
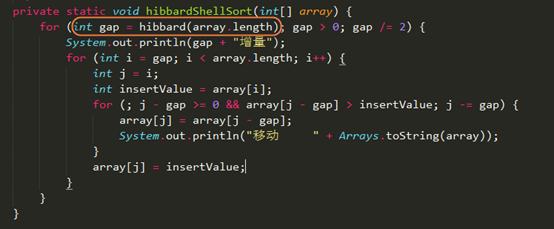
希尔排序属性

上篇写的直接插入排序算法时间复杂度是O(n2),如果要令此排序算法的时间复杂度要低于O(n2),必须是“远距离的元素交换”使得这组元素能提高有序的程度,然后进行直接插入排序的时候可以减少交换的工作量。
那通过什么减少交换的工作量呢?希尔排序可以解决这个问题。
希尔排序在做直接插入排序之前,希望可以对原整个待排序列进行预处理,目的是为了最后一步直接插入排序的时候可以减少交换次数,同时也减少时间上的消耗。
假定数组初始状态:5,1,9,3,7,4,8,6,2
然后设定初始增量是gap = length / 2 = 9 / 2 = 4,意味着两个元素之间比较和交换的距离都是4(隔着3个元素),然后也会被分成4组,【5,7,2】,【1,4】,【9,8】,【3,6】。
对这5组分别进行直接插入排序,在代码的进行中,它们都是穿插的进行直接插入排序,待会在下面视频动画可以看到。
对4组进行完排序的时候接着逐步缩小增量,gap = 4 / 2 = 2,说明两个元素待会比较和交换的距离都是2,被分为两组,对着两组也进行排序。
最后增量缩小为1,这时候就是纯正的直接插入排序了,因为在前面进行了预处理,使得这整个序列进行了“粗略调整”,在做最后一步的直接插入排序的时候,如果待排序列明显有序的话,就真正减少了交换的次数,也真正减少了时间上的消耗。
(在做动画的过程中,中间出错了一个元素交换,已修正,播放的时候中间部分动作会有点赶)。
视频动画:希尔排序交换法
Code
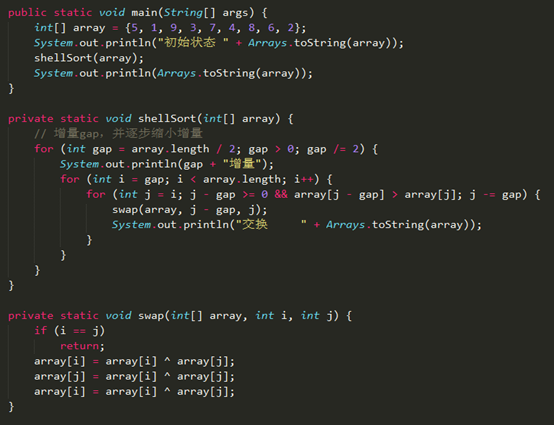
Result
初始状态 [5, 1, 9, 3, 7, 4, 8, 6, 2]
4增量
交换 [5, 1, 8, 3, 7, 4, 9, 6, 2]
交换 [5, 1, 8, 3, 2, 4, 9, 6, 7]
交换 [2, 1, 8, 3, 5, 4, 9, 6, 7]
2增量
交换 [2, 1, 5, 3, 8, 4, 9, 6, 7]
交换 [2, 1, 5, 3, 8, 4, 7, 6, 9]
交换 [2, 1, 5, 3, 7, 4, 8, 6, 9]
1增量
交换 [1, 2, 5, 3, 7, 4, 8, 6, 9]
交换 [1, 2, 3, 5, 7, 4, 8, 6, 9]
交换 [1, 2, 3, 5, 4, 7, 8, 6, 9]
交换 [1, 2, 3, 4, 5, 7, 8, 6, 9]
交换 [1, 2, 3, 4, 5, 7, 6, 8, 9]
交换 [1, 2, 3, 4, 5, 6, 7, 8, 9]
我们为了减少交换的次数,也可以继续优化,采用移动法的方式也可以减少交换的时间消耗。
视频动画:希尔排序移动法
Code

Result
初始状态 [5, 1, 9, 3, 7, 4, 8, 6, 2]
4增量
移动 [5, 1, 9, 3, 7, 4, 9, 6, 2]
移动 [5, 1, 8, 3, 7, 4, 9, 6, 7]
移动 [5, 1, 8, 3, 5, 4, 9, 6, 7]
2增量
移动 [2, 1, 8, 3, 8, 4, 9, 6, 7]
移动 [2, 1, 5, 3, 8, 4, 9, 6, 9]
移动 [2, 1, 5, 3, 8, 4, 8, 6, 9]
1增量
