
爱写bug(ID:iCodeBugs)
前言:
围观几个知乎话题:
点开一个问题看一下答主的回答:

可是这每个话题下都有上千条回答,这得看到啥时候,不停的刷新也得很久。。。于是就写了这段代码把这些图片都下载了,考虑到一些数据可能用到,就顺道一起存到数据库了。包括图片地址、答主主页地址、答主昵称、答主、个性签名、答主粉丝、相关问题地址、赞同数等等等。看成果图: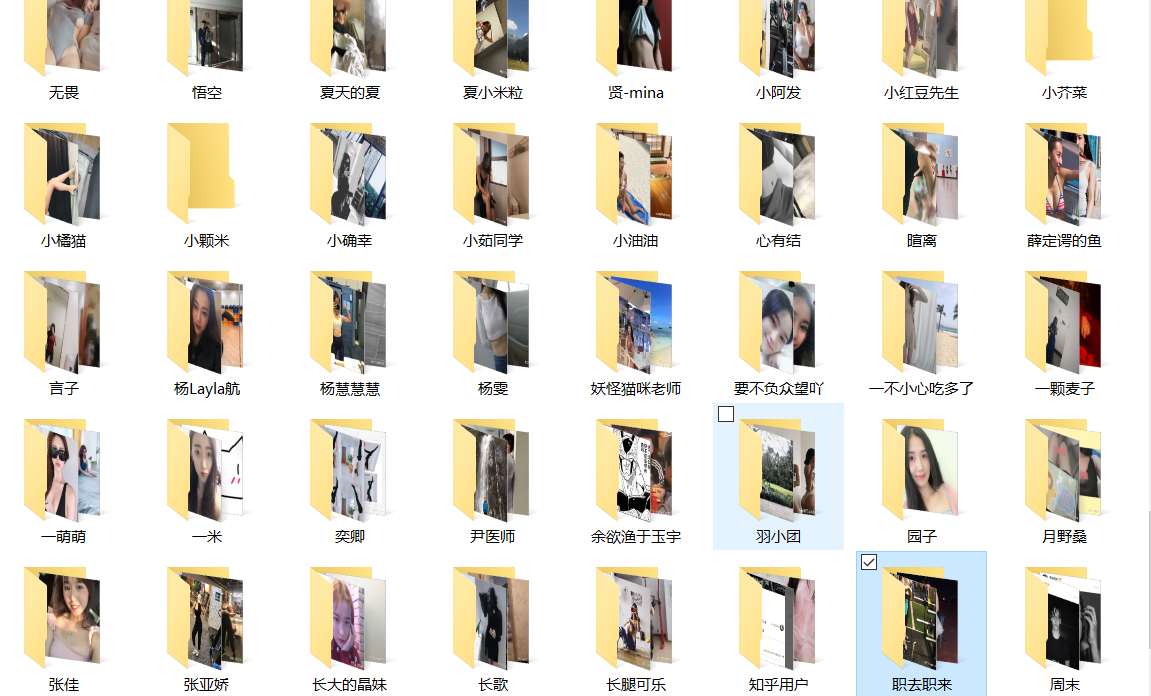

尊重答主的分享,所以 以每一位答主昵称来命名其图片的父目录文件夹。但是最后浏览图片一个一个文件夹太麻烦了,所以我统一整理了一下一共 三个话题下2325张图片放在一个文件夹里,想直接观摩一下的同学公众号后台回复:知乎,压缩包合集发给你(一个月内有效),下面是讲获取的方法,只对图片感兴趣的不用看了,去回复吧。
言归正传:
点开一个话题,进入开发者工具,刷新页面,在xhr栏目下,会发现很多请求,左上角过滤一下,只有以 answers? 开头的才是回答内容,分析一下请求头:
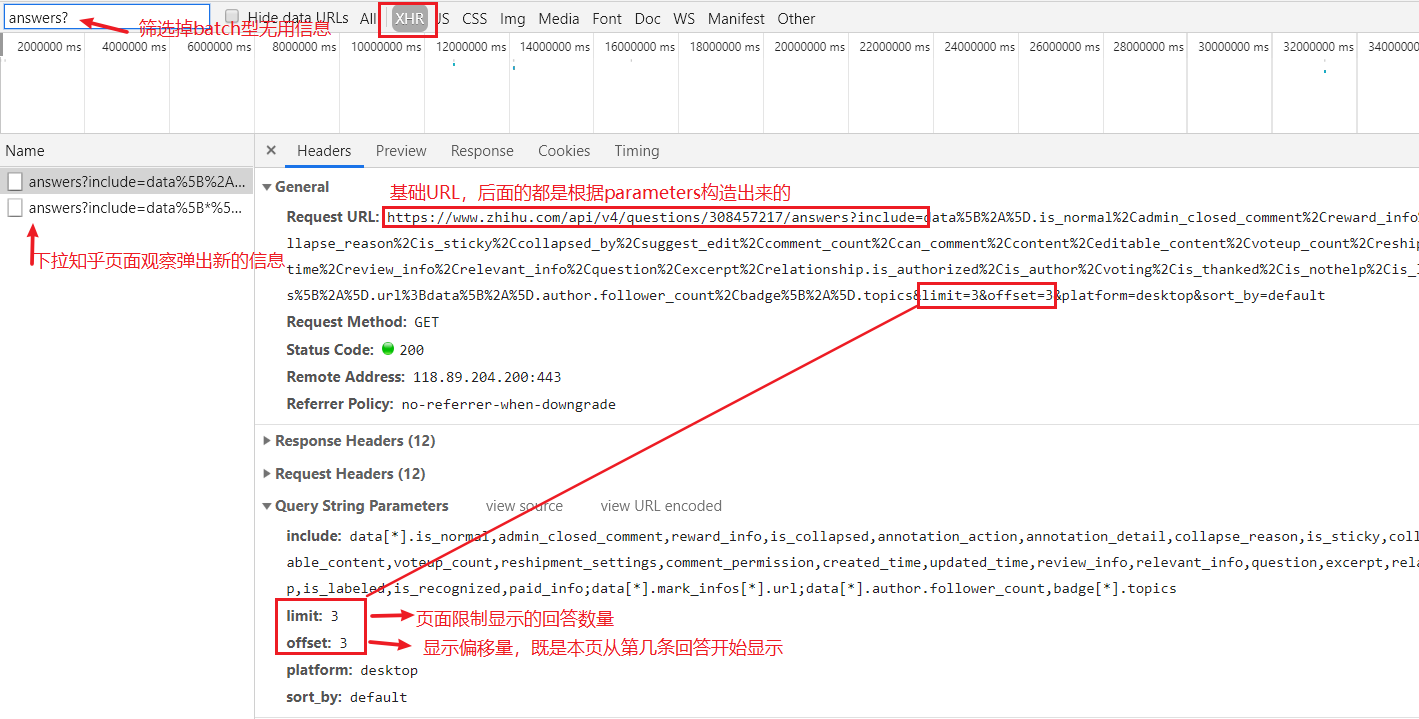
知乎的请求结构出奇的简单,很意外。关键信息已在图片标明。基础URL是:https://www.zhihu.com/api/v4/questions/313825759/answers?include= 后面全都是根据 Query String Parameters 构造出来的。
然后我们看一下答主的回答内容:
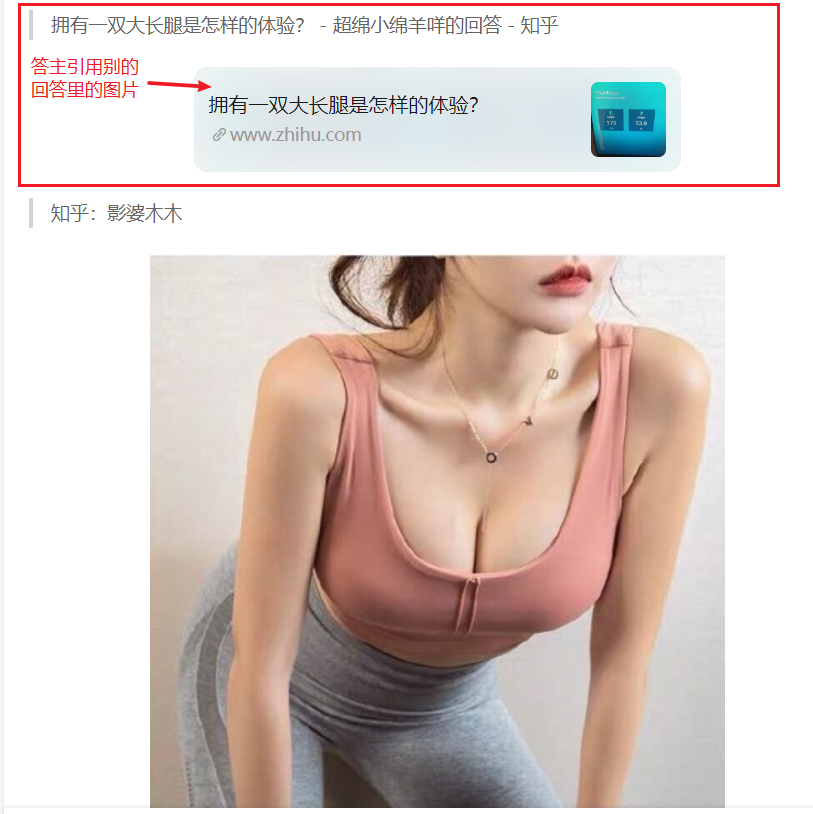
