

本文原创地址,
我的博客:https://jsbintask.cn/2019/03/10/jdk/jdk8-threadpool/(食用效果最佳),转载请注明出处!
前言
在实际工作中,线程是一个我们经常要打交道的角色,它可以帮我们灵活利用资源,提升程序运行效率。但是我们今天不是探讨线程!我们今天来聊聊另一个与线程息息相关的角色:线程池.本篇文章的目的就是全方位的解析线程池的作用,以及jdk中的接口,实现以及原理,另外对于某些重要概念,将从源码的角度探讨。tip:本文较长,建议先码后看。
线程池介绍
首先我们看一段创建线程并且运行的常用代码:
for (int i = 0; i < 100; i++) {
new Thread(() -> {
System.out.println("run thread->" + Thread.currentThread().getName());
//to do something, send email, message, io operator, network...
}).start();
}
上面的代码很容易理解,我们为了异步,或者效率考虑,将某些耗时操作放入一个新线程去运行,但是这样的代码却存在这样的问题:
- 创建销毁线程资源消耗; 我们使用线程的目的本是出于效率考虑,可以为了创建这些线程却消耗了额外的
时间,资源,对于线程的销毁同样需要系统资源。 - cpu资源有限,上述代码创建线程过多,造成有的任务不能即时完成,响应时间过长。
- 线程无法管理,无节制地创建线程对于有限的资源来说似乎成了“得不偿失”的一种作用。
手动创建执行线程存在以上问题,而线程池就是用来解决这些问题的。怎么解决呢?我们可以先粗略的定义一下线程池:
线程池是一组已经创建好的,一直在等待任务执行的线程的集合。
因为线程池中线程是已经创建好的,所以对于任务的执行不会消耗掉额外的资源,线程池中线程个数由我们自定义添加,可相对于资源,资源任务做出调整,对于某些任务,如果线程池尚未执行,可手动取消,线程任务变得能够管理!
所以,线程池的作用如下:
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。
jdk线程池详解
上面我们已经知道了线程池的作用,而对于这样一个好用,重要的工具,jdk当然已经为我们提供了实现,这也是本篇文章的重点。
在jdk中,关于线程池的接口,类都定义在juc(java.util.concurrent)包中,这是jdk专门为我们提供用于并发编程的包,当然,本篇文章我们只介绍与线程池有关的接口和类,首先我们看下重点要学习的接口和类: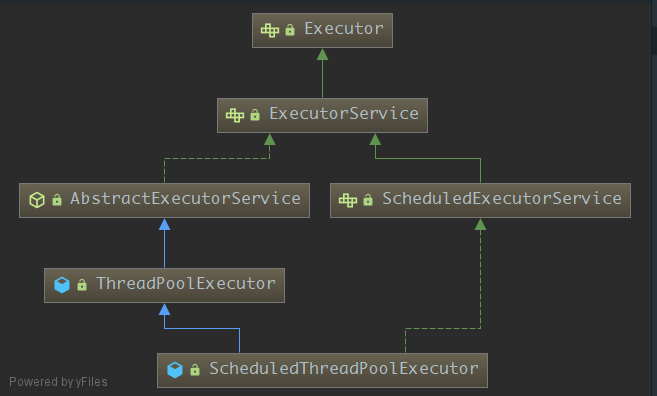
如图所示,我们将一一讲解这6个类的作用并且分析。
Executor
首先我们需要了解就是Executor接口,它有一个方法,定义如下: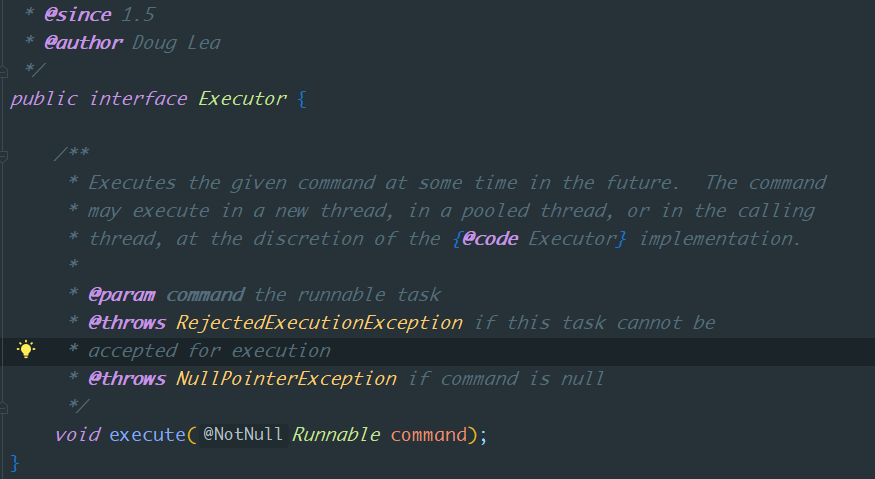
Executor自jdk1.5引入,这个接口只有一个方法execute声明,它的作用以及定义如下:接收一个任务(Runnable)并且执行。注意:同步执行还是异步执行均可!
