的,如未婚者的配偶姓名、儿童的固定收入等。
缺失值的影响:
数据挖掘建模将丢失大量的有用信息。
数据挖掘模型所表现出的不确定性更加显著,模型中蕴含的规律更难把握。
包含空值的数据会使建模过程陷入混乱,导致不可靠的输出。
常见的缺失值的处理方法,主要有以下三种:
直接使用含有缺失值的特征:当仅有少量样本缺失该特征的时候可以尝试使用;
删除含有缺失值的特征:这个方法一般适用于大多数样本都缺少该特征,且仅包含少量有效值是有效的;
插值补全缺失值。
最常使用的还是第三种插值补全缺失值的做法,这种做法又可以有多种补全方法:
均值/中位数/众数补全
如果样本属性的距离是可度量的,则使用该属性有效值的平均值来补全;
如果样本属性的距离不可度量,则可以采用众数或者中位数来补全。
同类均值/中位数/众数补全
对样本进行分类后,根据同类其他样本该属性的均值补全缺失值,当然同第一种方法类似,如果均值不可行,可以尝试众数或者中位数等统计数据来补全。
固定值补全
利用固定的数值补全缺失的属性值。
建模预测
利用机器学习方法,将缺失属性作为预测目标进行预测,具体为将样本根据是否缺少该属性分为训练集和测试集,然后采用如回归、决策树等机器学习算法训练模型,再利用训练得到的模型预测测试集中样本的该属性的数值。
该方法根本的缺陷是如果其他属性和缺失属性无关,则预测的结果毫无意义;但是若预测结果相当准确,则说明这个缺失属性是没必要纳入数据集中的;一般的情况是介于两者之间。
高维映射
将属性映射到高维空间,采用独热码编码(one-hot)技术。将包含 K 个离散取值范围的属性值扩展为 K+1 个属性值,若该属性值缺失,则扩展后的第 K+1 个属性值置为 1。
这种做法是最精确的做法,保留了所有的信息,也未添加任何额外信息,若预处理时把所有的变量都这样处理,会大大增加数据的维度。这样做的好处是完整保留了原始数据的全部信息、不用考虑缺失值;缺点是计算量大大提升,且只有在样本量非常大的时候效果才好。
多重插补
多重插补认为待插补的值是随机的,实践上通常是估计出待插补的值,再加上不同的噪声,形成多组可选插补值,根据某种选择依据,选取最合适的插补值。
压缩感知和矩阵补全
压缩感知通过利用信号本身所具有的稀疏性,从部分观测样本中回复原信号。压缩感知分为感知测量和重构恢复两个阶段。
感知测量: 此阶段对原始信号进行处理以获得稀疏样本表示。常用的手段是傅里叶变换、小波变换、字典学习、稀疏编码等;
重构恢复: 此阶段基于稀疏性从少量观测中恢复原信号。这是 压缩感知的核心。
手动补全
除了手动补全方法,其他插值补全方法只是将未知值补以我们的主观估计值,不一定完全符合客观事实。在许多情况下,根据对所在领域的理解,手动对缺失值进行插补的效果会更好。但这种方法需要对问题领域有很高的认识和理解,要求比较高,如果缺失数据较多,会比较费时费力。
最近邻补全
寻找与该样本最接近的样本,使用其该属性数值来补全。
对于图片数据,最常遇到的问题就是训练数据不足的问题。
一个模型所能获取的信息一般来源于两个方面,一个是训练数据包含的信息;另一个就是模型的形成过程中(包括构造、学习、推理等),人们提供的先验信息。
而如果训练数据不足,那么模型可以获取的信息就比较少,需要提供更多的先验信息保证模型的效果。先验信息一般作用来两个方面,一是模型,如采用特定的内在结构(比如深度学习的不同网络结构)、条件假设或添加其他约束条件(深度学习中体现在损失函数加入不同正则项);第二就是数据,即根据先验知识来调整、变换或者拓展训练数据,让其展现出更多的、更有用的信息。
对于图像数据,如果训练数据不足,导致的后果就是模型过拟合问题,即模型在训练样本上的效果不错,但在测试集上的泛化效果很糟糕。过拟合的解决方法可以分为两类:
