
引言
自然语言处理NLP(nature language processing),顾名思义,就是使用计算机对语言文字进行处理的相关技术以及应用。在对文本做数据分析时,我们一大半的时间都会花在文本预处理上,而中文和英文的预处理流程稍有不同,本文就对中、英文文本挖掘的常用的NLP的文本预处技术做一个总结。
文章内容主要按下图流程讲解:
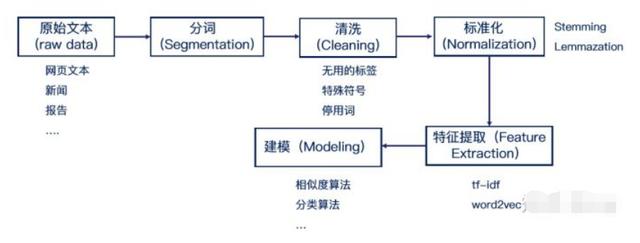
图片来自贪心科技
1.中英文文本预处理的特点
中英文的文本预处理大体流程如上图,但是还是有部分区别。首先,中文文本是没有像英文的单词空格那样隔开的,因此不能直接像英文一样可以直接用最简单的空格和标点符号完成分词。所以一般我们需要用分词算法来完成分词,具体操作后面会讲到。
当然,英文文本的预处理也有自己特殊的地方——拼写问题,很多时候,对英文预处理要包括拼写检查,比如“Helo World”这样的错误,我们不能在分析的时候再去纠错。还有就是词干提取(stemming)和词形还原(lemmatization),主要是因为英文中一个词会会不同的形式,这个步骤有点像孙悟空的火眼金睛,直接得到单词的原始形态。比如,"faster"、"fastest", 都变为"fast";“leafs”、“leaves”,都变为"leaf"。
2. 收集数据
文本数据的获取一般有两个方法:
别人已经做好的数据集,或则第三方语料库,比如wiki。这样可以省去很多麻烦。自己从网上爬取数据。但很多情况所研究的是面向某种特定的领域,这些开放语料库经常无法满足我们的需求。我们就需要用爬虫去爬取想要的信息了。可以使用如beautifulsoup、scrapy等框架编写出自己需要的爬虫。
3.文本预处理
3.1 去除数据中的非文本部分
由于爬下来的内容中有很多html的一些标签,需要去掉。还有少量的非文本内容的可以直接用Python 的正则表达式(re)删除, 另外还有一些特殊的非英文字符和标点符号,也可以用Python的正则表达式(re)删除。
import re
# 过滤不了\ 中文()还有————
r1 = u'[a-zA-Z0-9’!"#$%&'()*+,-./:;<=>?@,。?、…【】《》?“”‘’![\]^_`{|}~]+'#用户也可以在此进行自定义过滤字符
# 者中规则也过滤不完全
r2 = "[s+.!/_,$%^*(+"']+|[+——!,。?、~@#¥%……&*()]+"
# \可以过滤掉反向单杠和双杠,/可以过滤掉正向单杠和双杠,第一个中括号里放的是英文符号,第二个中括号里放的是中文符号,第二个中括号前不能少|,否则过滤不完全
r3 = "[.!//_,$&%^*()<>+"'?@#-|:~{}]+|[——!\\,。=?、:“”‘’《》【】¥……()]+"
# 去掉括号和括号内的所有内容
r4 = "\【.*?】+|\《.*?》+|\#.*?#+|[.!/_,$&%^*()<>+""'?@|:~{}#]+|[——!\,。=?、:“”‘’¥……()《》【】]"
sentence = "hello! wo?rd!."
