
主键:一列或多列的组合,用于标识表中唯一的一条记录
主键不能重复,也不能为NULL值。一个表的主键,通常也会作为其他表引用的对象,即外键。
外键:通常用来建立两张表之间的关联关系
一个表的外键通常是与之关联的另一个表的主键
外键用于融合两张表:在进行关联查询时,可以通过两个表外键和主键之间的关系,将两张表连接起来,形成一张中间表。
表A和表B的关系:
1对1,是指表A和表B通过某字段关联后,表A中的一条记录最多对应表B中的一条记录,表B中的一条记录也最多对应表A中的一条记录。
1对多,是指表A和表B通过某字段关联后,表A中的一条记录可能对应表B中的多条记录,而表B中的一条记录最多对应表A中的一条记录。
多对多,是指表A和表B通过某字段关联后,表A中的一条记录可能对应表B中的多条记录,而表B中的一条记录可能对应表A中的多条记录。
*1对1 和 1对多关系,通常使用外键引用对应表的主键就可以表达。而多对多关系,通常需要使用中间表来表达,中间表中记录了两张表的主键的对应关系。
关于视图View:
如果一条SQL的结果在日常查询中经常被用到,我们通常就会考虑使用视图将其存储起来,下次再使用时直接读取视图,就会执行视图对应的SQL语句。
所以,视图就是一张虚拟的表。不过,视图存储的是SQL语句,而不是SQL执行后的结果,其结果是每次执行时动态生成的,可能每次读取都会有变化。
子查询的理论基础:把查询的结果再当做一个表,继续基于这个表做分析。
SQL语句关键字: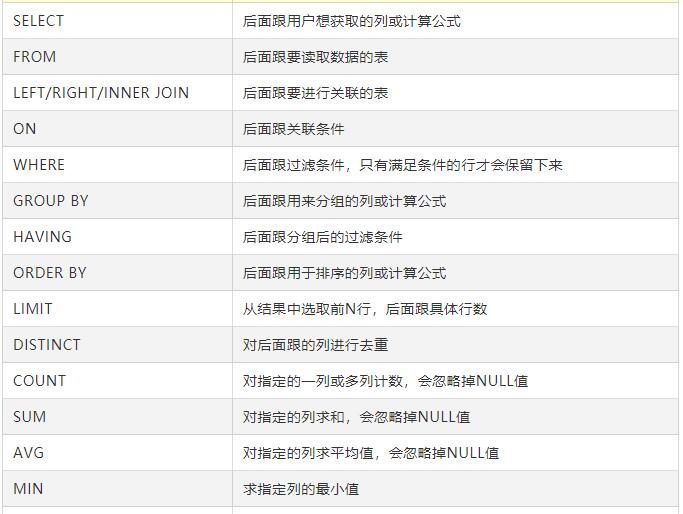
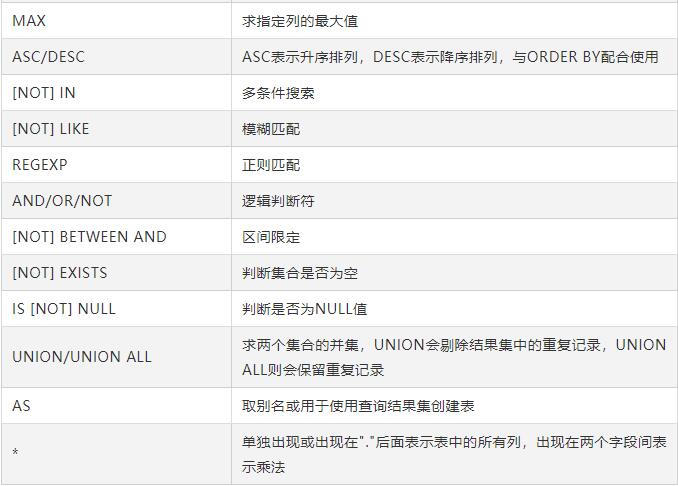
COUNT、SUM和AVG三个函数还可以和DISTINCT配合使用,其含义为先对目标列进行去重,之后再对去重后的结果聚合。SUM和AVG只能应用于一列,且列的数据类型为数值型。MIN和MAX也是只能应用于一列,不过除了支持数值型外,还支持字符串类型和日期类型。COUNT可以应用于一列或多列,而且不限制列的类型
SQL语句的写法上要注意:
