
大家好我是小蕉。
今天跟大家分享一下Spark的运行机制以及运行模式。
从运行机制来看,长下面这样子。
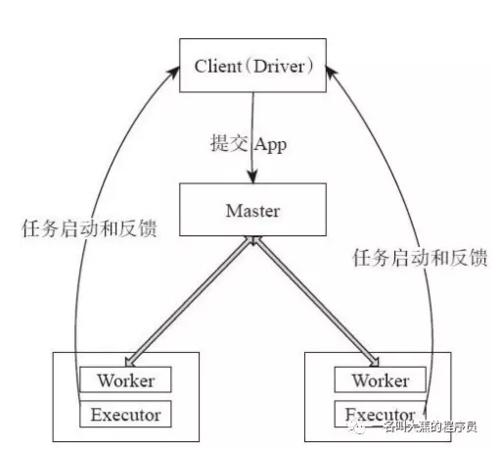
Spark任务由Driver提交Application给Master,然后由Master将Application切分成多个JOB,然后调度DAG Scheduler将Task切分成多个stage,分配给多个Worker,每个Work接收到TaskSet任务集后,将调度Executor们进行任务分配,每个Executor都有自己的DataSet用于计算。通讯是使用akka。
Driver会记录所有stage的信息。
要是stage切分过多,那占用Driver的内存会非常多。
若task运行的stage失败,默认会进行4次重试,若4次重试全部失败,SparkContext会停止所有工作。
Driver也会记录stage的运行时间,如果task运行的stage时间太久,Driver可能会认为这个job可能失败了,会重新分配一个task给另外一个Executor,两个task都会同时跑,谁先跑完谁交差,另外一个只有被干掉的份。
从运行模式来看,Spark有这么几种方式可以运行。
local
mesos
standalone
yarn-client
yarn-cluster
下面一个一个来解剖它们。
local,顾名思义,是跑在本地的,指将Driver和Executor都运行在提交任务的机器上。 local[2] 代表启动两个线程来跑任务, local[*]代表启动任意数量需要的线程来跑Spark任务。
Mesos是Apache下的开源分布式资源管理框架,它被称为是分布式系统的内核。Mesos最初是由加州大学伯克利分校的AMPLab开发的,后在Twitter得到广泛使用。
Spark on mesos,是指跑在mesos平台上。目前有两个模式可以选择,粗粒度模式(CoarseMesosSchedulerBackend)和细粒度模式(MesosSchedulerBackend)。粗粒度模式下,Spark任务在指定资源的时候,所分配的资源将会被锁定,其他应用无法share。在细粒度模式下,Spark启动时Secheduler只会分配给当前需要的资源,类似云的想法,不会对资源进行锁定。
Spark on standalone,是指跑在Spark集群上。Spark集群可以自成一个平台,资源由Spark来管理,不借助任何外部资源,若在测试阶段可以考虑使用这种模式,比较高效,但是在生产环境若有多个任务,不太建议使用这种方式。
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
Spark on yarn,是指跑在Hadoop集群上。Hadoop提供的yarn是一个比较好的资源管理平台,若项目中已经有使用Hadoop相关的组件,建议优先使用yarn来进行资源管理。
将Spark任务提交到yarn上同样有两个模式,一种是yarn-client,一种是yarn-cluster。
yarn-client将SparkContext运行在本地,Driver也运行在本地,这种模式一般不推荐,因为在分配Driver资源的时候,提交的机器往往并不能满足。
yarn-cluster,将任务提交到Hadoop集群上,由yarn来决定Driver应该跑在哪个机器,SparkContext也会运行在被分配的机器上,建议使用这种模式。
无论是yarn-client还是yarn-cluster,都是在yarn平台的管理下完成,而Spark on yarn目前只支持粗粒度方式(Hadoop2.6.0),所以在任务多,资源需求大的情况下,可能需要扩大Hadoop集群避免资源抢占。