这里回答内容有可能是引用其他话题 拥有一双大长腿是怎样的体验? 的图片,也就是说,我们只要再把这个引用的话题地址获取下来,再根据新获取的地址构造请求URL, 得到该话题的请求地址,这样就可以顺着一条回答把所有引用的相似问题其他答主的图片全部下载下来。。。
点击引用的其他话题,切换知乎话题 拥有一双大长腿是怎样的体验? ,我们再看一下回答内容:

同样看一下该话题的 Query String Parameters 只有 limit 、offset两个属性会变,而limit 为限制当页显示的回答数量,offset 为偏移量,就是本页从第几条回答开始显示,其他属性全是相同的(知乎页面限制显示回答数最大20)。这意味着不管知乎哪个问题都可由该问题的地址以相同的方法构造请求URL:
param = {
'include': '',#太长了,不展示了
'limit': '20', # 限制当页显示的回答数,知乎最大20
'offset': offset, # 偏移量
'platform': 'desktop',
'sort_by': 'default',
}
base_URL = 'https://www.zhihu.com/api/v4/questions/297715922/answers?include=' # 基础 url 用来构造请求url
url = base_URL + urllib.parse.urlencode(param) # 构造请求地址
再点击 preview 看返回的 json 格式的信息:
有个totals,是该话题下总回答数,可以根据这个计算多少次可以遍历全部回答,考虑到后面回答内容质量就跟不上了,我们只获取前800条回答。
展开一条回答:
