
本文口味:番茄炒蛋,预计阅读:10分钟。
博客又停更了两个月,在这期间,对人生和世界多了许多思考。在人生的不同阶段,会对生活和世界有着不一样的认知,而认知的改变也会直接反应在行为模式之中。
对于生活的思考心得也会在之后的时间里,慢慢分享给大家,一方面是对自己心路历程的记录和总结,另一方面也希望能给遇到同样问题或疑惑的朋友以帮助。目前生活已经慢慢调整到我想要的样子,博客写作也该继续起航了。
一、说明
Mysql是最常用的关系型数据库,而索引则是Mysql调优中最关心的部分,设计一个好的索引并写出合适的sql,就能将查询速度大大提升。从本篇开始,将会对Mysql中的索引进行深入浅出的介绍,从索引的简介、类别、使用姿势到索引的原理,最后到索引实战。希望通过本系列的文章,能让你对mysql中的索引有一个更深入的认识。
以下是本文大纲:
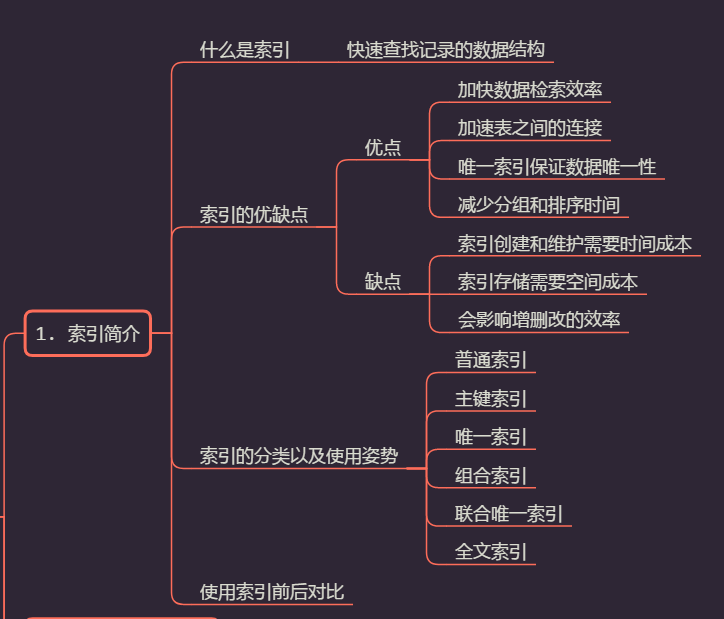
二、什么是索引
索引是存储引擎用于快速查找记录的一种数据结构。
emm,用人话说,如果把Mysql比作一本书的话,索引就是书的目录,根据目录便能很快找到需要的信息所在的页面,如果没有目录的话,想要查找想要的信息就只能一页一页翻了。
比如下面这样一条简单的sql:
SELECT id,name,course,grade FROM t_grade WHERE name = 'Frank';
如果没有添加索引的话,只能从最小记录开始依次遍历mysql中的记录,然后对比每条记录是否符合搜索条件。如果表中的数据量不大(十万级别以下),耗时其实也还好,毕竟目前来说,CPU效率已经很高了。但这样其实是对CPU的一种浪费,就好比开着跑车在泥泞的乡村小路上驾驶,完全无法发挥它应有的性能。而索引便是这样一条康庄大道,有了索引,才能充分发挥mysql引擎的性能,让你的sql跑车风驰电掣。
三、索引的优缺点
对于大部分事物而言,通常存在其对立面的,有好的一面,就会有坏的一面,就像质量好的东西通常价格高,便宜的东西通常质量差,索引也是如此。
使用索引的优点显而易见:
- 可以大大加快数据检索效率。
- 可以加速表与表之间的连接。
- 可以通过唯一索引的创建,保证数据的唯一性。
- 可以显著减少分组与排序的时间。
总而言之,用一个字来总结,就是快。
使用索引的缺点也是需要考虑的:
- 索引的创建和维护需要时间成本。表中的数据量越大,插入或删除数据时,调整索引所需要的时间就越长。
- 索引需要单独存储,占用磁盘空间,如果设置了大量的索引,占用的空间甚至比记录本身更大。
- 在对数据进行增、删、改时,需要同时更新索引中的数据,因此会影响增删改的速度。
所以使用索引并不是百利而无一害,使用不当甚至可能造成删库跑路的惨剧【手动滑稽】。但当你了解它的原理,掌握了索引的真谛,它就会成为你的神兵利器,让你在mysql开发中所向披靡。
四、索引的分类以及创建姿势
索引可分为普通索引、唯一索引、主键索引、组合索引、全文索引。看起来好像很多很复杂,但其实并非如此,且听我慢慢道来。
普通索引,名字中就透露出它普通的气质,也就是最常见的索引。
如何创建一个普通索引呢?其实很简单,如果是在DDL中创建索引,可以这样使用:
CREATE TABLE `t_grade` (
id BIGINT(20) COMMENT '主键id',
name VARCHAR(30) COMMENT '姓名',
course INT COMMENT '课程,1-语文,2-数学,3-英语,4-物理',
grade DECIMAL(5,2) COMMENT '成绩',
KEY idx_name(`name`)
)ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
这样就为"name"列创建了一个名为"idx_name"的普通索引。通用的创建方式为:
KEY 索引名 (`列名`)