日期和字符串常量需要使用英文单引号包裹起来,如 ‘2002-10-01 12:23:21’,‘Tess’;
注释的三种写法:单行注释(#,–)和多行注释(/* */)。单行注释推荐使用"–"。
SQL的“不等于”运算符: 有的数据库系统"!=“运算符可以与”<>"通用
基础实战:
假设有一张存储学生信息的表: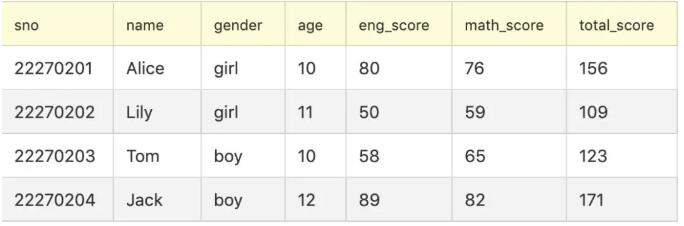
1.分组聚合
我们可以将表中的数据,根据某一列或多列进行分组,然后将其他列的值进行聚合计算,如计数、求和和求平均值等。
用到的关键字是GROUP BY,对于分组后的计算结果,我们还可以使用HAVING进行过滤。
实例:
从student表中,按照age分组:求出不同年龄的人数、英语总成绩和数学成绩的平均值,且过滤掉数学平均分不及格的。
对应的SQL脚本:
SELECT age, COUNT(sno) AS student_num,
SUM(eng_score) AS sum_eng_score,
AVG(math_score) AS avg_math_score
FROM student
GROUP BY age
HAVING avg_math_score >= 60
运行结果:
2.去重
DISTINCT关键字用于对一列或多列去重,返回剔除了重复行的结果。DISTINCT对多列去重时,必须满足每一列都相同时,才认为是重复的行进行剔除。DISTINCT不会过滤掉NULL值,但去重后的结果只会保留一个NULL值。
实例:
从student表中,找出有几种年龄的学生,即求出去重后的年龄
对应的SQL脚本:
SELECT DISTINCT age FROM student
运行结果: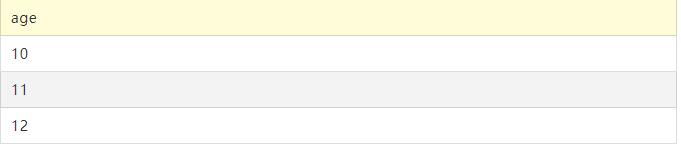
3.排序
日常生活场景里,我们经常对各种各样的排名比较感兴趣,比较关注排在前面的内容。在数据库中,求出排名,就需要用到ORDER BY子句。ORDER BY通常配合ASC和DESC使用,可以根据一列或多列,进行升序或降序排列,之后使用LIMIT取出满足条件的前N行
实例:
从student表中,求出数学成绩最好的前3名学生的姓名、年龄和其数学成绩