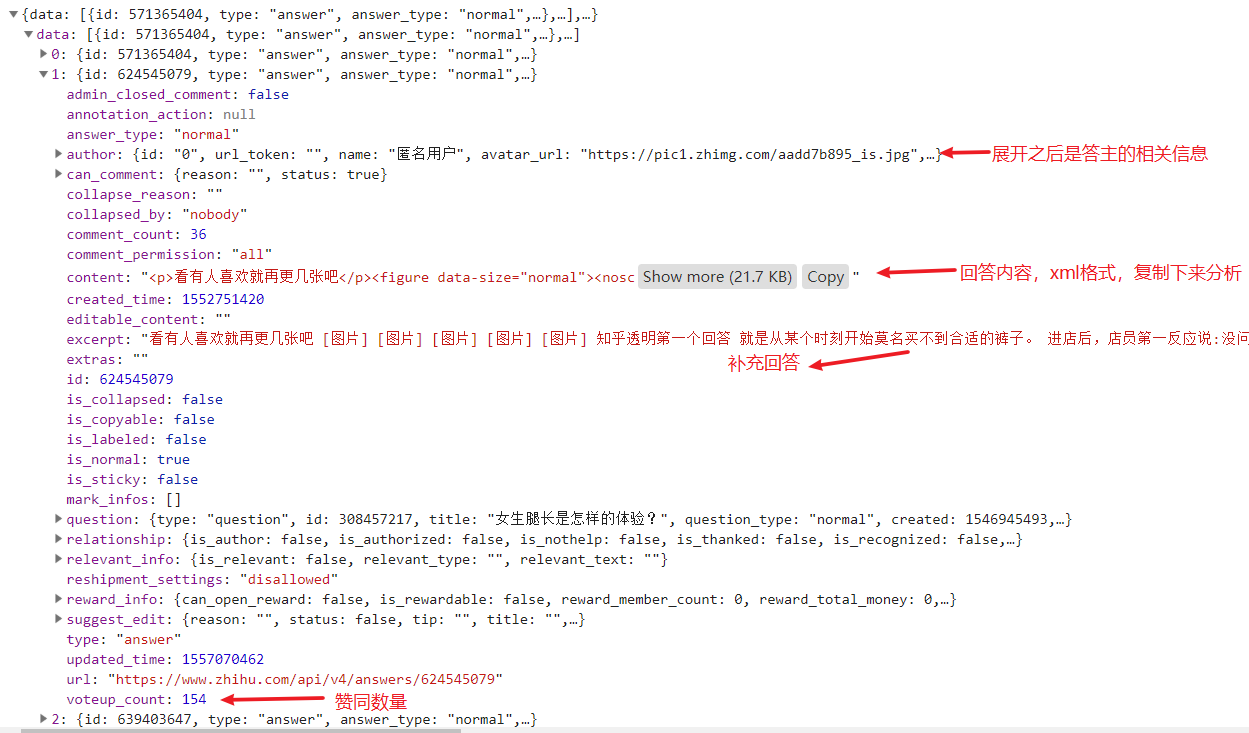
所有的信息包括答主信息和回答的信息都在了,content内容就是回答内容,复制下来,格式化发现这是css渲染的内容,也能理解,知乎回答必须要用富文本方式编辑,返回的内容必然是这种格式。看一下回答内容:
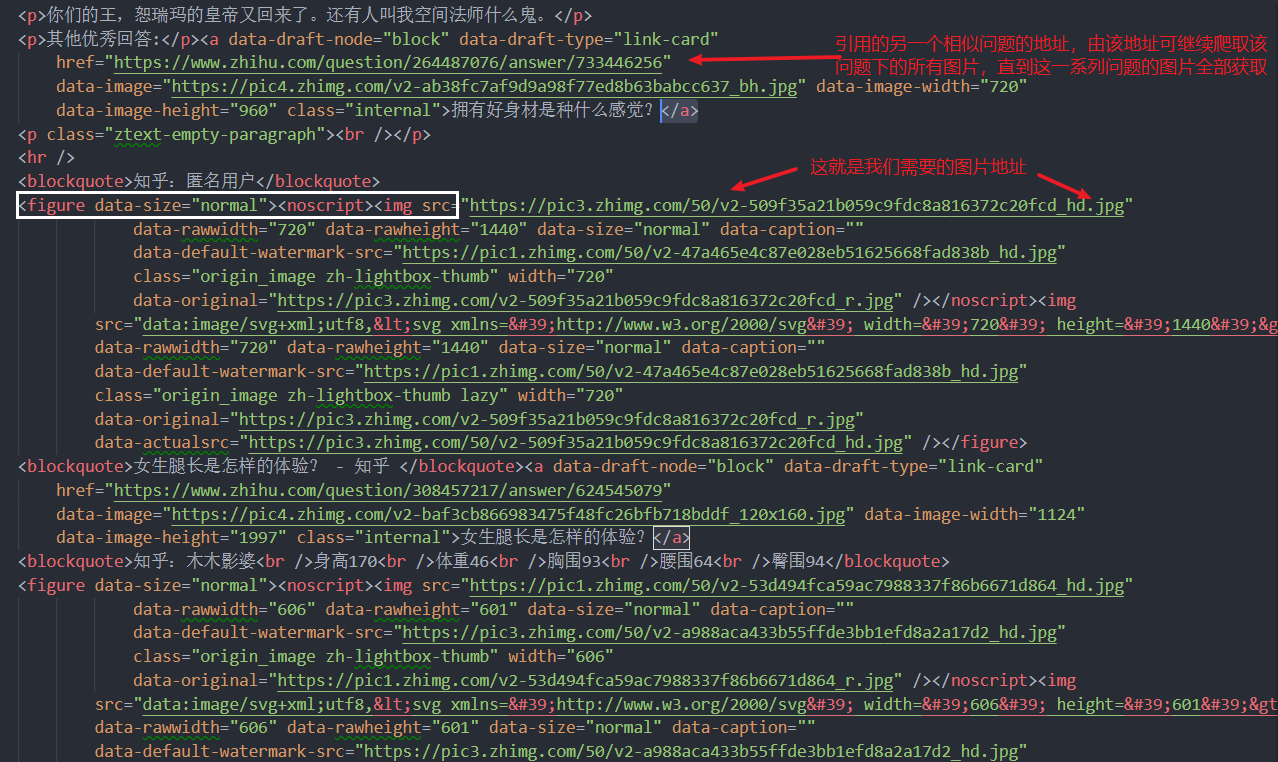
这个层次很明了,a 节点的 href 属性就是引用的相关问题的地址。figure 节点 下 noscript 节点下 img节点的 src 属性就是图片地址。用 pyquery 解析:
for answer in json['data']:
answer_info = {}
# 获取作者信息
author_info = answer['author']
author = {}
author['follower_count'] = author_info['follower_count'] # 作者被关注数量
author['headline'] = author_info['headline'] # 个性签名
author['name'] = author_info['name'] # 昵称
author['index_url'] = author_info['url'] # 主页地址
# 获取回答信息
voteup_count = answer['voteup_count'] # 赞同数
comment_count = answer['comment_count'] # 评论数
# 解析回答内容
content = pq(answer['content']) # content 内容为 xml 格式的网页,用pyquery解析