移动 [2, 2, 5, 3, 7, 4, 8, 6, 9]
移动 [1, 2, 5, 5, 7, 4, 8, 6, 9]
移动 [1, 2, 3, 5, 7, 7, 8, 6, 9]
移动 [1, 2, 3, 5, 5, 7, 8, 6, 9]
移动 [1, 2, 3, 4, 5, 7, 8, 8, 9]
移动 [1, 2, 3, 4, 5, 7, 7, 8, 9]
希尔增量(Shell增量序列)
上面的过程使用的{4,2,1}被称为希尔排序的增量,是逐步折半缩小增量的过程。Shell增量序列的递推公式为:
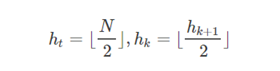
Shell增量序列的最坏时间复杂度为 O(n^2)。
希尔排序的增量序列的选择有很多种,关于那些增量序列的选择证明和过程比较复杂,就不纠结了。本文即将给出两个案例,它们都可能比Shell增量序列要好:Hibbard增量序列和Sedgewick增量序列。
Hibbard增量序列
Hibbard增量序列的通项公式为:
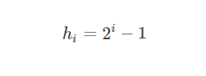
Hibbard增量序列的递推公式为:
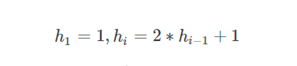
Hibbard 增量序列的最坏时间复杂度为 O(n^(3/2));平均时间复杂度约为 O(n^(5/4))。
Code
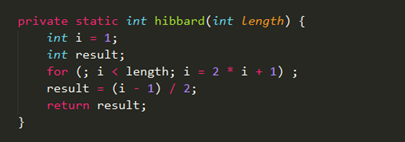
得到的,是比length小的最大初始增量。然后在下面代码中只修改获取初始增量的一步就好了,缩减方式和希尔增量一样的,不做修改。
Sedgewick增量序列
Sedgewick增量序列的通项公式为:
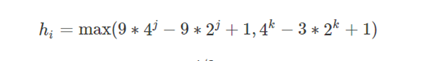
Sedgewick 增量序列的最坏时间复杂度为 O(n^(4/3));平均时间复杂度约为 O(n^(7/6))。
初次看这段公式的时候突然有点看不懂了,仔细看看原来是中间还有个小逗号,意思是这两个增量序列的并查集,拿到比length小的最大值(初始增量)就可以了。
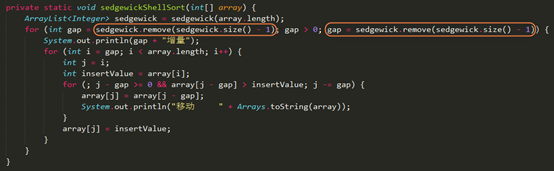
Code
这过程有点复杂,因为存在两段公式的关系,不能直接求得初始增量就可以了,还要考虑到缩小增量的下一个数应该用哪个公式。采用的方式创建动态数组,在while(增量<lenght)条件下不断的加入新的元素作为增量,直到比length大才作罢,还要去除掉最有一个已经比length大的增量。
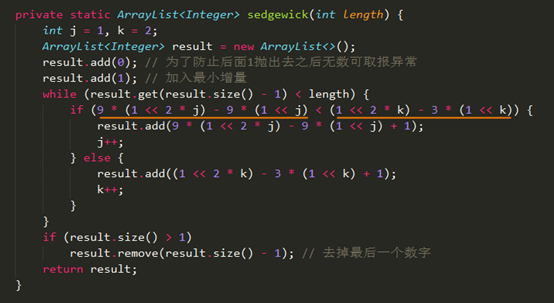
上面解释一下“<<”的运算符,它是转化成二进制然后左移几位的算法,例如9<<1,9转化成二进制1001,然后左移一位,后面补零得10010,转化为十进制就是18,相当于9*2=18。
再例如7<<2,7转化为二进制111,左移两位成11100,转化为十进制就是32,相当于7*(2^2)=32。
”>>”运算符也是同样的,相当于除以2的几次方。
下面代码获取初始增量的也要修改,增量缩减方式也要相应的修改,然后其它的代码不变。
本文介绍了希尔排序的基本思想、优化以及代码的实现,包括后面两个增量序列的选择。增列序列的选择方式对希尔排序也很重要,直接影响到希尔排序的性能。