由它的定义我们就知道,它是一个线程池最基本的作用。但是在实际使用中,我们常常使用的是另外一个功能更多的子类ExecutorService。
ExecutorService
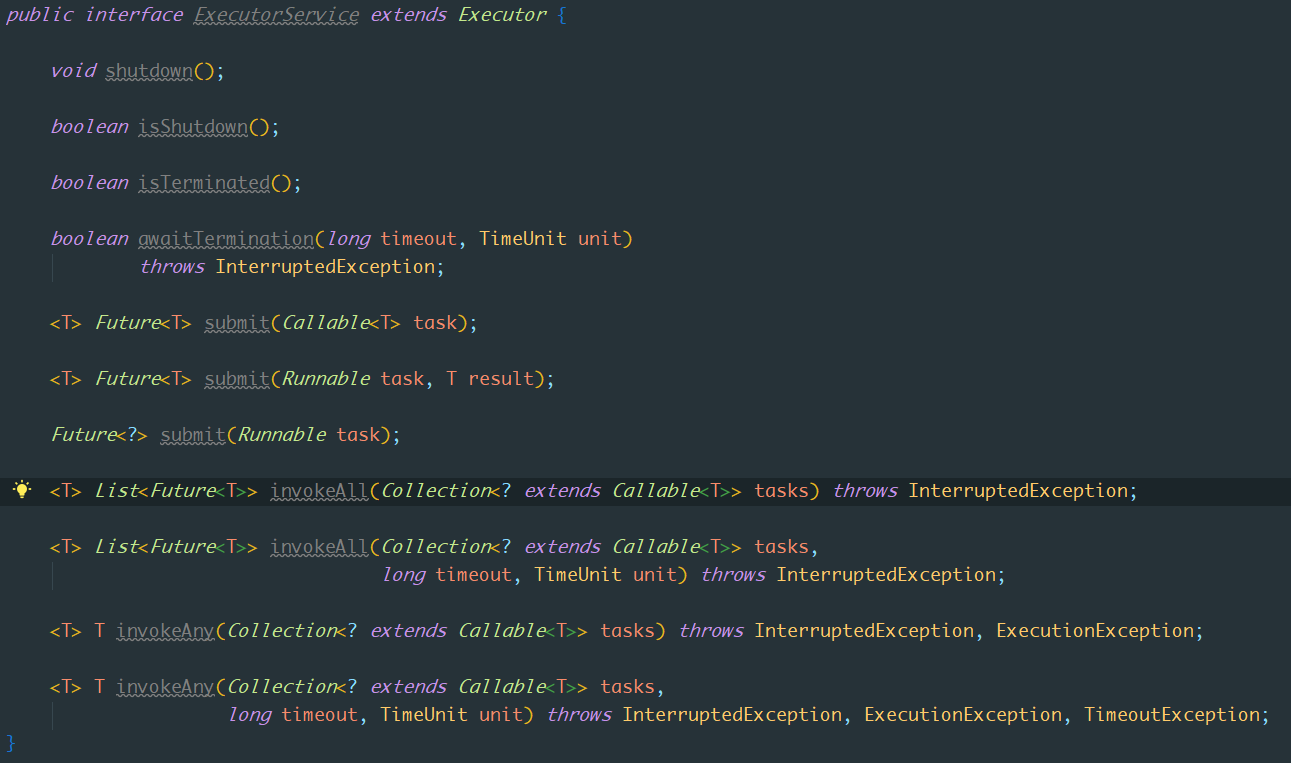
这个接口继承自Executor,它的方法定义就丰富多了,可以关闭,提交Future任务,批量提交任务,获取执行结果等,我们一一讲解下每个方法作用声明:
void shutdown(): “优雅地”关闭线程池,为什么是“优雅地”呢?因为这个线程池在关闭前会先等待线程池中已经有的任务执行完成,一般会配合方法awaitTermination一起使用,调用该方法后,线程池中不能再加入新的任务。List<Runnable> shutdownNow();: “尝试”终止正在执行的线程,返回在正在等待的任务列表,调用这个方法后,会调用正在执行线程的interrupt()方法,所以如果正在执行的线程如果调用了sleep,join,await等方法,会抛出InterruptedException异常。boolean awaitTermination(long timeout, TimeUnit unit): 该方法是一个阻塞方法,参数分别为时间和时间单位。这个方法一般配合上面两个方法之后调用。如果先调用shutdown方法,所有任务执行完成返回true,超时返回false,如果先调用的是shutdownNow方法,正在执行的任务全部完成true,超时返回false。boolean isTerminated();: 调用方法1或者2后,如果所有人物全部执行完毕则返回true,也就是说,就算所有任务执行完毕,但是不是先调用1或者2,也会返回false。<T> Future<T> submit(Callable<T> task);: 提交一个能够返回结果的Callable任务,返回任务结果抽象对象是Future,调用Future.get()方法可以阻塞等待获取执行结果,例如:result = exec.submit(aCallable).get();,提交一个任务并且一直阻塞知道该任务执行完成获取到返回结果。<T> Future<T> submit(Runnable task, T result);: 提交一个Runnable任务,执行成功后调用Future.get()方法返回的是result(这是什么骚操作?)。Future<?> submit(Runnable task);:和6不同的是调用Future.get()方法返回的是null(这又是什么操作?)。<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks): 提交一组任务,并且返回每个任务执行结果的抽象对象List<Future<T>>,Future作用同上,值得注意的是:
