
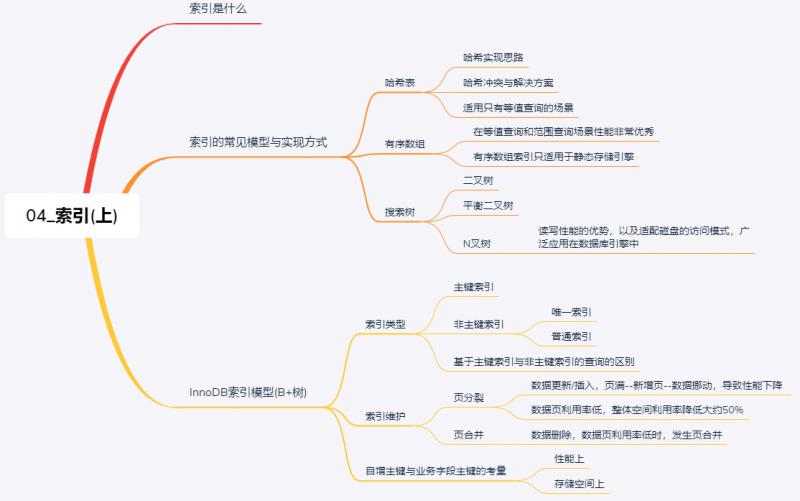
一、什么是索引
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可以快速访问数据库表中的特定信息。
索引的主要目的就是加快检索表中数据,是一种辅助查询的数据结构。
二、索引的模型、实现方式
可以用于提高读写效率的数据结构比较多,三种常见的数据结构:哈希表、有序数组、搜索树。
哈希表
以键值对存储数据的结构。可直接根据待查找的键key,就可以找到其对应的值value。
哈希实现思路 将值存储在数组中,通过一个哈希函数把key计算成数组的一个确定的位置,然后把value放在该位置中,即存储位置=f(key),f 为哈希函数。
哈希冲突 也称为 哈希碰撞 指若是多个key经过哈希函数计算得到同一个值(地址)。
哈希冲突解决方案 主要有:
- 开放定址法——发生冲突时,继续寻找下一块未被占用的存储地址。
- 再散列函数法。
- 链地址法。HashMap即是采用的此方法,即 数组+链表 (单链表)的方式。
适用场景 哈希表适用于只有等值查询的场景,对于区间查询需要全部扫描。
有序数组
适用场景 有序数组在等值查询和范围查询场景中的性能都非常的优秀,但 有序数组索引只适用于静态存储引擎 ,因为更新操作会可能会涉及到移动后面的所有数据记录,成本太高。
搜索树
二叉搜索树 也可以用来做索引的数据模型,查询的时间复杂度为O(log(N)),为了维持这个查询复杂度,则需要保持这颗树是 平衡二叉树 ,为了这个保证,更新的时间复杂度也是O(log(N))。
二叉搜索树 是搜索效率最高的,但是实际上大多数的数据库存储却并不适用二叉树,原因是:索引不止存在内存中,还要写到磁盘上。
为了让一个查询尽量少读磁盘,就必须让查询过程访问尽量少的数据块,这样的话应该适用 N叉树 ,而不是 二叉树 。 N叉树 由于在读写性能上的优点,以及适配磁盘的访问模式,被广泛应用在数据库引擎中了。
三、InnoDB 的索引模型
在MySQL中,索引是在引擎层实现的,所以并没有统一的索引标准,即不同的存储引擎的索引的工作方式不一样。
索引组织表 在InnoDB中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。
InnoDB使用了 B+树索引模型 ,所以数据都是存储在 B+树 中的,每一个索引在InnoDB里面对应一颗 B+树 。
索引类型
主要分为:主键索引、非主键索引(唯一索引、普通索引)。
主键索引 的叶子节点保存整行数据。在InnoDB中,也被称为 聚簇索引 (clustered index)。
非主键索引 的叶子节点内容是主键的值。在InnoDB中,也被称为 二级索引 (secondary index)。
主键索引与普通索引查询区别
-
主键索引查询,只需要搜索主键索引这颗B+Tree。
-
而普通索引查询,则要先搜索普通索引树,得到主键列的值,再到主键索引树搜索一次,这个过程被称为
回表。
综上,基于非主键索引的查询需要多扫描一个索引树,因此在使用中应尽量使用主键查询。
InnoDB索引组织结构示意图如下,其中ID为表主键,k为非主键索引列。
四、索引维护
B+树为了维护索引有序性,在插入新值的时候需要做必要的维护。
页分裂 若是往数据中间插入新的数据,而对应的数据页已满,根据B+树算法,此时需要申请一个新的数据页,然后挪动部分数据过去,此过程称为 页分裂 。
页分裂影响:
- 导致性能下降;
- 影响数据页的利用率,原本可放在一个页的数据被分到两个页中,整体空间利用率降低约50%。
页合并 相邻两个页由于数据删除,利用率很低之后,会将数据页做合并,合并的过程称为 页合并 。
自增主键的适用场景
哪些场景下应该使用自增主键,哪些场景下使用业务字段做主键?(ps:业务字段做主键需保证唯一性)
从 性能 上考虑,自增主键模式,符合递增插入场景,都是追加操作,不涉及数据挪动,也不会触发叶子节点的分裂; 而业务字段做主键的模式,不容易保证有序插入,写数据成本相对较高。
从 存储空间 上考虑,由于每个非主键索引的叶子节点上都是主键的值,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也越小。因此在选择上,要考虑 业务字段 与 自增主键字段 本身的长度。
综上,从性能和存储空间方面考量,自增主键往往是更合理的选择。
业务字段直接做主键的场景
- 只有一个索引;
- 该索引必须是唯一索引。
即在没有其他索引时,也就不用考虑其他索引的叶子节点大小的问题了。
五、小结
参考资料:
本文由博客一文多发平台 OpenWrite 发布!





