
1 简介
hbase 提供很方便的shell脚本以及java API等方式对Hbase进行操作,但是对于很对已经习惯了关系型数据库操作的开发来说,有一定的学习成本,如果可以像操作mysql等一样通过sql实现对Hbase的操作,那么很大程度降低了Hbase的使用成本。Apache Phoenix 组件就完成了这种需求,官方注解为 “Phoenix -we put the SQL back in NoSql”,通过官方说明,Phoenix 的性能很高,相对于 hbase 原生的scan 并不会差多少,而对于类似的组件 hive、Impala等,性能有着显著的提升,详细请阅读https://phoenix.apache.org/performance.html。
Apache Phoenix 官方站点:https://phoenix.apache.org/
Phoenix支持的sql语句: https://phoenix.apache.org/language/index.html
Phoenix 支持的DataTypes:https://phoenix.apache.org/language/datatypes.html
Phoenix 支持的函数:https://phoenix.apache.org/language/functions.html
2 安装配置
2.1 环境说明
Hbase使用两台主机,主机名和IP分别为:
master 172.18.68.119
slave01 172.18.68.88
master作为主节点,slave01作为从节点,即作为Hbase的HRegionServer。
hbase的安装位置:/home/hadoop/hbase
2.2 下载
在官网http://www.apache.org/dyn/closer.lua/phoenix/中选择提供的镜像站点中下载与安装的HBase版本对应的版本。本地使用的1.3.1,故下载的apache-phoenix-4.11.0-HBase-1.3/的tar.gz包。

2.3 安装配置
2.3.1 上传phoenix到master
使用secureCRT或者其他传输工具将下载的tar包上传到hbase集群的master结点中。
$cd /home/hadoop/
$mkdir phoenix
$cd phoenix
$rz
$tar -zxvf apache-phoenix-4.11.0-HBase-1.3-bin.tar.gz
$mv apache-phoenix-4.11.0-HBase-1.3-bin/ phoenix
2.3.2 拷贝phoenix-core-4.11.0-HBase-1.3.jar到RegionServer
将phoenix-core-4.11.0-HBase-1.3.jar拷贝到hbase集群中的所有region server的hbase的lib目录下。在测试环境下,master和slave01均作为regionserver。
$cd /home/hadoop/phoenix/phoenix
$cp phoenix-core-4.11.0-HBase-1.3.jar /home/hadoop/hbase/lib 拷贝到master
$scp -r phoenix-core-4.11.0-HBase-1.3.jarhadoop@172.18.68.88:/home/hadoop/hbase/lib 拷贝到slave01
2.3.3 重启hbase
$cd /home/hadoop/hbase/bin
$./stop-hbase.sh
$./start-hbase.sh
3 phoenix命令行使用
3.1 进入命令行
$cd /home/hadoop/phoenix/phoenix/bin进入phoenix的bin目录
$./sqlline.py master 其中的master为Zookeeper所在节点的主机名
3.2 sqlline.py执行sql脚本
可以使用sqlline.py命令执行sql脚本文件,如下:
$ cd/home/hadoop/phoenix/phoenix
$ bin/sqlline.py masterexamples/STOCK_SYMBOL.sql
STOCK_SYMBOL.sql文件内容如下:
| CREATE TABLE IF NOT EXISTS STOCK_SYMBOL (SYMBOL VARCHAR NOT NULL PRIMARY KEY, COMPANY VARCHAR);UPSERT INTO STOCK_SYMBOL VALUES ('CRM','SalesForce.com');SELECT * FROM STOCK_SYMBOL; |
3.3 psql.py执行sql脚本
可以通过phoenix的bin目录下的psql.py脚本加载CSV数据或者执行包含sql脚本的文件,如下:
$cd /home/hadoop/phoenix/phoenix
$bin/psql.py master ../examples/WEB_STAT.sql ../examples/WEB_STAT.csv ../examples/WEB_STAT_QUERIES.sql
其中WEB_STAT.sql、WEB_STAT.csv、WEB_STAT_ QUERIES.sql是phoenix提供的samples下的文件,文件内容如下:
WEB_STAT.sql 为创建表的sql脚本文件