当调用其中任一Future.isDone()(判断任务是否完成,正常,异常终止都算)方法时,必须等到所有任务都完成时才返回true,简单说:全部任务完成才算完成。<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit): 同方法8,多了一个时间参数,不同的是:如果超时,Future.isDone()同样返回true。<T> T invokeAny(Collection<? extends Callable<T>> tasks):这个看名字和上面对比就容易理解了,返回第一个正常完成的任务地执行结果,后面没有完成的任务将被取消。<T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit):同10相比,多了一个超时参数。不同的是:在超时时间内,一个任务都没有完成,将抛出TimeoutException。
到现在,我们已经知道了一个线程池基本的所有方法,知道了每个方法的作用,接下来我们就来看看具体实现,首先我们研究下ExecutorService的具体实现抽象类:AbstractExecutorService。
AbstractExecutorService
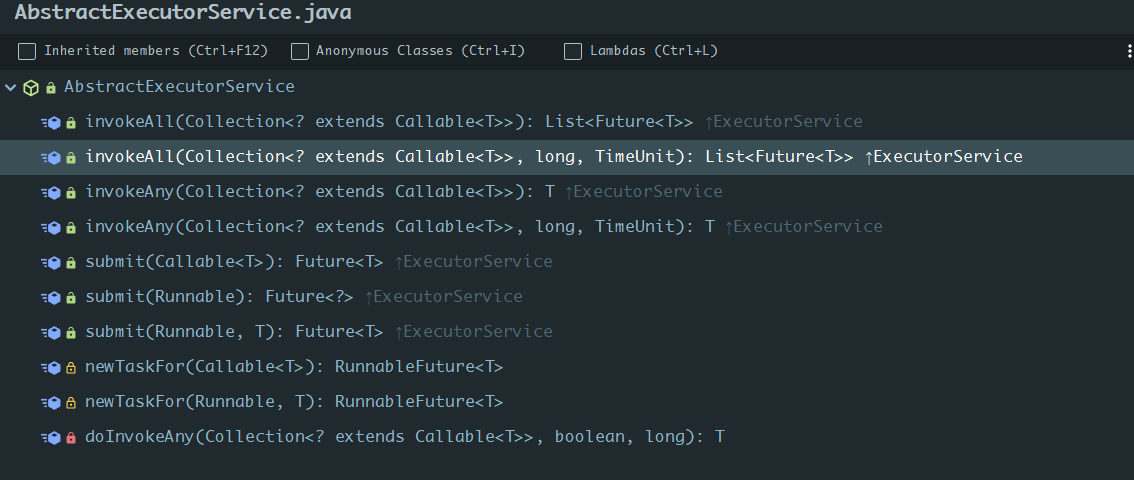
AbstractExecutorService是一个抽象类,继承自ExecutorService,它实现了ExecutorService接口的submit, invokeAll, invokeAny方法,主要用于将ExecutorService的公共实现封装,方便子类更加方便使用,接下来我们看看具体实现:
1. submit方法:
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
- 判空
- 利用task构建一个Future的子类RunnableFuture,最后返回
- 执行这个任务(execute方法声明在Executor接口中,所以也是交由子类实现)。
execute方法交由子类实现了,这里我们主要分析newTaskFor方法,看它是如何构建Future对象的:
首先,RunnableFuture接口定义如下:
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
他就是Future和Runnable的组合,它的实现是FutureTask: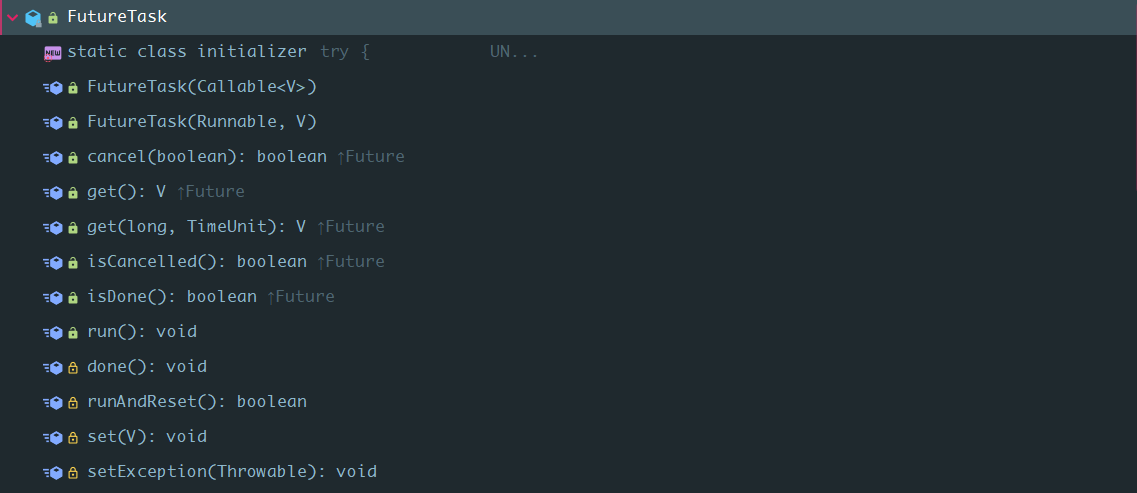
2. invokeAll方法:
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException {
if (tasks == null)
throw new NullPointerException();
ArrayList<Future<T>> futures = new ArrayList<Future<T>>(tasks.size());
boolean done = false; // ①
try {
for (Callable<T> t : tasks) { // ②
RunnableFuture<T> f = newTaskFor(t);
futures.add(f);
execute(f);
}
for (int i = 0, size = futures.size(); i < size; i++) {