基于模型的方法:主要是采用降低过拟合风险的措施,如简化模型(从卷积神经网络变成逻辑回归算法)、添加约束项以缩小假设空间(如 L1、L2等正则化方法)、集成学习、Dropout方法(深度学习常用方法)等;
基于数据的方法:主要就是数据扩充(Data Augmentation),即根据一些先验知识,在保持特点信息的前提下,对原始数据进行适当变换以达到扩充数据集的效果。具体做法有多种,在保持图像类别不变的前提下,可以对每张图片做如下变换处理:
一定程度内的随机旋转、平移、缩放、裁剪、填充、左右翻转等,这些变换对应着同一个目标在不同角度的观察结果;
对图像中的元素添加噪声扰动,如椒盐噪声、高斯白噪声等;
颜色变换。比如在图像的 RGB 颜色空间进行主成分分析,得到 3 个主成分的特征向量p1,p2,p3以及对应的特征值λ1,λ2,λ3,然后在每个像素的 RGB 值上添加增量[p1,p2,p3]*[a1λ1,a2λ2,a3λ3],其中a1,a2,a3都是均值为 0, 方差较小的高斯分布随机数;
改变图像的亮度、清晰度、对比度、锐度等。
上述数据扩充方法是在图像空间进行变换的,也可以选择先对图像进行特征提取,然后在图像的特征空间进行变换,利用一些通用的数据扩充或者上采样方法,例如 SMOTE(Synthetic Minority Over-sampling Technique)。
此外,最近几年一直比较热门的 GAN,生成对抗网络,它的其中一个应用就是生成图片数据,也可以应用于数据扩充。
最后,还有一种方法可以不需要扩充数据,利用迁移学习的做法,也是如今非常常用的一个方法,微调(Finetuning),即借用在大数据集(如 ImageNet)上预训练好的模型,然后在自己的小数据集上进行微调,这是一种简单的迁移学习,同时也可以快速训练一个效果不错的针对目标类别的新模型。
异常值分析是检验数据是否有录入错误以及含有不合常理的数据。忽视异常值的存在是十分危险的,不加剔除地把异常值包括进数据的计算分析过程中,对结果会产生不良影响。
异常值是指样本中的个别值,其数值明显偏离其余的观测值。异常值也称为离群点,异常值分析也称为离群点分析,主要有以下几种方法:
1.简单统计:比如利用pandas库的describe()方法观察数据的统计性描述,或者简单使用散点图也能观察到异常值的存在,如下图所示:
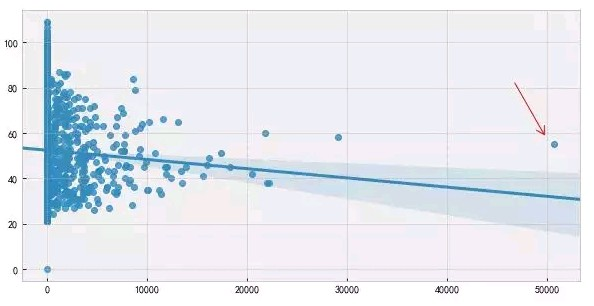
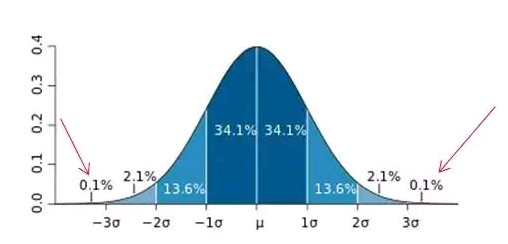
2.3∂原则: 这个原则有个条件:数据需要服从正态分布。在 3∂ 原则下,异常值如超过 3 倍标准差,那么可以将其视为异常值。正负3∂ 的概率是 99.7%,那么距离平均值 3∂ 之外的值出现的概率为P(|x-u| > 3∂) <= 0.003,属于极个别的小概率事件。如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。如下图所示:
3.箱型图
这种方法是利用箱型图的**四分位距(IQR)**对异常值进行检测,也叫Tukey‘s test。箱型图的定义如下:
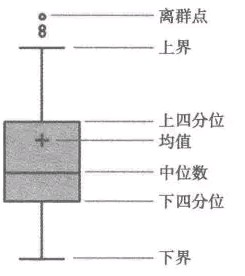
四分位距(IQR)就是上四分位与下四分位的差值。而我们通过IQR的1.5倍为标准,规定:超过上四分位+1.5倍IQR距离,或者下四分位-1.5倍IQR距离的点为异常值。
4. 基于模型预测
顾名思义,该方法会构建一个概率分布模型,并计算对象符合该模型的概率,将低概率的对象视为异常点。如果模型是簇的组合,则异常点是不在任何簇的对象;如果模型是回归,异常点是远离预测值的对象(就是第一个方法的图示例子)。
