
在SQL Server中,子查询可以分为相关子查询和无关子查询,对于无关子查询来说,Not In子句比较常见,但Not In潜在会带来下面两种问题:
结果不准确
查询性能低下
下面我们来看一下为什么尽量不使用Not In子句。
结果不准确问题
在SQL Server中,Null值并不是一个值,而是表示特定含义,其所表示的含义是“Unknow”,可以理解为未定义或者未知,因此任何与Null值进行比对的二元操作符结果一定为Null,包括Null值本身。而在SQL Server中,Null值的含义转换为Bool类型的结果为False。让我们来看一个简单的例子,如图1所示。
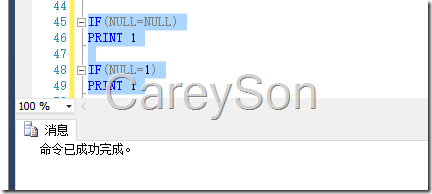
SQL Server提供了“IS”操作符与Null值做对比,用于衡量某个值是否为Null。
那么Not In 的问题在哪呢,如图2所示。

在图2中,条件3不属于Not In后面列表的任意一个,该查询却不返回任何值,与预期的结果不同,那么具体原因就是Not In子句对于Null值的处理,在SQL Server中,图2中所示的Not In子句其实可以等价转换为如图3所示的查询。

在图3中可以看到Not In可以转换为条件对于每个值进行不等比对,并用逻辑与连接起来,而前面提到过Null值与任意其他值做比较时,结果永远为Null,在Where条件中也就是False,因此3<>null就会导致不返回任何行,导致Not In子句产生的结果在意料之外。
因此,Not In子句如果来自于某个表或者列表很长,其中大量值中即使存在一个Null值,也会导致最终结果不会返回任何数据。
解决办法?
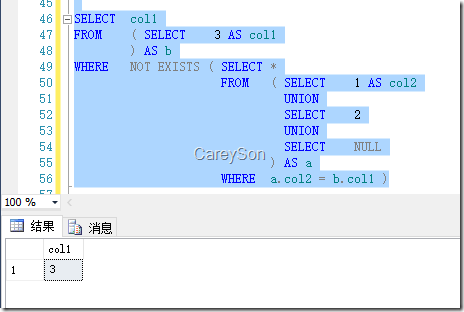
解决办法就是不使用Not In,而使用Not Exists作为替代。Exists的操作符不会返回Null,只会根据子查询中的每一行决定返回True或者False,当遇到Null值时,只会返回False,而不会由某个Null值导致整个子查询表达式为Null。对于图2中所示的查询,我们可以改写为子查询,如图4所示。
Not In导致的查询性能低下
前面我们可以看出,Not In的主要问题是由于对Null值的处理问题所导致,那么对Null值的处理究竟为什么会导致性能问题?让我们来看图5的示例。图5中,我们使用了Adventurework示例数据库,并为了演示目的将SalesOrderDetail表的ProductId的定义由Not Null改为Null,此时我们进行一个简单的Not In查询。如图5所示。
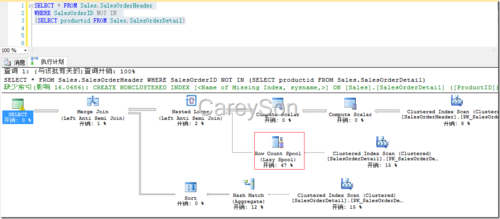
在图5中,我们看到一个Row Count Spool操作符,该操作符用于确认ProductId列中是否有Null值(过程是对比总行数和非Null行数,不想等则为有Null值,虽然我们知道该列中没有Null值,但由于列定义是允许Null的,因此SQL Server必须进行额外的确认),而该操作符占用了接近一半的查询成本。因此我们对比Not Exists,如图6所示。
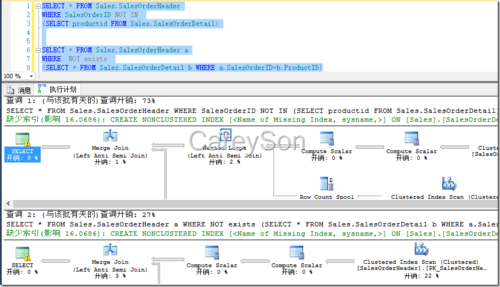
由图6可以看出,Not In的执行成本几乎是Not Exists的3倍,仅仅是由于SQL Server需要确认允许Null列中是否存在Null。根据图3中Not In的等价形式,我们完全可以将Not In转换为等价的Not Exist形式,如图7所示。
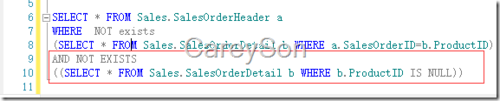
我们来对比图7和其等价Not In查询的成本,如图8所示。
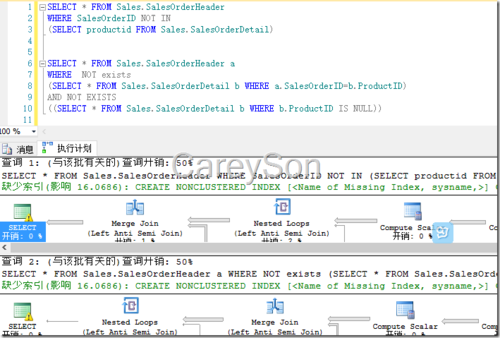
因此我们可以看到Not In需要额外的步骤处理Null值,上述情况是仅仅在SalesOrderDetail表中的ProductId列定义为允许Null,如果我们将SalesOrderHeader的SalesOrderID列也定义为允许Null时,会发现SQL Server还需要额外的成本确认该列上是否有Null值。如图9所示。
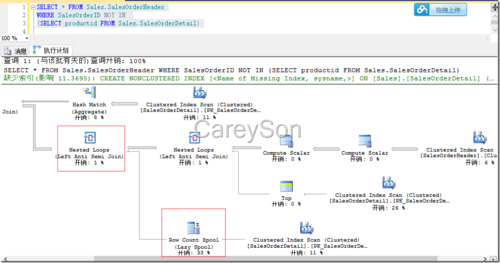
此时Not In对应的等价Not Exist形式变为如代码所示。
SELECT * FROM Sales.SalesOrderHeader a WHERE NOT EXISTS ( SELECT * FROM Sales.SalesOrderDetail b WHERE a.SalesOrderID = b.ProductID ) AND NOT EXISTS ( ( SELECT * FROM Sales.SalesOrderDetail b WHERE b.ProductID IS NULL ) ) AND NOT EXISTS ( SELECT 1 FROM ( SELECT * FROM Sales.SalesOrderHeader ) AS c WHERE c.SalesOrderID IS NULL )
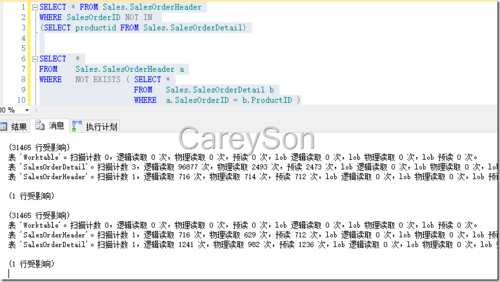
此时我们简单对比Not In和Not Exists的IO情况,如图10所示。
小结
本文阐述了Not In 的实现原理以及所带来的数据不一致和性能问题,在写查询时,尽量避免使用Not In,而转换为本文提供的Not Exists等价形式,将会减少很多麻烦。