Future<T> f = futures.get(i); // ③
if (!f.isDone()) {
try {
f.get();
} catch (CancellationException ignore) {
} catch (ExecutionException ignore) {
}
}
}
done = true; // ④
return futures;
} finally {
if (!done) // ⑤
for (int i = 0, size = futures.size(); i < size; i++)
futures.get(i).cancel(true);
}
}
- 声明一个flag判断所有任务是否全部完成
- 调用newTaskFor方法构建RunnableFuture对象,循环调用
execute方法添加每一个任务。 - 遍历每个任务结果,判断是否执行完成,没有完成调用 get()阻塞方法等待完成。
- 所有任务全部完成,将flag设置成true。
- 出现异常,还有任务没有完成,所有任务取消:
Future.cancel()(实际是调用执行线程的interrupt方法。
上面代码分析和我们一开始讲解ExecutorService的invokeAll一致。
3. invokeAny方法
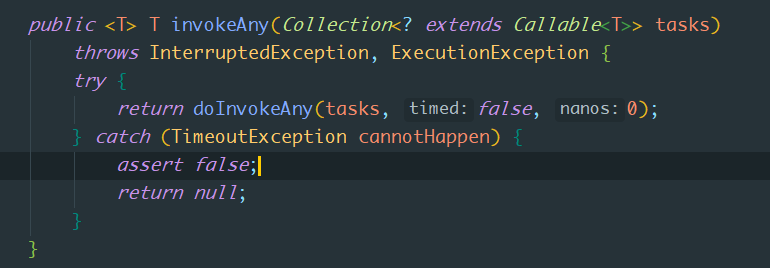
invokeAny实际调用doInvokeAny:
private <T> T doInvokeAny(Collection<? extends Callable<T>> tasks,
boolean timed, long nanos)
throws InterruptedException, ExecutionException, TimeoutException {
if (tasks == null)
throw new NullPointerException();
int ntasks = tasks.size();
if (ntasks == 0)
throw new IllegalArgumentException();
ArrayList<Future<T>> futures = new ArrayList<Future<T>>(ntasks);
ExecutorCompletionService<T> ecs = // ①
new ExecutorCompletionService<T>(this);
try {
ExecutionException ee = null;
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Iterator<? extends Callable<T>> it = tasks.iterator();
futures.add(ecs.submit(it.next())); // ②
--ntasks;
int active = 1;
for (;;) {
Future<T> f = ecs.poll(); // ③
if (f == null) {