对应的SQL脚本:
SELECT name, age, math_score
FROM student
ORDER BY math_score DESC
LIMIT 3
运行结果: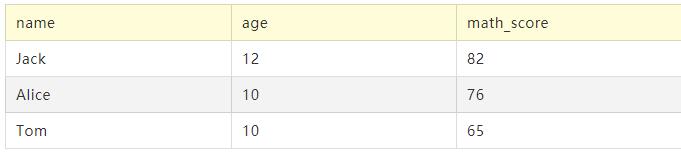
4.增加常量列
把某一固定的常量值做为一列添加到我们的结果数据中。这种做法的应用场景,通常是结果集中所有的行在某个属性上值是相同的,这时便可以通过增加常量列的方式,来增加这一列
实例:
从student表中,查询英语成绩大于80分的学生的姓名和学号,并把他们都分入A班
对应的SQL脚本:
SELECT sno, name, 'A' AS class FROM student WHERE eng_score > 80
运行结果:
其他函数:
算术函数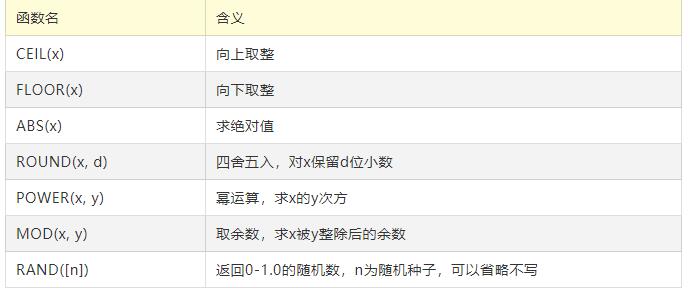
日期函数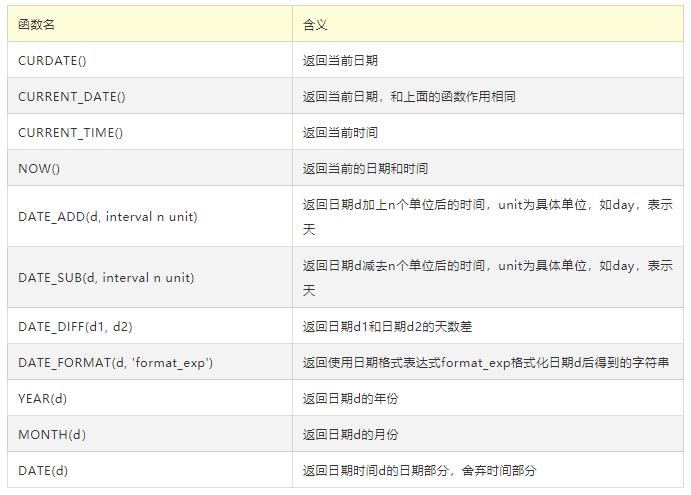
字符串函数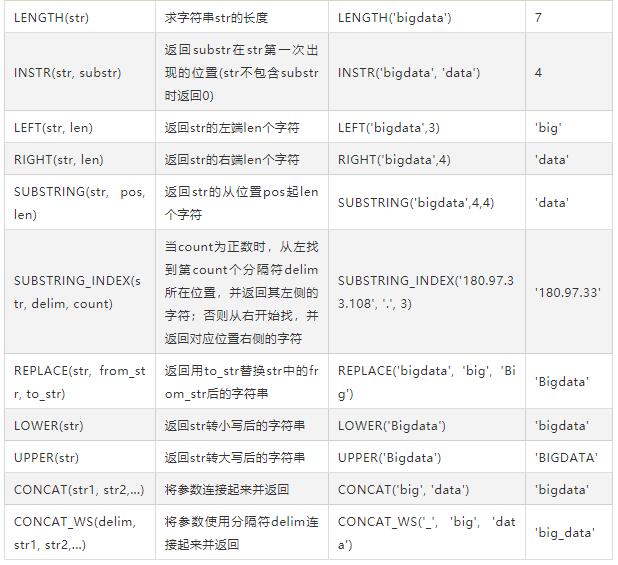
转换函数
当某些数据的类型与我们需要的类型不符时,可以使用类型转换函数,将其类型转换为我们需要的类型。常用的类型转换函数有两个,分别为CAST和CONVERT,两个函数的作用是相同的,只是语法略有不同。CAST函数的用法为CAST(字段 AS 数据类型),而CONVERT的用法为CONVERT(字段, 数据类型)
谓词
谓词就是用于真假判断的关键字,用来判定两个对象间关系论断的真假,返回值只有真或假
比较运算符,就属于谓词的范畴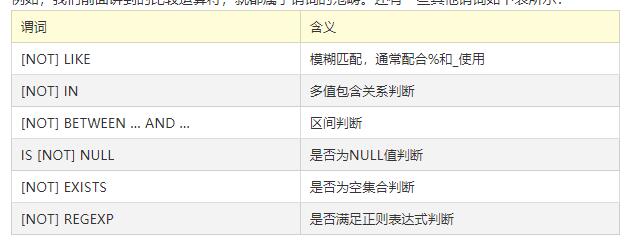
CASE表达式
SQL语句中的CASE表达式,对应着编程语言中的条件分支,起到多条件判断返回多种值的作用。其语法形式为:
CASE
WHEN <求值表达式1> THEN <表达式1>
WHEN <求值表达式2> THEN <表达式2>
WHEN <求值表达式3> THEN <表达式3>
......