如果是为一张已经创建好的表添加一个普通索引,那么可以这样:
ALTER TABLE `t_grade` ADD KEY idx_name(`name`);
你可能会说,“不是用index关键字来创建索引的吗”,别急别急,其实它们的效果是一样的。
主键索引,一看就是很关键的角色,没错,每张表都会有且只有一个主键索引,即使没有显式的创建主键索引的话,也会自动创建一个隐藏的主键索引。
这么重要的索引,用的关键字肯定也得不一样才行,创建主键索引的关键字是PRIMARY KEY,在DDL中添加主键索引的姿势为:
CREATE TABLE `t_grade` (
id BIGINT(20) COMMENT '主键id',
name VARCHAR(30) COMMENT '姓名',
course INT COMMENT '课程,1-语文,2-数学,3-英语,4-物理',
grade DECIMAL(5,2) COMMENT '成绩',
PRIMARY KEY (`id`)
)ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
因为主键只能有一个,所以不需要添加主键名。通用的添加方式为:
PRIMARY KEY (`列名`)
如果是为已创建好的表添加主键索引,那么可以这样:
ALTER TABLE `t_grade` ADD PRIMARY KEY (`id`);
唯一索引,顾名思义,就是“唯一”的索引,被添加到索引中的列的值必须是唯一的,如果向数据表中插入一条已存在的唯一索引字段记录,就会报错。
定义唯一索引的关键字为 UNIQUE KEY。在DDL中添加唯一索引的姿势为:
CREATE TABLE `t_grade` (
id BIGINT(20) COMMENT '主键id',
name VARCHAR(30) COMMENT '姓名',
course INT COMMENT '课程,1-语文,2-数学,3-英语,4-物理',
grade DECIMAL(5,2) COMMENT '成绩',
UNIQUE KEY uk_name (`name`)
)ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
唯一索引的通用添加方式为:
UNIQUE KEY 索引名 (`列名`)
为已创建好的表添加唯一索引:
ALTER TABLE `t_grade` ADD UNIQUE KEY uk_name (`name`);
组合索引,又叫联合索引,便是将两个或者多个字段组合在一起的索引,好像跟没说一样= =
看一个栗子就知道了。
CREATE TABLE `t_grade` (
id BIGINT(20) COMMENT '主键id',
name VARCHAR(30) COMMENT '姓名',
course INT COMMENT '课程,1-语文,2-数学,3-英语,4-物理',
grade DECIMAL(5,2) COMMENT '成绩',
KEY idx_name_corse (`name`,`course`)
)ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
同样是使用key关键字,在索引名后添加多个字段名即可。这里有一点需要注意的是,字段排列是有顺序的。举例说明,下面这两个索引是不一样的:
ALTER TABLE `t_grade` ADD KEY idx_name_course (`name`,`course`);
ALTER TABLE `t_grade` ADD KEY idx_name_course (`course`,`name`);
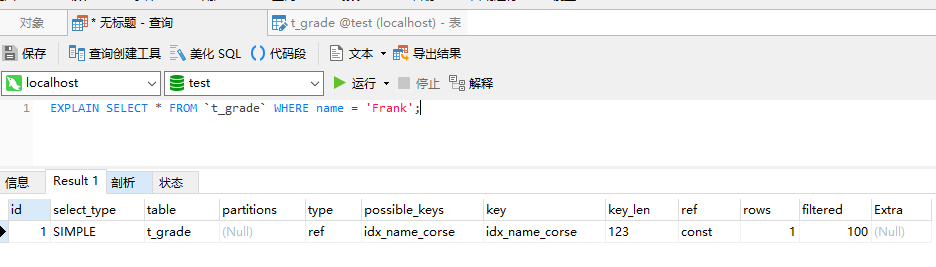
索引的匹配遵循“左缀匹配原则”,举个栗子说明,如果创建的组合索引是