if (ntasks > 0) {
--ntasks;
futures.add(ecs.submit(it.next()));
++active;
}
else if (active == 0)
break;
else if (timed) {
f = ecs.poll(nanos, TimeUnit.NANOSECONDS);
if (f == null)
throw new TimeoutException();
nanos = deadline - System.nanoTime();
}
else // ④
f = ecs.take();
}
if (f != null) { // ⑤
--active;
try {
return f.get();
} catch (ExecutionException eex) {
ee = eex;
} catch (RuntimeException rex) {
ee = new ExecutionException(rex);
}
}
}
if (ee == null)
ee = new ExecutionException();
throw ee;
} finally {
for (int i = 0, size = futures.size(); i < size; i++) // ⑥
futures.get(i).cancel(true);
}
}
- 声明一个
ExecutorCompletionServiceecs,这个对象实际是一个任务执行结果阻塞队列和线程池的结合,所以它可以加入任务,执行任务,将任务执行结果加入阻塞队列。 - 向ecs添加tasks中的第一个任务并且执行。
- 从ecs的阻塞队列中取出第一个(队头),如果为null(不为null跳到注释⑤),说明一个任务都还没执行完成,继续添加任务。
- 如果所有任务都被添加了,阻塞等待任务的执行结果,知道有任一任务执行完成。
- 如果取到了某个任务的执行结果,直接返回。
- 取消所有还没执行的任务。
上面代码分析和我们一开始讲解ExecutorService的invokeAny一致。 到现在,我们已经分析完了AbstractExecutorService中的公共的方法,接下来就该研究最终的具体实现了:ThreadPoolExecutor
ThreadPoolExecutor
ThreadPoolExecutor继承自AbstractExecutorService,它是线程池的具体实现: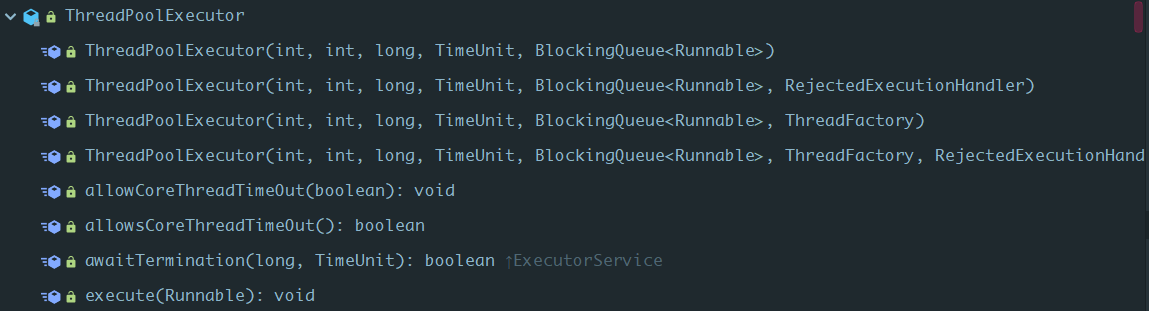
我们首先分析下构造方法:public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler)。corePoolSize:核心线程数,maximumPoolSize:线程池最大允许线程数,workQueue:任务队列,threadFactory:线程创建工厂,handler: 任务拒绝策,keepAliveTime, unit:等待时长,它们的具体作用如下: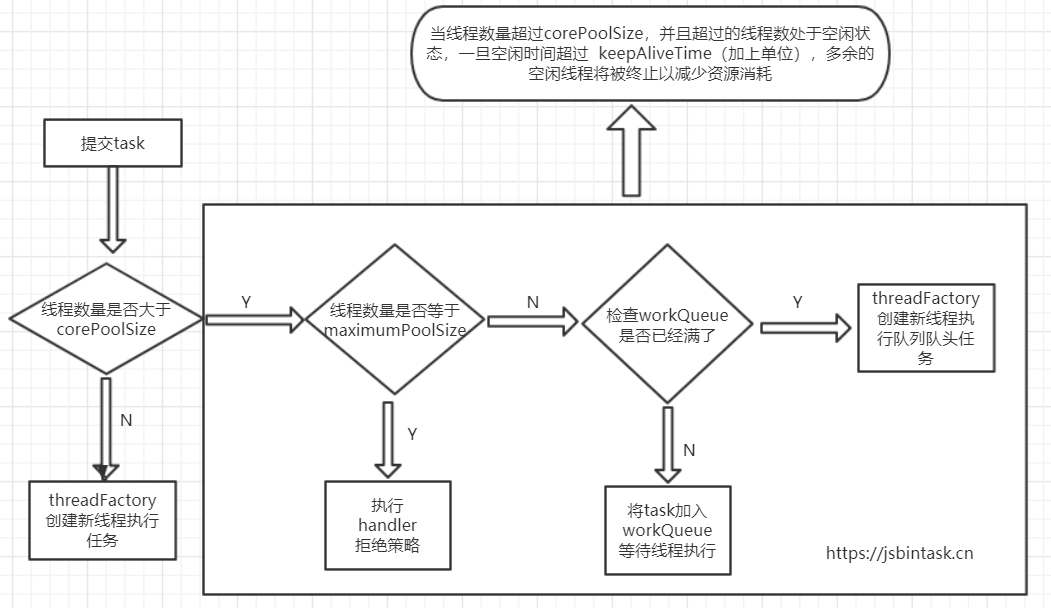