ELSE <表达式> END
依次判断WHEN后面求值表达式返回的值为真或假,如果返回值为假,则继续向下搜索;如果返回值为真时,执行THEN后面对应的表达式,将执行后的值返回,CASE表达式退出;如果所有WHEN子句都不满足时,则执行ELSE后面的表达式,返回执行后得到的值,CASE表达式退出。
注意顺序:如果执行到第二个THEN的时候,实际生效的条件为<求值表达式1>的值为假,与此同时<求值表达式2>的值为真;如果执行到第三个THEN的时候,实际生效的条件为<求值表达式1>和<求值表达式2>的值都为假,与此同时<求值表达式3>的值为真,往后以此类推
实例:
从student表中,对学生进行成绩的等级划分,取出学生姓名及成绩等级
两门成绩都大于等于80分为优,两门成绩都大于等于60分但至少一门未达到80分的为良,一门成绩不及格为中,两门都不及格为差
对应的SQL脚本:
SELECT name,
CASE
WHEN math_score >= 80
AND eng_score >= 80 THEN '优'
WHEN math_score >= 60
AND eng_score >= 60 THEN '良'
WHEN math_score >= 60
OR eng_score >= 60 THEN '中'
WHEN math_score <= 60
AND eng_score < 60 THEN '差'
ELSE NULL
END AS score_grade
FROM student
运行结果: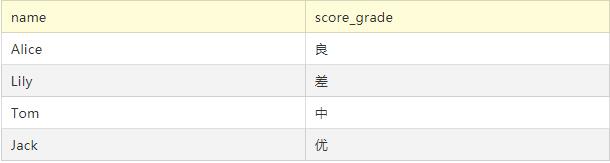
复杂语句:
1.什么是集合运算:
在数据库领域,集合是指一组记录的总和,它可以指代表,也可以指代视图、查询执行的结果。
–>所以,表和查询执行的结果都是集合,那么就都可以参与集合运算。
–>也就是说,可以把查询执行的结果看做是一张中间表或临时表,继续参与运算,这就是子查询的理论基础。
集合运算主要包含四种: 并集、交集、差集和笛卡尔积。
并集:
UNION会剔除掉合并后集合中的多余重复值,只保留一份;而UNION ALL,不会剔除重复值。因此,UNION操作,运行结束后,可能会导致记录数的减少。
交集:
求两个集合都共同拥有的元素的集合。在MySQL中没有提供专门的关键字,而是通过内关联实现的。
差集:
是求在一个集合中存在而在另一个集合中不存在的元素的集合。差集计算具有方向性,同样的,MySQL也没有提供差集计算的关键字,而是需要通过左/右关联然后再过滤出未关联成功的记录而得到。
笛卡尔积:
将两个集合中记录两两组合,相当于集合的乘法。它是关联查询的数学理论基础
关联查询的过程就是,先做笛卡尔积,然后再通过on条件过滤出符合条件的记录
进行集合的并集、交集和差集运算时,需要注意的是:
参与运算的两个集合记录的列数必须相同
参与运算的两个集合对应位置的列的类型必须一致
如果使用ORDER BY子句,必须写在最后
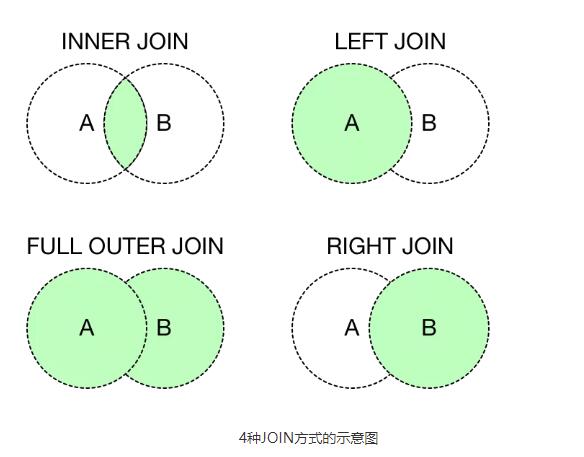
2.表关联类型
表关联类型有四种:内连接(INNER JOIN)、左外连接(LEFT OUTER JOIN)、右外连接(RIGHT OUTER JOIN)、全外连接(FULL OUTER JOIN)
语法:
A INNER JOIN B ON expr