cleanr = re.compile('<.*?>')
sentence = re.sub(cleanr, ' ', sentence) #去除html标签
sentence = re.sub(r4,'',sentence)
print(sentence)3.2 分词
由于英文单词间由空格分隔,所以分词分简单,只需要调用split()函数即可。对于中文来说常用的中文分词软件有很多,例如,结巴分词。安装也很简单,比如基于Python的,用"pip install jieba"就可以完成。
import jieba sentence = "我们学习人工智能" sentence_seg = jieba.cut(sentence) result = ' '.join(sentence_seg) print(result)
3.3 去掉停用词
停用词就是句子没什么必要的单词,去掉他们以后对理解整个句子的语义没有影响。文本中,会存在大量的虚词、代词或者没有特定含义的动词、名词,这些词语对文本分析起不到任何的帮助,我们往往希望能去掉这些“停用词”。
在英文中,例如,"a","the",“to",“their”等冠词,借此,代词..... 我们可以直接用nltk中提供的英文停用词表。首先,"pip install nltk"安装nltk。当你完成这一步时,其实是还不够的。因为NLTK是由许多许多的包来构成的,此时运行Python,并输入下面的指令。
import nltk from nltk.tokenize import word_tokenize nltk.download()
然后,Python Launcher会弹出下面这个界面,你可以选择安装所有的Packages,以免去日后一而再、再而三的进行安装,也为你的后续开发提供一个稳定的环境。
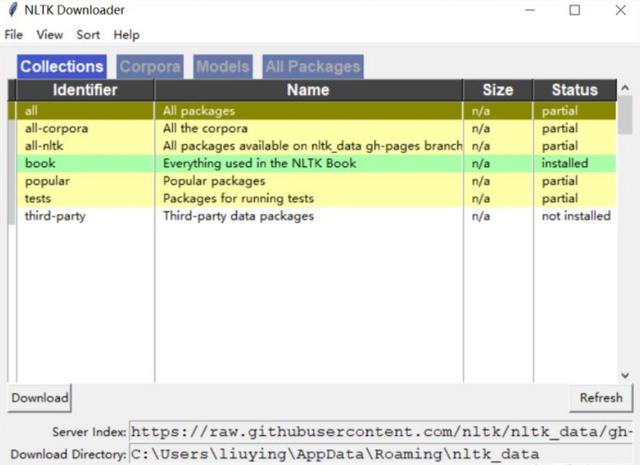
我们可以运行下面的代码,看看英文的停用词库。
from nltk.corpus import stopwords
stop = set(stopwords.words('english'))
print(stop)去除停用词
sentence = "this is a apple"
filter_sentence= [w for w in sentence.split(' ') if w not in stopwords.words('english')]
print(filter_sentence)对于中文停用词,由于nlkt不支持中文,所以需要自己构造中文停用词。常用的中文停用词表是1208个,下载地址在这 。有了中文停用词表,去除停用词的代码和英文类似,这里就不赘述了。
3.4 英文单词--stemming和lemmatization
词干提取(stemming)和词型还原(lemmatization)是英文文本预处理的特色。两者其实有共同点,即都是要找到词的原始形式。只不过词干提取(stemming)会更加激进一点,它在寻找词干的时候可以会得到不是词的词干。比如"leaves"的词干可能得到的是"leav", 并不是一个词。而词形还原则保守一些,它一般只对能够还原成一个正确的词的词进行处理。nltk中提供了很多方法,wordnet的方式比较好用,不会把单词过分精简。
from nltk.stem import SnowballStemmer
stemmer = SnowballStemmer("english") # 选择语言
stemmer.stem("leaves") # 词干化单词
from nltk.stem import WordNetLemmatizer
wnl = WordNetLemmatizer()
print(wnl.lemmatize('leaves'))3.5 英文单词--转换为小写
英文单词有大小写之分,Python和python是同一个单词,所以转换为小写可以减少单词数量。
word = "Python" word = word.lower() #转换成lower_case print(word)
3.6 特征处理
数据处理到这里,基本上是干净的文本了,现在可以调用sklearn来对我们的文本特征进行处理了。常用的方法如下:
Bag of Words词袋模型BowTf-idfN-gram语言模型BigramTrigramWord2vec分布式模型Word2vec
接下来我将结合代码简单讲解一下Tf-idf,Bigram,word2vec的用法。语言模型这一块内容,可以在之后的文章深入了解。
Tf-idf(Term Frequency-Inverse Document Frequency)
该模型基于词频,将文本转换成向量,而不考虑词序。假设现在有N篇文档,在其中一篇文档D中,词汇x的TF、IDF、TF-IDF定义如下:
1.Term Frequency(TF(x)):指词x在当前文本D中的词频
2.Inverse Document Frequency(IDF): N代表语料库中文本的总数,而N(x)代表语料库中包含词x的文本总数,平滑后的IDF如下:
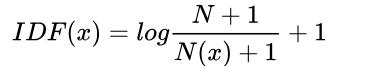
3.TF-IDF :

使用sklearn库里的TfidfVectorizer类可以帮助我们完成向量化,TF-IDF和标准化三步。
from sklearn.feature_extraction.text import TfidfVectorizer corpus = ["This is sample document.", "another random document.", "third sample document text"] vector = TfidfVectorizer() tf_data = vector.fit_transform(corpus) print(tf_data) #(句子下标, 单词特征下标) 权重 print(vector.vocabulary_) #单词特征 df1 = pd.DataFrame(tf_data.toarray(), columns=vector.get_feature_names()) # to DataFrame df1

N-gram语言模型
词袋模型不考虑每个单词的顺序。有时候把一句话顺序捣乱,我们可能就看不懂这句话在说什么了,例如:
我玩电脑 = 电脑玩我 ?