提交一个task(Runnable)后(执行execute方法),检查总线程数是否小于corePoolSize,小于等于则使用threadFactory直接创建一个线程执行任务,大于则再次检查线程数量是否等于maximumPoolSize,等于则直接执行handler拒绝策略,小于则判断workQueue是否已经满了,没满则将任务加入等待线程执行,满了则使用threadFactory创建新线程执行队头任务。
通过流程图我们知道每个参数作用,这里值得注意的是,如果我们将某些参数特殊化,则可以得到特殊的线程池:
- corePoolSize=maximuPoolSize,我们可以创建一个线程池线程数量固定的任务。
- maximumPoolSize设置的足够大(Integer.MAX_VALUE),可以无限制的加入任务。
- workQueue设置的足够大,线程池中的数量不会超过corePoolSize,此时maximumPoolSize参数无用。
- corePoolSize=0,线程池一旦空闲(超过时间),线程都将被回收。
- 我们上面知道,如果多余的空闲线程空闲时间超过keepAliveTime*unit,这些线程将被回收。我们可以通过方法
allowCoreThreadTimeOut使这个参数对线程池中所有线程都有效果。 - workQueue一般有三种实现:
- SynchronousQueue,这是一个空队列,不会保存提交的task(添加操作必须等待另外的移除操作)。
- ArrayBlockingQueue,数组实现的丢列,可以指定队列的长度。
- LinkedBlockingQueue, 链表实现的队列,所以理论上可以无限大,也可以指定链表长度。
- 而RejectedExecutionHandler一般由四种实现:
- AbortPolicy, 直接抛出
RejectedExecutionException,这是线程池中的默认实现 - DiscardPolicy,什么都不做
- DiscardOldestPolicy,丢弃workQueue队头任务,加入新任务
- CallerRunsPolicy,直接在调用者的线程执行任务
最后,我们再分析下ThreadPoolExecutor核心方法execute:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get(); // ①
if (workerCountOf(c) < corePoolSize) { // ②
if (addWorker(command, true))
return;
c = ctl.get(); // ③
}
if (isRunning(c) && workQueue.offer(command)) { // ④
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command)) // ⑤
reject(command);
else if (workerCountOf(recheck) == 0) // ⑥
addWorker(null, false);
}
else if (!addWorker(command, false)) // ⑦