A和B表示两个表的名称,也可以是子查询。ON后面跟的expr表示关联条件,通常是由表A和表B关联字段组成的表达式
内连接(INNER JOIN): 通常可以省略掉INNER不写
左右两个集合相乘后,只保留满足ON后面关联条件的记录。
所以,可以利用内连接计算两个集合的交集,只需要把集合元素的字段都写在ON后面的关联条件里即可。
左外连接(LEFT OUTER JOIN): OUTER通常可以省略不写
左右两个集合相乘后,保留满足ON后面关联条件的记录加上左表中原有的但未关联成功的记录
左外连接,可以用来计算集合的差集,只需要过滤掉关联成功的记录,留下左表中原有的但未关联成功的记录,就是我们要的差集。
右外连接(RIGHT OUTER JOIN),与左外连接含义相同,只是方向不同而已,通常也是省略OUTER不写。
全外连接(FULL OUTER JOIN)
左右两个集合相乘后,保留满足ON后面关联条件的记录加上左表和右表中原有的但未关联成功的记录。
图解:
从另一个角度来划分,连接还分为等值连接和不等值连接。这是由ON后面的子句决定的,如果关联字段使用等号判断是否相等就是等值连接,如果使用其他判断符号(如大于、小于等),则为不等值连接。
3.多表关联
多表关联的本质,还是两两关联。例如,表A内关联表B再内关联表C,实际上就可以等价于表A内关联表B,运行后的结果作为一张中间表,然后再与表C内关联。所以,执行过程仍然是两两关联。
4. 表关联注意事项
a. 使用UNION可能会导致记录数的减少,在使用聚合函数时,可能会导致计算出现偏差
b. 在使用1对多或多对多关系的表进行关联时,记录数可能会增多,也可能会导致计算出现偏差
c. 左外连接和右外连接都有连接方向的问题,表放的位置对结果是有影响的,尤其是多表关联时,一定要关注书写的顺序,尽可能先做内连接再做左/右外连接。
d. 尽量避免使用交叉连接
5.子查询
就是指被括号嵌套起来的查询SQL语句,通常是一条完整的SELECT语句。
子查询放在不同的位置,起到的作用也是不同的。它经常出现在3个位置上,分别是
SELECT后面、FROM/JOIN后面,还有WHERE/HAVING后面。
子查询出现在SELECT后面
其作用通常是要为结果添加一列。不过,这里要注意的是,在SELECT后使用的子查询语句只能返回单个列,且要保证满足条件时子查询语句只会返回单行结果。企图检索多个列或返回多行结果将引发错误。
子查询出现在FROM/JOIN后面
是我们最常用的方式,就是将子查询的结果作为中间表,继续基于这个表做分析。
子查询出现在WHERE/HAVING后面
则表示要使用子查询返回的结果做过滤。这里根据子查询返回的结果数量,
分三种情况,即1行1列、N行1列、N行N列:
当返回结果为1行1列时,实际上就是返回了一个具体值,这种子查询又叫标量子查询。标量子查询的结果,可以直接用比较运算符来进行计算。
当返回结果是N行1列时,实际上就是返回了一个相同类型数值的集合。因此可以使用IN谓词判断,同时也可以配合ANY、SOME、ALL等关键字使用。
当返回结果是N行N列时,实际上就是返回一个临时表,这时就不能进行值的比较了,而是使用EXISTS谓词判断返回的集合是否为空。
参考教程:
《数据库原理及应用》主编:何玉洁、刘福刚
《SQL必知必会》作者:福塔
《SQL基础知识》作者:MICK