imgs_url = []
imgs = content('figure noscript img').items()
for img_url in imgs:
imgs_url.append(img_url.attr('src')) # 获取每个图片地址
# 获取回答内容引用的其他相似问题
question_info = content('a').items()
......太多不全部展示了,有兴趣可以看一下文末完整源代码
饮水思源保存文件以答主昵称命名,以示尊敬:
def save_to_img(imgs_url, author_name, base_path):
path = base_path + author_name
if not os.path.exists(path): # 判断路径文件夹是否已存在
os.mkdir(path)
for url in imgs_url:
try:
response = requests.get(url)
if response.status_code == 200:
img_path = '{0}/{1}.{2}'.format(path,
md5(response.content).hexdigest(), 'jpg') # 以图片的md5字符串命名防止重复图片
if not os.path.exists(img_path):
with open(img_path, 'wb') as jpg:
jpg.write(response.content)
else:
print('图片已存在,跳过该图片')
except requests.ConnectionError:
print('图片链接失效,下载失败,跳过该图片')
print('已保存答主:' + author_name + ' 回答内容的所有图片')
以图片内容的 md5 编码命名可以防止重复图片,如果图片被其他人下载之后加水印再上传,图片内容是不同的,所以可能有重复照片。
如果有需要可以把这些数据存到数据库,这里我以mongoDB为例:
#存储在mongoDB
client = MongoClient(host='localhost')
print(client)
db = client['zhihu']
collection = db['zhihu']
def save_to_mongodb(answer_info):
if collection.insert(answer_info):
print('已存储一条回答到MongoDB')
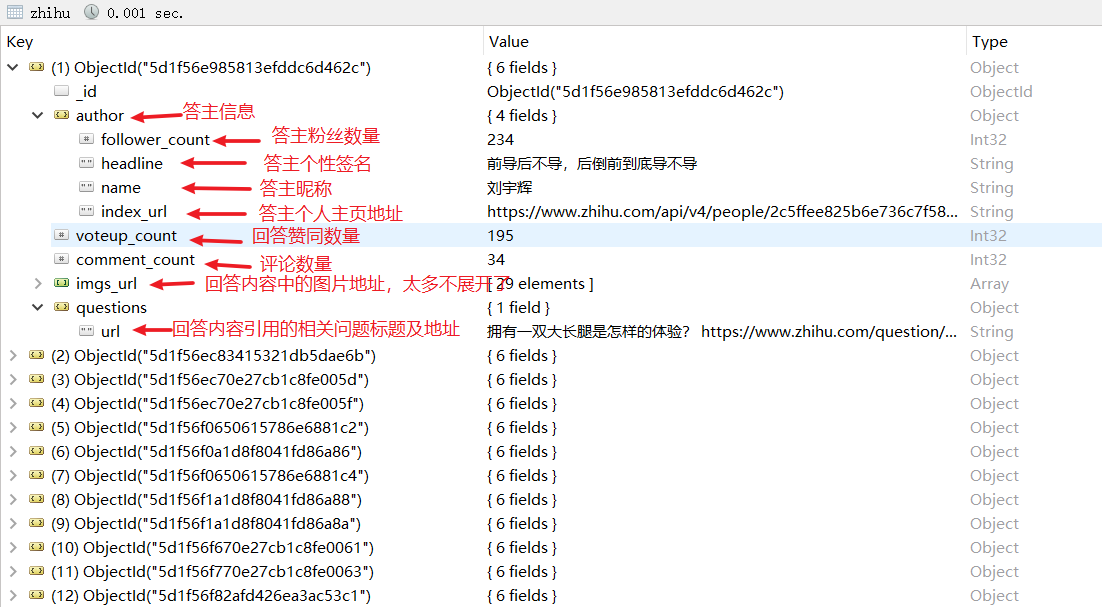
图中存储了答主引用的其他话题标题及地址,可以把这个地址传回去循环获取,直到所有类似话题图片全部下载。
算了,太多了,营养跟不上。这里就打包开头那三个话题前800条回答的图片共2325张。公众号回复 知乎 获得压缩包。
结语:
后面我大概看了一下里面的图片,里面还是有一点点重复的,而且还有一些什么表情图在里面,这都没什么,忍不了的是里面还有一点男士 秀自己的照片。。。跟预期不一样吖。
大家可根据情况加些判断函数,例如图片中间大概位置的像素点是否相同,来真正的把重复图片去掉。加些人体身材特征值对比,去掉男士的图片和表情图。这个太慢了,有时间的朋友自行发挥,我是要出去玩喽,周末开心。