优缺点:
有坚实的统计学理论基础,当存在充分的数据和所用的检验类型的知识时,这些检验可能非常有效;
对于多元数据,可用的选择少一些,并且对于高维数据,这些检测可能性很差。
特征缩放主要分为两种方法,归一化和正则化。
归一化(Normalization),也称为标准化,这里不仅仅是对特征,实际上对于原始数据也可以进行归一化处理,它是将特征(或者数据)都缩放到一个指定的大致相同的数值区间内。
归一化的两个原因:
某些算法要求样本数据或特征的数值具有零均值和单位方差;
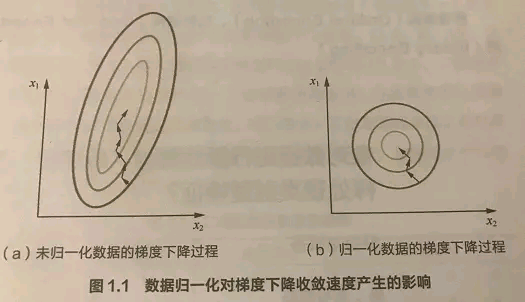
为了消除样本数据或者特征之间的量纲影响,即消除数量级的影响。如下图所示是包含两个属性的目标函数的等高线
数量级的差异将导致量级较大的属性占据主导地位。从下图左看到量级较大的属性会让椭圆的等高线压缩为直线,使得目标函数仅依赖于该属性。
数量级的差异会导致迭代收敛速度减慢。原始的特征进行梯度下降时,每一步梯度的方向会偏离最小值(等高线中心点)的方向,迭代次数较多,且学习率必须非常小,否则非常容易引起宽幅震荡。但经过标准化后,每一步梯度的方向都几乎指向最小值(等高线中心点)的方向,迭代次数较少。
所有依赖于样本距离的算法对于数据的数量级都非常敏感。比如 KNN 算法需要计算距离当前样本最近的 k 个样本,当属性的量级不同,选择的最近的 k 个样本也会不同。
如果数据集分为训练集、验证集、测试集,那么三个数据集都采用相同的归一化参数,数值都是通过训练集计算得到,即上述两种方法中分别需要的数据最大值、最小值,方差和均值都是通过训练集计算得到(这个做法类似于深度学习中批归一化,BN的实现做法)。
归一化不是万能的,实际应用中,通过梯度下降法求解的模型是需要归一化的,这包括线性回归、逻辑回归、支持向量机、神经网络等模型。但决策树模型不需要,以 C4.5 算法为例,决策树在分裂结点时候主要依据数据集 D 关于特征 x 的信息增益比,而信息增益比和特征是否经过归一化是无关的,归一化不会改变样本在特征 x 上的信息增益。
正则化是将样本或者特征的某个范数(如 L1、L2 范数)缩放到单位 1。正则化的过程是针对单个样本的,对每个样本将它缩放到单位范数。归一化是针对单个属性的,需要用到所有样本在该属性上的值。在前面系列课里对正则化有过详细的讲述,这里就不再扩展开来了,大家还有不理解的可以回过头再仔细读一下。
序号编码一般用于处理类别间具有大小关系的数据。
比如成绩,可以分为高、中、低三个档次,并且存在“高>中>低”的大小关系,那么序号编码可以对这三个档次进行如下编码:高表示为 3,中表示为 2,低表示为 1,这样转换后依然保留了大小关系。
热编码通常用于处理类别间不具有大小关系的特征。
独热编码是采用 N 位状态位来对 N 个可能的取值进行编码。比如血型,一共有 4 个取值(A、B、AB 以及 O 型),那么独热编码会将血型转换为一个 4 维稀疏向量,分别表示上述四种血型为:
A型:(1,0,0,0)
B型:(0,1,0,0)
AB型:(0,0,1,0)
O型:(0,0,0,1)
独热编码的优点有以下几个:
能够处理非数值属性。比如血型、性别等
一定程度上扩充了特征。
编码后的向量是稀疏向量,只有一位是 1,其他都是 0,可以利用向量的稀疏来节省存储空间。
能够处理缺失值。当所有位都是 0,表示发生了缺失。此时可以采用处理缺失值提到的高维映射方法,用第 N+1 位来表示缺失值。
顾名思义,离散化就是将连续的数值属性转换为离散的数值属性。
那么什么时候需要采用特征离散化呢?
