前言
一般的类和方法,使用的都是具体的类型:基本类型或者自定义的类。如果我们要编写出适用于多种类型的通用代码,那么肯定就不能使用具体的类型。前面我们介绍过多态,多态算是一种泛化机制,但是也会拘泥于继承体系,使得代码不够通用。我们应该是希望编写更通用的代码,使代码可以应用于“某种不具体的类型”,而不是一个具体的接口或者是类。
于是Java SE5便引入了“泛型”。泛型实现了参数化类型的概念,使代码可以应用于多种类型。泛型出现在编程语言中最初的目的就是希望类或者方法具有更广泛的表达能力。我们将通过解耦类或者方法所使用的类型类型之间的约束来实现这个目的。
Java中的泛型机制引入的比较晚,相较与如C++之类的语言产生的一开始便具备泛型的编程语言来说,是比较局限的。下面将介绍Java中泛型的基本机制、实现原理以及其局限之处。
简单的泛型类
引入泛型有很多原因,其中最重要的原因便是为了创建容器类。一般持有单个对象的类,可以明确指定其持有的对象类型。
class AppleJuice{}public class Cup1{ private AppleJuice aj; public Cup1(AppleJuice aj) { this.aj = aj; } public AppleJuice get() { return this.aj; }
}我们可以看出Cup1类的可重用性并不好,它只能持有单一的AppleJuice类型,若是想持有OrangeJuice类型对象则需要重新写一个类。
在Java SE5之前可以让这个类持有Object类型对象,使得这个类存储任何类型的对象。因为Object类是所有类的基类,那么就可以使用向上转型,使用基类引用去指向这些子类对象。
class AppleJuice{}class OrangeJuice{ public String toString() { return "OrangeJuice"; }
}public class Cup2 { private Object juice; //使用Object类型引用
public Cup2(Object juice) {
this.juice = juice;
} public Object get() { return juice; } public void set(Object otherJuice) { this.juice = otherJuice;
} public static void main(String[] args) {
Cup2 cup = new Cup2(new AppleJuice());
cup.set(new OrangeJuice());
System.out.println((OrangeJuice)cup.get());
}
}/*
output:
OrangeJuice
*/以上便是使用一个Cup2对象存储先后存储了两个不同类型的对象。某些情况下,我们确实希望容器能持有多种类型的对象。但是,通常而言,我们只会使用容器来存储一种类型的对象。泛型的主要目的之一便是:用来指定容器要持有什么类型的对象,而且由编译器来保证类型的正确性。
与其使用Object类型,更偏向于不指定类型,在要使用时再决定使用什么类型。为达到这个目的,需要使用类型参数,用尖括号括住,放在类名后面,类型参数名没有要求但一般是大写单字母T或者是其他字母(个人认为可能是模仿C++中的模板)。然后在使用这个类的时候,再用实际的类型替换此类型参数。例如:
public class Cup3 <T>{ private T juice; public Cup3 ( T juice) { this.juice = juice;
} public void set(T otherJuice) { juice = otherJuice;} public T get() { return juice;} public static void main(String[] args) {
Cup3<AppleJuice> cup = new Cup3<AppleJuice>(new AppleJuice());
AppleJuice appleJuice = cup.get(); //不需要再向下转型// cup.set(new OrangeJuice()); Error
}
}在Cup3对象中可以存入指定在<>中的类型以及其子类型对象(多态和泛型不冲突)。并且我们注意到,我们在取出对象时不用像使用Object时需要强制类型转换。
使用泛型自定义堆栈类
在上一篇博客中提到,LinkedList类拥有实现Stack的方法,可以使用LinkedList实现一个栈。现在我们不使用LinkedList,自己来实现链式存储的栈。
public class LinkedStack<T> { //结点
private static class Node<U>{
U item; //结点数据
Node<U> next; //指向下一个结点的引用
Node() { item = null; next = null;}
Node(U item, Node<U> next){ this.item = item; this.next = next;
} boolean end() { return item==null && next==null;
}
}
private Node<T> top = new Node<T>(); //末端哨兵
//压栈
public void push(T item) {
top = new Node<T>(item, top);
} //出栈
public T pop() {
T result = top.item; if(!top.end()) { //若top引用不是指向末端哨兵 则top指向next结点
top = top.next;
} return result;
}
public static void main(String[] args) {
LinkedStack<String> lStack = new LinkedStack<>();//可以省略后面的<>中的参数 编译器会依据前面<>中的参数推断
//压栈 压栈顺序为Happy Day !
for(String s : "Happy Day !".split(" ")) {
lStack.push(s);
}
String s; //出栈 出栈顺序为 ! Day Happy
while((s=lStack.pop()) != null) {
System.out.println(s);
}
}
}/*
!