N-gram模型是一种语言模型(Language Model),语言模型是一个基于概率的判别模型,它的输入是一句话(单词的顺序序列),输出是这句话的概率,即这些单词的联合概率(joint probability)。N-gram本身也指一个由N个单词组成的集合,各单词具有先后顺序,且不要求单词之间互不相同。常用的有 Bi-gram (N=2N=2) 和 Tri-gram (N=3N=3),一般已经够用了。例如,"I love deep learning",可以分解的 Bi-gram 和 Tri-gram :
Bi-gram : {I, love}, {love, deep}, {love, deep}, {deep, learning}
Tri-gram : {I, love, deep}, {love, deep, learning}
sklearn库中的CountVectorizer 有一个参数ngram_range,如果赋值为(2,2)则为Bigram,当然使用语言模型会大大增加我们字典的大小。
ram_range=(1,1) 表示 unigram, ngram_range=(2,2) 表示 bigram, ngram_range=(3,3) 表示 thirgram from sklearn.feature_extraction.text import CountVectorizer import pandas as pd import jieba data = ["为了祖国,为了胜利,向我开炮!向我开炮!", "记者:你怎么会说出那番话", "我只是觉得,对准我自己打"] data = [" ".join(jieba.lcut(e)) for e in data] # 分词,并用" "连接 vector = CountVectorizer(min_df=1, ngram_range=(2,2)) # bigram X = vector.fit_transform(data) # 将分词好的文本转换为矩阵 print(vector.vocabulary_ ) # 得到特征 print(X) #(句子下标, 单词特征下标) 频数 df1 = pd.DataFrame(X.toarray(), columns=vector.get_feature_names()) # to DataFrame df1.head()
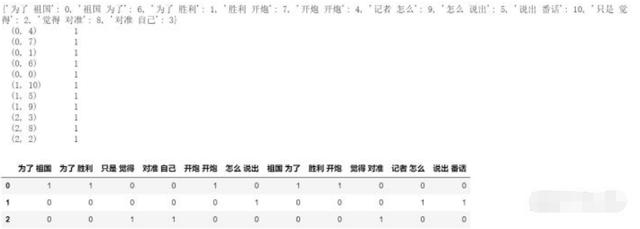
Word2vec词向量
Word2Vec使用一系列的文档的词语去训练模型,把文章的词映射到一个固定长度的连续向量
。一般维数较小,通常为100 ~ 500。意义相近的词之间的向量距离较小。它以稠密的向量形式表示单词。有两种模式:
CBOW(Continuous Bag-Of-Words):利用词的上下文预测当前的词。
Skip-Gram:利用当前的词来预测上下文。
因为word2vector模型的得到的是词向量,如何表示句子呢?最简单的方法就是,将每个句子中的词向量相加取平均值,即每个句子的平均词向量来表示句子的向量。
from gensim.models import Word2Vec import numpy as np data = ["I love deep learning","I love studying","I want to travel"] #词频少于min_count次数的单词会被丢弃掉 #size指特征向量的维度为50 #workers参数控制训练的并行数 train_w2v = Word2Vec(data,min_count=5,size=50, workers=4) for row in data: #计算平均词向量,表示句子向量 vec = np.zeros(50) count = 0 for word in row: try: vec += train_w2v[word] count += 1 except: pass avg_data.append(vec/count) print(avg_data[1])
4. 建立分析模型
有了每段文本的特征向量后,我们就可以利用这些数据建立分类模型,或者聚类模型了,或者进行相似度的分析。
5.总结
3.6小节中的特征提取一块,为了demo演示的方便,没有和前面的分词,清洗,标准化结合在一起。如果是从分词步骤开始做的文本预处理,需要注意:在特征提取时,要将每个句子的单词以空格连接起来。