这背后就是需要根据实际情况判断是采用“海量离散特征+简单模型”,还是“少量连续特征+复杂模型”的做法了。
对于线性模型,通常使用“海量离散特征+简单模型”。
优点:模型简单
缺点:特征工程比较困难,但一旦有成功的经验就可以推广,并且可以很多人并行研究。
对于非线性模型(比如深度学习),通常使用“少量连续特征+复杂模型”。
优点:不需要复杂的特征工程
缺点:模型复杂
离散化的常用方法是分桶, 具体流程如下:
将所有样本在连续的数值属性 j 的取值从小到大排列。
然后从小到大依次选择分桶边界。其中分桶的数量以及每个桶的大小都是超参数,需要人工指定。每个桶的编号为 0,1,…,M,即总共有 M 个桶。
给定属性 j 的取值 a,判断 a 在哪个分桶的取值范围内,将其划分到对应编号 k 的分桶内,并且属性取值变为 k。
分桶的数量和边界通常需要人工指定。一般有两种方法:
根据业务领域的经验来指定。如:对年收入进行分桶时,根据 2017 年全国居民人均可支配收入约为 2.6 万元,可以选择桶的数量为5。则分桶策略如下:
收入小于 1.3 万元(人均的 0.5 倍),则为分桶 0 。
年收入在 1.3 万元 ~5.2 万元(人均的 0.5~2 倍),则为分桶 1 。
年收入在 5.3 万元~26 万元(人均的 2 倍~10 倍),则为分桶 2 。
年收入在 26 万元~260 万元(人均的 10 倍~100 倍),则为分桶 3 。
年收入超过 260 万元,则为分桶 4 。
根据模型指定。根据具体任务来训练分桶之后的数据集,通过超参数搜索来确定最优的分桶数量和分桶边界。
选择分桶大小时,有一些经验指导:
分桶大小必须足够小,使得桶内的属性取值变化对样本标记的影响基本在一个不大的范围。
即不能出现这样的情况:单个分桶的内部,样本标记输出变化很大。
分桶大小必须足够大,使每个桶内都有足够的样本。
如果桶内样本太少,则随机性太大,不具有统计意义上的说服力。
每个桶内的样本尽量分布均匀。
在工业界实际应用中很少直接将连续值作为逻辑回归模型的特征输入,而是将连续特征离散化为一系列 0/1 的离散特征。
其优势有:
离散化之后得到的稀疏向量,内积乘法运算速度更快,计算结果方便存储。
离散化之后的特征对于 异常数据具有很强的鲁棒性。
如:销售额作为特征,当销售额在 [30,100) 之间时,为1,否则为 0。如果未离散化,则一个异常值 10000 会给模型造成很大的干扰。由于其数值较大,它对权重的学习影响较大。
逻辑回归属于广义线性模型,表达能力受限,只能描述线性关系。特征离散化之后,相当于 引入了非线性,提升模型的表达能力,增强拟合能力。
离散化之后可以进行特征交叉**。假设有连续特征 ,离散化为 N个 0/1 特征;连续特征 k,离散化为 M 个 0/1 特征,则分别进行离散化之后引入了 N+M 个特征。
假设离散化时,并不是独立进行离散化,而是特征 j,k 联合进行离散化,则可以得到 N*M 个组合特征。这会进一步引入非线性,提高模型表达能力。
离散化之后,模型会更稳定。
如对销售额进行离散化,[30,100) 作为一个区间。当销售额在40左右浮动时,并不会影响它离散化后的特征的值。
但是处于区间连接处的值要小心处理,另外如何划分区间也是需要仔细处理。
特征离散化简化了逻辑回归模型,同时降低模型过拟合的风险。
能够对抗过拟合的原因:经过特征离散化之后,模型不再拟合特征的具体值,而是拟合特征的某个概念**。因此能够**对抗数据的扰动,更具有鲁棒性。
另外离散化使得模型要拟合的值大幅度降低,也降低了模型的复杂度。
定义:从给定的特征集合中选出相关特征子集的过程称为特征选择(feature selection)。
1.对于一个学习任务,给定了属性集,其中某些属性可能对于学习来说很关键,但有些属性意义就不大。
对当前学习任务有用的属性或者特征,称为相关特征(relevant feature);
对当前学习任务没用的属性或者特征,称为无关特征(irrelevant feature)。
2.特征选择可能会降低模型的预测能力,因为被剔除的特征中可能包含了有效的信息,抛弃这部分信息一定程度上会降低模型的性能。但这也是计算复杂度和模型性能之间的取舍:
如果保留尽可能多的特征,模型的性能会提升,但同时模型就变复杂,计算复杂度也同样提升;