Day
Happy
*/泛型接口
泛型也可以应用在接口中。例如生成器(generator),这是一种专门负责创建对象的类。生成器是工厂方法设计模式的一种应用。但是,使用生成器创建对象不需要传入任何参数,而工厂方法却需要参数。
一般而言,一个生成器只定义一个方法,该方法用于生成对象。这里定义next()方法完成此功能。
public interface Generator<T>{
T next();
}看泛型应用在接口中,与应用在类中并无差别。
Generator<T>接口可以生成Fibonacci数列的生成器实现:
public class FibonacciGenerator implements Generator<Integer>{ private int count = 0; public Integer next() { return fib(count++);
} private int fib(int n) { if(n < 2) return 1; return fib(n-2) + fib(n-1);
}
public static void main(String[] args) {
FibonacciGenerator fGen = new FibonacciGenerator(); for(int i=0; i<18; i++) {
System.out.print(fGen.next() + " ");
}
}
}/*
output:
1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 1597 2584
*/我们的类型参数是Integer,但是我们使用的数据类型却是int。是因为Java SE5具备了自动装箱和拆箱功能,使得基本类型可以转换为相应的包装器类型。这里就出现了Java泛型的一个局限性:基本类型无法作为类型参数使用。
点击我查看什么是装箱和拆箱
基本类型和它对应的封装对象之间的相互转换可以自动进行
装箱是指基本类型转换为对应的封装实例,比如int转换为java.lang.Integer
拆箱是指封装实例转换为基本类型,比如Byte转换为byte
我们还可以编写实现了Iterable的Fibonacci生成器。在实际开发中,若是我们拥有类源码则可以直接重写这个类,若是没有源码控制权,我们也可以通过适配器设计模式来实现所需要的接口。
下面将是两种方式的实现
public class IterableFibonacci1 implements Generator<Integer>, Iterable<Integer>{ private int count; private int n = 0;
public IterableFibonacci1(int count) { this.count = count;
}
public Integer next() { return fib(n++);
}
private int fib(int n) { if(n < 2) return 1; return fib(n-2) + fib(n-1);
} public Iterator<Integer> iterator() { return new Iterator<Integer>() { public boolean hasNext() { return count > 0;
} public Integer next() {
count--; return IterableFibonacci1.this.next();
}
};
}
public static void main(String[] args) { for(Integer i : new FibonacciGenerator(18)) {
System.out.print(i +" ");
}
}
}使用适配器模式(继承原有类,在原有类的基础上增加新的接口,以达到我们想要完成的功能)
public class IterableGenerator2 extends FibonacciGenerator implements Iterable<Integer>{ private int n; public IterableGenerator2(int count) {
n = count;
} public Iterator<Integer> iterator() { return new Iterator<Integer>() { public Integer next() {
n--; return IterableGenerator2.this.next();
} public boolean hasNext() { return n > 0;
} public void remove() { //没有实现
throw new UnsupportedOperationException();
}
};
}
public static void main(String[] args) { for(int i : new IterableGenerator2(18)) {
System.out.print(i + " ");
}
}
}泛型方法
前面我们介绍了泛型应用于整个类上,其实泛型还可以单独的应用于方法上。泛型方法使得该方法可以独立于类而产生变化。以下,是一个基本的指导原则:如果只使用泛型方法就可以取代整个泛型类,那么就只应该使用泛型方法,它显得更加清楚明了。
要定义泛型方法,只需将泛型参数列表置于返回值之前:
public class GenericMethod { public <T> void print(T x) {
System.out.println(x.getClass().getName());
} public static void main(String[] args) {
GenericMethod gm = new GenericMethod();
gm.print(12);
gm.print("123");
gm.print(12.0);
}
}/*
output:
java.lang.Integer
java.lang.String
java.lang.Double
*/注意,在使用泛型类时,必须在创建对象的同时指定类型参数,但是使用泛型方法的同时却不必指明类型参数,编译器会帮我们推断出具体的类型,这也叫做类型参数推断(type argument inference)。如果调用gm传入的参数是基类数据类型,那么自动装箱机制就会被启用。
类型推断只对赋值操作有效,其他时候并不起作用。如果将泛型方法的调用结果传递给另一个方法,这时编译器并不会执行类型参数推断。
Java泛型的实现原理——擦除
看下面这个程序
public class ErasedTypeEquivalence { public static void main(String[] args) {
Class c1 = new ArrayList<String>().getClass();
Class c2 = new ArrayList<Integer>().getClass();
System.out.println(c1 == c2);
}
}/*
output:
true
*/若是在没有看见输出之前我们肯定认为ArrayList<String>和ArrayList<Integer>是不同的类型,但是输出显示它们是相同的类型。
看下面的例子,会对这个“奇怪”的现象进行更进一步说明:
class A {}class B {}class C <T> {}class D<P, M>{}public class LostInformation { public static void main(String[] args) {
List<A> list = new ArrayList<A>();
Map<A, B> map = new HashMap<A, B>();
C<B> c = new C<B>();
D<String, Integer> d = new D<String, Integer>();