reject(command);
}
- 获取线程池中的线程数量
- 线程池中线程数量小于corePoolSize,直接调用addWorker添加新线程执行任务返回。
- 因为多线程的关系,上一步可能调用addWorker失败(其它线程创建了,数以数量已经超过了),重启获取线程数量。
- 向workQueue添加添加任务,如果添加成功,double获取线程数量,添加失败,走到步骤⑦
- double检查后发现线程池已经关闭或者数量超出,回滚已经添加的任务(remove(command))并且执行拒绝策略。
- double检查通过,添加一个新线程。
- 再次添加线程,失败则调用拒绝策略。
好了,到现在jdk中的线程池核心的实现,策略,分析我们已经分析完成了。接下来我我们就来看看关于线程池的另外的一些扩展,也就是图上的剩下的接口和类: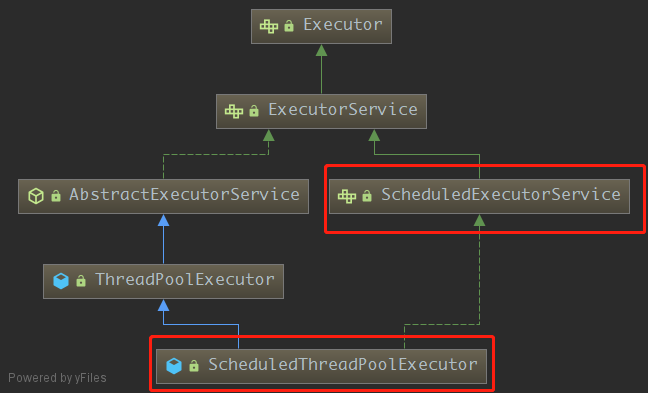
ScheduledExecutorService
ScheduledExecutorService继承自ExecutorService,ExecutorService的分析上面我们已经知道了,我们来看看它扩展了哪些方法: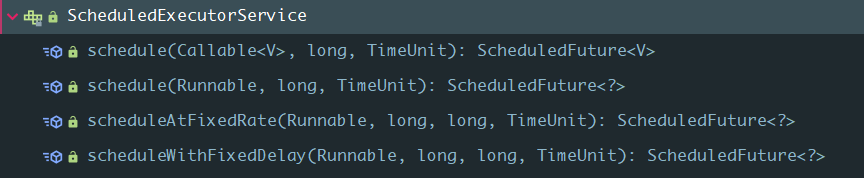
这个接口作为线程池的定义主要增加了可以定时执行任务(执行一次)和定期执行任务(重复执行),我们来一一简述下每个方法的作用。
public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit);: 这个方法用于定时执行任务command,延迟的时间为delay*unit,它返回一个ScheduledFuture对象用于获取执行结果或者剩余延时,调用Future.get()方法将阻塞当前线程最后返回null。
public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit);:同上,不同的是,调用Future.get()方法将返回执行的结果,而不是null。public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period,TimeUnit unit);: 重复执行任务command,第一次执行时间为initialDelay延迟后,以后的执行时间将在initialDelay + period * n,unit代表时间单位,值得注意的是,如果某次执行出现异常,后面该任务就不会再执行。或者通过返回对象Future手动取消,后面也将不再执行。public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,long initialDelay,long delay, TimeUnit unit);: 效果同上,不同点:如果command耗时为 y,则上面的计算公式为initialDelay + period * n + y,也就是说,它的定时时间会加上任务耗时,而上面的方法则是一个固定的频率,不会算上任务执行时间!