如果剔除尽可能多的特征,模型的性能会有所下降,但模型就变简单,也就降低计算复杂度。
3.常见的特征选择分为三类方法:
过滤式(filter)
包裹式(wrapper)
嵌入式(embedding)
采用特征选择的原因:
维数灾难问题。因为属性或者特征过多造成的问题,如果可以选择重要的特征,使得仅需要一部分特征就可以构建模型,可以大大减轻维数灾难问题,从这个意义上讲,特征选择和降维技术有相似的动机,事实上它们也是处理高维数据的两大主流技术。
去除无关特征可以降低学习任务的难度,也同样让模型变得简单,降低计算复杂度。
特征选择最重要的是确保不丢失重要的特征,否则就会因为缺少重要的信息而无法得到一个性能很好的模型。给定数据集,学习任务不同,相关的特征很可能也不相同,因此特征选择中的不相关特征指的是与当前学习任务无关的特征。有一类特征称作冗余特征(redundant feature),它们所包含的信息可以从其他特征中推演出来。冗余特征通常都不起作用,去除它们可以减轻模型训练的负担;但如果冗余特征恰好对应了完成学习任务所需要的某个中间概念,则它是有益的,可以降低学习任务的难度。
常见的特征选择方法分为以下三种,主要区别在于特征选择部分是否使用后续的学习器。
过滤式(filter):先对数据集进行特征选择,其过程与后续学习器无关,即设计一些统计量来过滤特征,并不考虑后续学习器问题
包裹式(wrapper):实际上就是一个分类器,它是将后续的学习器的性能作为特征子集的评价标准。
嵌入式(embedding):实际上是学习器自主选择特征。
最简单的特征选择方法是:去掉取值变化小的特征。
假如某特征只有 0 和 1 的两种取值,并且所有输入样本中,95% 的样本的该特征取值都是 1 ,那就可以认为该特征作用不大。
当然,该方法的一个前提是,特征值都是离散型才使用该方法;如果是连续型,需要离散化后再使用,并且实际上一般不会出现 95% 以上都取某个值的特征的存在。
所以,这个方法简单,但不太好用,可以作为特征选择的一个预处理,先去掉变化小的特征,然后再开始选择上述三种类型的特征选择方法。
该方法先对数据集进行特征选择,然后再训练学习器。特征选择过程与后续学习器无关。
也就是先采用特征选择对初始特征进行过滤,然后用过滤后的特征训练模型。
优点是计算时间上比较高效,而且对过拟合问题有较高的鲁棒性;
缺点是倾向于选择冗余特征,即没有考虑到特征之间的相关性。
过滤式选择主要有方差选择法和相关系数法。
1、方差选择法
使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
2、相关系数法
使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的 P 值。
相比于过滤式特征选择不考虑后续学习器,包裹式特征选择直接把最终将要使用的学习器的性能作为特征子集的评价原则。其目的就是为给定学习器选择最有利于其性能、量身定做的特征子集。
优点是直接针对特定学习器进行优化,考虑到特征之间的关联性,因此通常包裹式特征选择比过滤式特征选择能训练得到一个更好性能的学习器,
缺点是由于特征选择过程需要多次训练学习器,故计算开销要比过滤式特征选择要大得多。
在过滤式和包裹式特征选择方法中,特征选择过程与学习器训练过程有明显的分别。
嵌入式特征选择是将特征选择与学习器训练过程融为一体,两者在同一个优化过程中完成的。即学习器训练过程中自动进行了特征选择。
常用的方法包括:
利用正则化,如 L_1L1, L_2L2 范数,主要应用于如线性回归、逻辑回归以及支持向量机(SVM)等算法;
使用决策树思想,包括决策树、随机森林、Gradient Boosting 等。
引入 L_1L1 范数除了降低过拟合风险之外,还有一个好处:它求得的 ww 会有较多的分量为零。即:它更容易获得稀疏解。
于是基于 L_1L1 正则化的学习方法就是一种嵌入式特征选择方法,其特征选择过程与学习器训练过程融为一体,二者同时完成。
至此,统计学习相关内容已介绍完毕,下节课将给大家带来强化学习相关课程。
本博客所有内容仅供学习,不为商用,如有侵权,请联系博主,谢谢。
[1] 人工智能:一种现代的方法(第3版)
[2] 特征工程之特征缩放&特征编码