ALTER TABLE `t_grade` ADD KEY idx_name_course (`name`,`course`);
那么下面语句将能命中这个组合索引。
SELECT * FROM `t_grade` WHERE name = 'Frank';
而下面这个语句将无法命中索引:
SELECT * FROM `t_grade` WHERE course = 1;
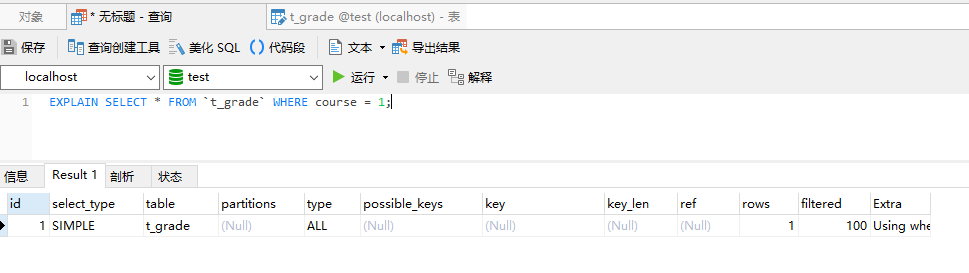
因为在组合索引中,索引中的记录是先按照前一个字段排序,然后再根据后一个字段排序的,所以如果直接使用组合索引中的第二个字段查询时,查询索引对索引记录进行遍历,遍历完成之后还需要回溯到聚簇索引中获取完整记录,这样反而更耗时间,所以sql优化器会选择直接对记录进行遍历。
如果你还不清楚索引的结构以及聚簇索引是什么,不要着急,后面的文章里会有详细的介绍。
联合唯一索引,便是将多个字段组合起来形成一个唯一键,举个栗子:
先删除所有索引,然后添加两条记录:
INSERT INTO `t_grade` (`id`, `name`, `course`, `grade`) VALUES(1, 'Frank', 1, 100);
INSERT INTO `t_grade` (`id`, `name`, `course`, `grade`) VALUES(2, 'Frank', 1, 95);
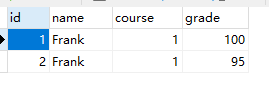
这样就能插入两条记录了。
然后删掉这两条记录,创建一个联合唯一索引:
ALTER TABLE `t_grade` ADD UNIQUE KEY idx_name_course (`name`,`course`);
然后再来执行一下上面的sql:
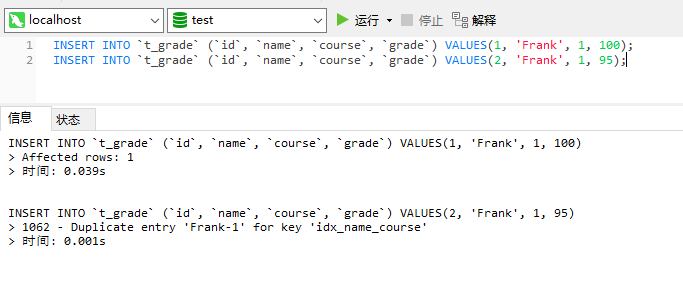
这时候,就会得到一个错误提示,因为将字段name和course创建了联合唯一索引,所以这两个字段的组合值必须是唯一的,如果要插入的记录的这两个字段组合值已经存在,那么就会抛出异常。
最后一个是比较复杂的索引:全文索引,由于其复杂性,这里只简单的介绍它的创建姿势。
CREATE TABLE `t_article`(
id BIGINT COMMENT '文章id',
title VARCHAR(200) COMMENT '文章标题',
content TEXT COMMENT '文章内容',
FULLTEXT (title, content)
)ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
或者给现有表添加全文索引:
ALTER TABLE `t_article` ADD FULLTEXT KEY fidx_title_content (title,content) WITH PARSER ngram;
想要使用全文索引查询,则需要使用MATCH关键字。
SELECT * FROM `t_article` WHERE MATCH(title, content) AGAINST('查询字符串');
当然,如果想要使用全文索引,需要确认mysql的版本号在5.7以上,否则无法在innodb引擎上使用全文索引的中文检索插件ngram。
五、索引使用前后对比
为了更直观的看出索引的优缺点,我们可以来对数据表添加索引前后执行相同sql的耗时来看出对比,这里仅进行简单的比较,没有使用性能测试。
先来创建一个数据表:
CREATE TABLE `t_grade` (
id BIGINT(20) COMMENT '主键id',
name VARCHAR(30) COMMENT '姓名',
course INT COMMENT '课程,0-化学,1-语文,2-数学,3-英语,4-物理',
grade DECIMAL(5,2) COMMENT '成绩'
)ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8;
然后插入一百万条数据:
public void batchInsert(){
long timeMillis = System.currentTimeMillis();
System.out.println("开始插入数据");
for (int i = 1; i < 1000000; i++) {
GradeDO gradeDO = new GradeDO((long) i, randomName(), random.nextInt(5), BigDecimal.valueOf(random.nextDouble() * 100));
gradeMapper.insert(gradeDO);
}
System.out.println("插入一百万条记录耗时:" + ( System.currentTimeMillis() - timeMillis) / 1000.0 );
}
输出如下:
开始插入数据
插入一百万条记录耗时:1507.102
现在是没有索引的状态,开始进行插入测试:
public void batchInsert(){
long timeMillis = System.currentTimeMillis();
System.out.println("开始插入数据");
for (int i = 1000000; i < 1010000; i++) {
GradeDO gradeDO = new GradeDO((long) i, randomName(), random.nextInt(5), BigDecimal.valueOf(random.nextDouble() * 100));
gradeMapper.insert(gradeDO);
}
System.out.println("插入一万条记录耗时:" + ( System.currentTimeMillis() - timeMillis) / 1000.0 );
}
输出如下:
开始插入数据
插入一万条记录耗时:15.681
然后进行查询测试。
@Test
void testQuery() {
long timeMillis = System.currentTimeMillis();
System.out.println("开始查询");
for (int i = 0; i < 100; i++) {
Integer id = random.nextInt(1000000);
GradeDO gradeDO = gradeMapper.selectById(id);
}
System.out.println("一百次查询耗时:" + ( System.currentTimeMillis() - timeMillis) / 1000.0 );
}
输出如下:
开始查询
一百次查询耗时:51.658
接下来,为id列创建一个主键,并为name字段创建一个普通索引。
再插入一万条记录:
开始插入数据
插入一万条记录耗时:17.465
然后进行查询测试。
开始查询
一百次查询耗时:0.191
可以看出,在有单个索引的情况下,创建记录耗时略长于无索引的情况,当字段数量和索引数量增加时,这种差距将会增大。查询效率可以清晰的看出,这里添加了索引之后,大大的缩减了查询的耗时,当然,这里主要是聚簇索引的功劳。
六、总结
索引是mysql中十分重要的一个特性,使用好它就能让你的sql如虎添翼。简单来说,索引一方面可以大大提升查询性能,另一方面也会占用时间和空间成本,因此索引的选择也是一门学问。索引有很多种类型,不同类型的索引有着不同的特性,因此只有了解了它们各自的特性才能正确使用它们。
关于索引的简介就先介绍到这里了,后面会对索引的原理进行进一步深入的介绍,让你不仅知道怎么使用索引,而且还能知道为什么要这样使用索引。