这是它扩展的四个方法,其中需要注意的是scheduleAtFixedRate和scheduleWithFixedDelay的细微差别,最后,我们来看下它的实现类:ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor继承自ThreadPoolExecutor类,实现了ScheduledExecutorService接口,上面均已经分析。
它的构造器如下: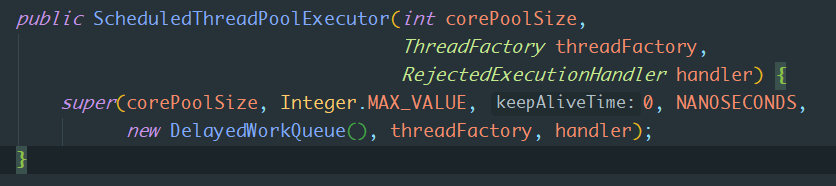
看起来比它的父类构造器简洁,主要因为它的任务队列workQueue是默认的(DelayedWorkQueue),并且最大的线程数为最大值。接着我们看下DelayedWorkQueue实现: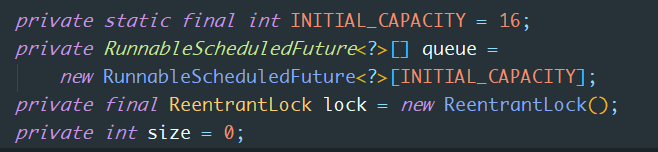
它内部使用数组维护了一个二叉树,提高了任务查找时间,而之所以ScheduledThreadPoolExecutor能够实现延时的关键也在于DelayedWorkQueue的take()方法:
public RunnableScheduledFuture<?> take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) { // ①
RunnableScheduledFuture<?> first = queue[0];
if (first == null)
available.await();
else {
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0)
return finishPoll(first);
first = null; // don't retain ref while waiting
if (leader != null)
available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && queue[0] != null)
available.signal();
lock.unlock();
}
}
- 工作线程调用take方法获取剩余任务。
- 检查这个任务是否已经到了执行时间。
- 未到执行时间,await等待。
- 自己唤醒,进入循环再次计算时间。
好了,到目前为止jdk中关于线程池的6个核心类已经全部分析完毕了。接下来还有最后一个小问题,我们手动创建线程池参数也太了,不管是ThreadPoolExecutor还是ScheduledThreadPoolExecutor,这对于用户来说似乎并不太友好,当然,jdk已经想到了这个问题,所以,我们最后再介绍一个创建这些线程池的工具类:Executors:
Executors
它的主要工具方法如下: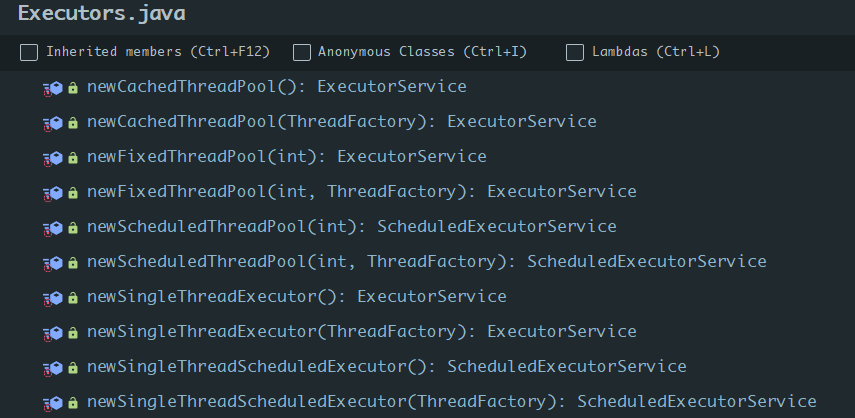
比起手动创建,它帮我们加了很多默认值,用起来当然就方便多了,比如说newFixedThreadPool
创建一个线程数固定的线程池,其实就是核心线程数等于最大线程数,和我们一开始分析的结果一样。
值得注意的是:为了我们的程序安全可控性考虑,我们应该尽量考虑手动创建线程池,知晓每一个参数的作用,降低不稳定性!
总结
本次,我们首先从代码出发,分析了线程池给我们带来的好处以及直接使用线程的弊端,接着引出了jdk中的已经实现了的线程池。然后重点分析了jdk中关于线程池的六个最重要的接口和类,并且从源码角度讲解了关键点实现,最后,处于方便考虑,我们还知道jdk给我们留了一个创建线程池的工具类,简化了手动创建线程池的步骤。
真正做到了知其然,知其所以然。
关注我,这里只有干货!