System.out.println(Arrays.toString(list.getClass().getTypeParameters()));
System.out.println(Arrays.toString(map.getClass().getTypeParameters()));
System.out.println(Arrays.toString(c.getClass().getTypeParameters()));
System.out.println(Arrays.toString(d.getClass().getTypeParameters()));
}
}/*
output:
[E]
[K, V]
[T]
[P, M]
*/根据JDK文档的描述
TypeVariable<Class<T>>[] getTypeParameters() /*Returns an array of TypeVariable objects that represent the type variables declared by the generic declaration represented by this GenericDeclaration object, in declaration order. */
Class.getTypeParameters()将“返回一个TypeVariable对象数组,表示有泛型声明所声明的类型参数”,这个方法好像可以看出参数类型信息。可是我们从输出中只看见了参数占位符的标识符,没有具体的类型信息。
事实上,在Java中的泛型代码内部,我们无法获取任何有关泛型参数类型的信息。
我们可以知道类型参数标识符和泛型类型边界(后面介绍什么是边界)这类的信息,但是却取法知道用来创建某个特定实例的实际类型参数。
看了这些奇怪了例子,不禁想知道Java的泛型是怎样实现的。Java的泛型是使用擦除来实现的,这意味着在使用泛型时,任何具体的类型信息都会被擦除(若是没有定义边界,则会将类型擦除为Object类型),而唯一知道的就是自己在使用一个对象。因此,ArrayList<String>和ArrayList<Integer>在运行时事实上是相同的类型。这两种形式都被擦除成它们的“原生”类型,即ArrayList(或者说是ArrayList<Object>)。
定义擦除的边界
下面一个使用模板的C++示例
#include <iostream>using namespace std;template <class T> class Manipulator {
T obj;public:
Manipulator(T x) { obj = x; } void manipulate() { obj.f(); } //调用了未知类型对象的f()方法};class HasF {public: void f() { cout << "HasF::f()" << endl; }
};int main() {
HasF hf;
Manipulator<HasF> manipulator(hf);
manipulator.manipulate();
}/*
output:
HasF::f()
*/以上代码有一个比较奇怪的地方,maniplate()方法中,在obj上调用f()方法,它怎么知道参数类型T拥有f()方法呢?原来,在实例化这个模板的时候,C++编译器将进行检查,因此在Maniplator<HasF>被实例化的这一刻,它就看到了HasF有一个方法f()。若是没有,则会得到一个编译期错误,这样类型安全就得到了保证。这也就说明了,C++在模板实例化的时候是知道模板的参数类型的。
若是Java来实现这样的代码,这样的代码是不能编译的!

由于有了擦除,Java编译器无法将manipulate()必须能够在obj上调用f()这一需求映射到HasF用于f()这一事实上。为了可以调用f(),我们必须协助泛型类,给定泛型类的边界,以告知编译器只能接受遵循这个边界的类型。给定边界时重用了extend关键字。添加了边界后代码就可以运行了。

边界<T extends HasF>声明T必须具有类型HasF或者从HasF导出的类型。如果创建对象时符合这个要求,那么就可以安全地在obj上调用f()。
泛型类类型参数将擦除到它的第一个边界(它可能会有多个边界)。编译器实际上会将类型参数替换为它的擦除。上面的例子中,T擦除到了HasF,就好像是在类的声明中使用了HasF替换了T一样。
在这个例子中,其实泛型的作用没有多大我们其实可以使用以下代码代替以上泛型。
class Manipulator{ private HasF obj; public Manipulator(HasF x) { obj = x; } public void manipulate(){ obj.f(); }
}所以,只有我们希望代码跨多个类工作时,使用泛型才有所帮助。
擦除的原因——迁移兼容性
泛型类型只有在静态类型检查期间才出现,在此之后,程序中所有泛型类型都将被擦除,替换为它们的非泛型上界。例如,List<T>将被擦除为List,普通的类型变量在未指定边界的情况下将被擦除为Object类型。
擦除的核心动机是它可以使得泛化的客户端可以使用非泛化的类库,反之亦然,这常被称为“迁移兼容性”。允许非泛型代码与泛型代码共存,擦除使得这种向泛型的迁移称为可能。
边界处的检查与转型
因为有了擦除,在程序运行过程中,泛型类中的泛型类型将不会有任何意义
public class ArrayMaker<T> { private Class<T> kind; public ArrayMaker(Class<T> kind) { this.kind = kind;
}
@SuppressWarnings("unchecked")
T[] create(int size) { return (T[]) Array.newInstance(kind, size);
}
public static void main(String[] args) {
ArrayMaker<String> stringMaker = new ArrayMaker<>(String.class);
String[] stringArray = stringMaker.create(10);
System.out.println(Arrays.toString(stringArray));
}
}/*
output:
[null, null, null, null, null, null, null, null, null, null]
*/Array.newInstance()实际上没有拥有kind所蕴含的类型信息,所含有的类型信息为Object,向上例代码强转后,也没有得到令人满意的结果。

但是看下面在这个例子,往返回泛型类型对象之前,向其中添加一些信息,会不会得到令人满意的结果
public class FilledListMaker<T> {
List<T> create(T t, int n){
List<T> result = new ArrayList<T>(); for(int i=0; i<n; i++) {
result.add(t);
} return result;
}
public static void main(String[] args) {
FilledListMaker<String> stringMaker = new FilledListMaker<>();
List<String> list = stringMaker.create("Hello", 4);
System.out.println(list);
}
}/*
output:
[Hello, Hello, Hello, Hello]
*/从代码中我们可以看出,即使编译器无法知道有关create()中T的任何信息,但是它仍旧可以在编译时期确保你放置到result中的对象具有T类型,使其适合ArrayList<T>。因此,即使擦除在方法或类内部移除了有有关实际类型的信息,编译器仍旧可以确保方法或类使用的类型的内部一致性。那么该如何确保呢?