| CREATE TABLE IF NOT EXISTS WEB_STAT ( HOST CHAR(2) NOT NULL, DOMAIN VARCHAR NOT NULL, FEATURE VARCHAR NOT NULL, DATE DATE NOT NULL, USAGE.CORE BIGINT, USAGE.DB BIGINT, STATS.ACTIVE_VISITOR INTEGER CONSTRAINT PK PRIMARY KEY (HOST, DOMAIN, FEATURE, DATE)); DATE DATE NOT NULL, USAGE.CORE BIGINT, USAGE.DB BIGINT, STATS.ACTIVE_VISITOR INTEGER CONSTRAINT PK PRIMARY KEY (HOST, DOMAIN, FEATURE, DATE)); |
WEB_STAT.csv 为数据文件
| NA,Salesforce.com,Login,2013-01-01 01:01:01,35,42,10EU,Salesforce.com,Reports,2013-01-02 12:02:01,25,11,2EU,Salesforce.com,Reports,2013-01-02 14:32:01,125,131,42NA,Apple.com,Login,2013-01-01 01:01:01,35,22,40NA,Salesforce.com,Dashboard,2013-01-03 11:01:01,88,66,44NA,Salesforce.com,Login,2013-01-04 06:01:21,3,52,1EU,Apple.com,Mac,2013-01-01 01:01:01,35,22,34NA,Salesforce.com,Login,2013-01-04 11:01:11,23,56,45EU,Salesforce.com,Reports,2013-01-05 03:11:12,75,22,3EU,Salesforce.com,Dashboard,2013-01-06 05:04:05,12,22,43 ... |
WEB_STAT_ QUERIES.sql为查询脚本文件
| SELECT DOMAIN, AVG(CORE) Average_CPU_Usage, AVG(DB) Average_DB_UsageFROM WEB_STATGROUP BY DOMAINORDER BY DOMAIN DESC; -- Sum, Min and Max CPU usage by Salesforce grouped by daySELECT TRUNC(DATE,'DAY') DAY, SUM(CORE) TOTAL_CPU_Usage, MIN(CORE) MIN_CPU_Usage, MAX(CORE) MAX_CPU_UsageFROM WEB_STATWHERE DOMAIN LIKE 'Salesforce%'GROUP BY TRUNC(DATE,'DAY'); -- list host and total active users when core CPU usage is 10X greater than DB usageSELECT HOST, SUM(ACTIVE_VISITOR) TOTAL_ACTIVE_VISITORSFROM WEB_STATWHERE DB > (CORE * 10)GROUP BY HOST; |
3.4 phoenix表操作
3.4.1 创建表
CREATE TABLE IF NOT EXISTS us_population (
stateCHAR(2) NOT NULL,
cityVARCHAR NOT NULL,
populationBIGINT
CONSTRAINTmy_pk PRIMARY KEY (state, city));
在phoenix中,默认情况下,表名等会自动转换为大写,若要小写,使用双引号,如"us_population"。
3.4.2 显示所有表
!table或
!tables
3.4.3 插入记录
upsert into us_population values('NY','NewYork',8143197);
3.4.4 查询记录
select * from us_population ;
select * from us_population wherestate='NY';
3.4.5 删除记录
delete from us_population wherestate='NY';
3.4.6 删除表
drop table us_population;
3.4.7 退出命令行
!quit
具体语法参照官网
https://phoenix.apache.org/language/index.html#upsert_select
3.5 phoenix表映射
默认情况下,直接在hbase中创建的表,通过phoenix是查看不到的,如图1和图2,US_POPULATION是在phoenix中直接创建的,而test是在hbase中直接创建的,默认情况下,在phoenix中是查看不到test的。

图1 phoenix命令行中查看所有表
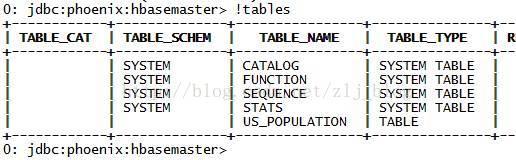
图2 hbase命令行中查看所有表
如果需要在phoenix中操作直接在hbase中创建的表,则需要在phoenix中进行表的映射。映射方式有两种:视图映射和表映射。
hbase 中test的表结构如下,两个列簇name、company.
