

今天早上六点半左右微信群里就看到张队发的关于.NET Spark大数据的链接https://devblogs.microsoft.com/dotnet/introducing-net-for-apache-spark/ ,正印证了“微软在不断通过.NET Core补齐各领域开发,真正实现一种语言的跨平台”这句话。那么我们今天就来看看这个 .NET for Apache Spark到底是个什么鬼?
什么是.NET for Apache Spark?
我们都知道Spark是一种流行的开源分布式处理引擎,适用于大型数据集(通常是TB级别)的分析。Spark可用于处理批量数据,实时流,机器学习和即时查询。处理任务分布在一个节点集群上,数据被缓存在内存中,以减少计算时间。到目前为止,Spark已经可以通过Scala,Java,Python和R访问,却不能通过.NET进行访问。
而.NET for Apache Spark就是旨在使.NET开发人员可以跨所有Spark API访问Apache®Spark™。
.NET for Apache Spark为C#和F#提供了高性能的API来操作Spark。使用这个.NET API,您可以访问Apache Spark的所有功能,包括SparkSQL、DataFrames、流、MLLib等等。.NET for Apache Spark允许您重用作为.NET开发人员已经拥有的所有知识、技能、代码和库。
C#/F#语言绑定到Spark将被写入一个新的Spark交互层,这提供了更容易的扩展性。这一新的Spark交互层的编写考虑了语言扩展的最佳实践,并针对交互和性能进行了优化。长期来看,这种扩展性可以用于在Spark中添加对其他语言的支持。
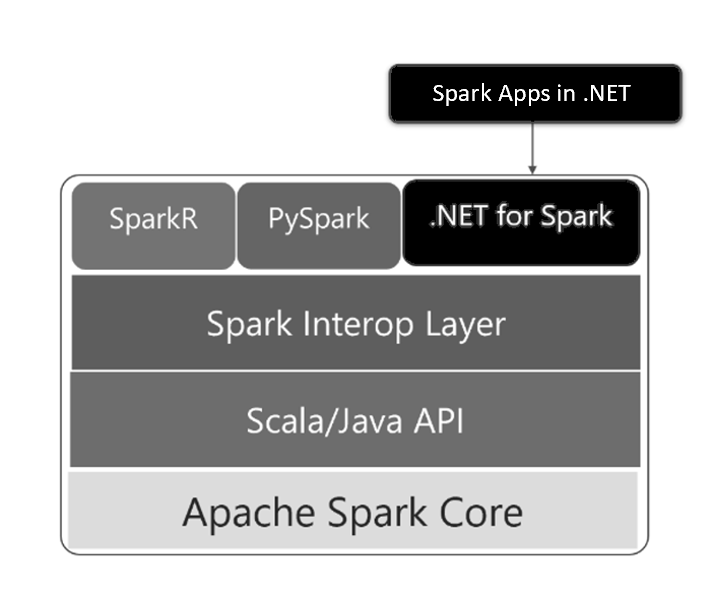
.NET for Apache Spark符合.NET Standard 2.0标准,可以在Linux、MacOS和Windows上使用。
官网地址:https://dotnet.microsoft.com/apps/data/spark
快速开始.NET for Apache Spark
在本节中,我们将展示如何在Windows上使用.NET Core运行.NET for Apache SPark应用程序。
在开始使用.NET for Apache Spark之前,确实需要安装一些东西,如: .NET Core 2.1 SDK | Visual Studio 2019 | Java 1.8 | Apache Spark 2.4.x。具体步骤可以参考这些步骤开始.net for Apache SPark。
一旦安装完毕,您就可以用三个简单的步骤开始在.NET中编写Spark应用程序。
在我们的第一个.NET Spark应用程序中,我们将编写一个基本的Spark pipeline,它将统计文本段中每个单词的出现次数。
// 1. Create a Spark sessionvar spark = SparkSession
.Builder()
.AppName("word_count_sample")
.GetOrCreate();
// 2. Create a DataFrameDataFrame dataFrame = spark.Read().Text("input.txt");
// 3. Manipulate and view datavar words = dataFrame.Select(Split(dataFrame["value"], " ").Alias("words"));
words.Select(Explode(words["words"])