Rowkey | name | company | ||
empid | firstname | lastname | name | address |
3.5.1 hbase命令行中创建表
$ cd /home/hadoop/hbase/bin
$ ./hbase shell 进入hbase命令行
create 'test','name','company' 创建表,如下图

下面的视图映射和表映射均基于该表。
3.5.2 视图映射
Phoenix创建的视图是只读的,所以只能用来做查询,无法通过视图对源数据进行修改等操作。而且相比于直接创建映射表,视图的查询效率会低,原因是:创建映射表的时候,Phoenix会在表中创建一些空的键值对,这些空键值对的存在可以用来提高查询效率。
1)创建视图
create view"test"(empid varchar primarykey,"name"."firstname" varchar,"name"."lastname"varchar,"company"."name" varchar,"company"."address"varchar);
2)删除视图
drop view "test";
3.5.3 表映射
使用Apache Phoenix创建对HBase的表映射,有两种方法:
1) 当HBase中已经存在表时,可以以类似创建视图的方式创建关联表,只需要将create view改为create table即可。
2)当HBase中不存在表时,可以直接使用create table指令创建需要的表,并且在创建指令中可以根据需要对HBase表结构进行显示的说明。
第1)种情况下,如在之前的基础上已经存在了test表,则表映射的语句如下:
create table "test"(empid varchar primarykey,"name"."firstname"varchar,"name"."lastname"varchar,"company"."name" varchar,"company"."address"varchar);
第2)种情况下,直接使用与第1)种情况一样的create table语句进行创建即可,这样系统将会自动在Phoenix和HBase中创建person_infomation的表,并会根据指令内的参数对表结构进行初始化。
使用create table创建的关联表,如果对表进行了修改,源数据也会改变,同时如果关联表被删除,源表也会被删除。但是视图就不会,如果删除视图,源数据不会发生改变。
4 SQuirrel使用
如果希望通过客户端以图形化的界面操作Phoenix的话,可以下载并安装SQuirrel。
SQuirrel SQL Client是一个用Java写的数据库客户端,可以通过一个统一的用户界面来操作MySQL 、PostgreSQL 、MSSQL、 Oracle等任何支持JDBC访问的数据库。使用起来非常方便。
SQuirrel下载页面:http://squirrel-sql.sourceforge.net/#installation。
SQuirrel的安装步骤(参考https://phoenix.apache.org/installation.html):
1)移除SQuirrel的lib文件夹下的phoenix-[oldversion]-client.jar(如果有的话),然后拷贝phoenix-[newversion]-client.jar到SQuirrel的lib文件夹下,phoenix-[newversion]-client.jar须与欲连接的hbase的lib下的phoenix版本一致。
2)windows下,运行squirrel-sql.bat启动SQuirrel,在启动界面下,切换到Drivers选项卡,点击+号添加新的驱动。
3)在添加驱动对话框中,设置name为Phoenix,设置Example URL为 jdbc:phoenix:localhost,其中的localhost为hbase使用的Zookeeper主机名。
4)设置Class Name文本框的内容为 “org.apache.phoenix.jdbc.PhoenixDriver”, 如图4.1,然后点击“OK”关闭。
5)切换到Aliases选项卡,点击+新建一个alias。
6)在对话框中,name:任何名称,Driver:选择phoenix,username、password可省略,或者填任意值均可。
7)URL的内容为:jdbc:phoenix: zookeeperquorum server,例如,要连接本机的hbase,URL为:jdbc:phoenix:localhost,如图4.2。
8)点击Test,在新对话框中选择connect,如果一切设置正确的话,应该连接成功,然后点击OK关闭对话框。
9)双击新建的phoenix alias,点击connect,然后就可以通过phoenix的sql语句操作hbase了,如图4.3。
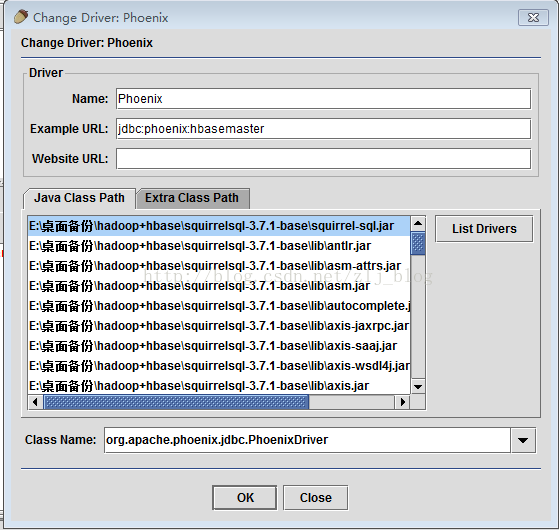
图4.1 新建Driver

图4.2 新建Alias
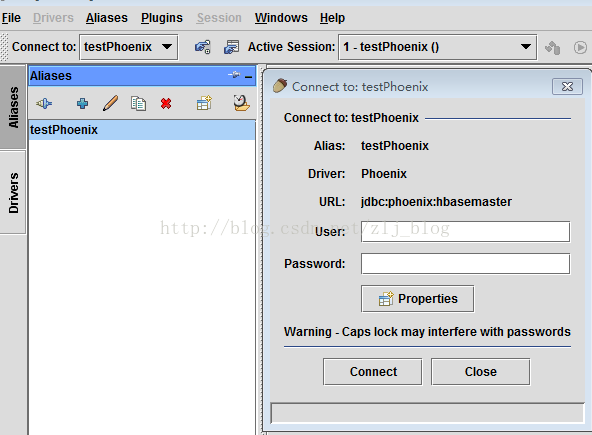
图 4.3 建立连接