.Alias("word"))
.GroupBy("word")
.Count()
.Show();.NET For Apache Spark的特点
可以用C#或者F# 进行Apache Spark开发
.NET for Apache Spark 为您提供了使用 C# 和F# 来操作Apache Spark的APIs。使用这些.NET API,您可以访问Apache Spark的所有功能,包括Spark SQL,用于处理结构化数据和Spark流。
高性能
第一版的.NET for Apache Spark在流行的TPC-H基准性能测试中的表现就很优异。TPC-H基准性能测试由一组面向业务的查询组成。下图展示了.NET Core与Python和Scala在TPC-H查询集上的性能比较。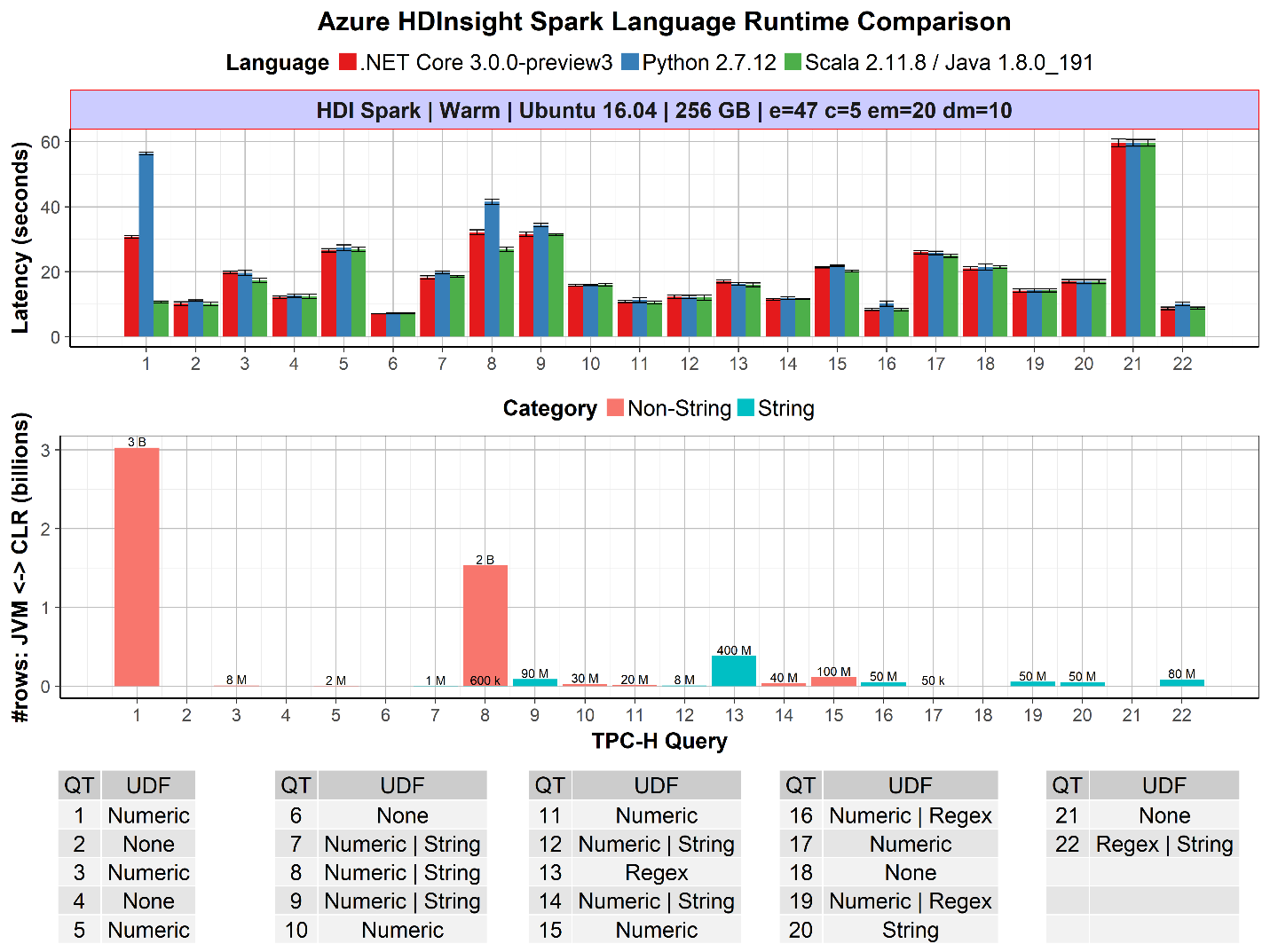
上面的图表显示了相对于Python和Scala,.NET对于Apache Spark的每个查询性能对比。NET for Apache Spark在Python和Scala上表现良好。此外,在UDF性能至关重要的情况下,比如查询1,JVM和CLR.NET之间传递3B行非字符串数据的速度比Python快2倍。
同样重要的是,这是.NET for Apache Spark的第一个预览版,我们的目标是进一步投资于改进和基准测试性能(例如,Arrow优化)。您可以按照我们的指示在我们的GitHub仓储上对此进行基准测试。
利用.NET生态系统
.NET For Apache Spark允许您重用作为.NET开发人员已经拥有的所有知识、技能、代码和库。
您的数据处理代码还可以利用.NET开发人员可以使用的大型库生态系统,如Newtonsoft.Json,ML.NET、MathNet.NDigics、NodaTime等。
跨平台
.NET for Apache Spark可以在Linux、MacOS和Windows上使用,就像.NET的其他部分一样。
.NET for Apache Spark在Azure HDInsight中默认可用,可以安装在Azure Databricks、Azure Kubernetes服务、AWS数据库、AWS EMR等中。
开源免费
.NET for Apache Spark是一个拥有来自3,700多家企业的60,000多名代码贡献者的强大开源社区的一部分。
.NET是免费的,其中包括用于 .NET for Apache Spark。没有任何费用或许可证费用,包括用于商业用途的费用。
.NET For Apache Spark的下一步计划
今天是我们旅程的第一步。以下是我们近期路线图的一些特点。
简化入门经验、文档和示例
原生集成到开发人员工具中,如VisualStudio、VisualStudio Code、木星笔记本
.net对用户定义的聚合函数的支持
NET的C#和F#的惯用API(例如,使用LINQ编写查询)
用Azure数据库、Kubernetes等提供的开箱即用的支持。
使.NET for Apache Spark成为Spark Core的一部分。
总结
.NET for Apache Spark是微软使.NET成为构建大数据应用程序的伟大技术栈的第一步。
想了解更多信息的可以访问.NET for Apache Spark的github仓储:https://github.com/dotnet/spark 。
最后,感谢您的阅读。
本文内容,部分参考自:https://devblogs.microsoft.com/dotnet/introducing-net-for-apache-spark/