因为擦除在方法体中移除了类型信息,所以在运行时的问题就是边界:对象进入和离开方法的地点。(此边界和类型参数的边界不同)这些正是编译器在编译期执行类型检查并插入转型代码的地点。
擦除的补偿——类型标签
泛型类中创建泛型类型对象不成功

因为擦除会丢失确切信息,所以在运行时需要知道确切类型信息的操作都将无法完成。但是,我们可以引入类型标签来暂时避免这种问题,对擦除机制进行补偿。类型标签就是可以用来表示当前类型的对象。我们可以在方法中显示传递类型的Class对象,以便在我们需要使用确切类型机制时使用。
class Building {}class House extends Building {}public class ClassTypeCapture<T> {
Class<T> kind; //引入类型标签
public ClassTypeCapture(Class<T> kind) { this.kind = kind;
} public boolean f(Object arg) { return kind.isInstance(arg);
} public static void main(String[] args) {
ClassTypeCapture<Building> ctc = new ClassTypeCapture<>(Building.class);
System.out.println(ctc.f(new Building()));
System.out.println(ctc.f(new House()));
ClassTypeCapture<House> ctc2 = new ClassTypeCapture<>(House.class);
System.out.println(ctc2.f(new Building()));
System.out.println(ctc2.f(new House()));
}
}/*
output:
true
true
false
true
*/我们引入类型标签(即传入Class对象)后,便可以使用动态的isInstance()方法。我们需要注意,编译器会确保类型标签可以匹配泛型参数。
创建泛型类型实例
在Erased.java中出现如下错误:
T var = new T(); // Cannot instantiate the type T
部分原因是因为擦除,而另一部分原因是因为编译器不能验证T具有默认无参构造器。Java中想要在泛型类中创建类的实例的解决方案便是传入一个工厂对象,并使用它来创建实例。最便利的工厂对象就是Class对象,因此使用Class对象作为类型标签传入,那么就可以使用newInstance()来创建这个类型的对象。
class ClassAsFactory<T>{
T x; public ClassAsFactory(Class<T> kind) { try {
x = kind.newInstance(); //创建T类型的实例
} catch (Exception e) { throw new RuntimeException(e);
}
}
}class Employee{}public class InstantiateGenericType { public static void main(String[] args) {
ClassAsFactory<Employee> fe = new ClassAsFactory<>(Employee.class);
System.out.println("ClassAsFactory<Employee> succeeded.");
try {
ClassAsFactory<Integer> fi = new ClassAsFactory<>(Integer.class);
} catch (Exception e) {
System.out.println("ClassAsFactory<Integer> failed.");
}
}
}/*
output:
ClassAsFactory<Employee> succeeded.
ClassAsFactory<Integer> failed.
*/代码可以编译,但是创建Integer的实例却会失败,是因为Integer没有任何默认的构造器。这个错误不会再编译时发现,而是在运行时捕获。所以Sun的工程师们建议使用显示的工厂,并限制其类型,只能接受实现了这个工厂的类。
//工厂接口interface Factory<T>{ T create();
}//Integer工厂class IntegerFactory implements Factory<Integer>{ public Integer create() { return new Integer(7);
}
}class OtherClass{ //静态内部类工厂创建外部类对象
public static class FactoryOther implements Factory<OtherClass>{ public OtherClass create() { return new OtherClass();
}
}
}//生成泛型类型对象class GenericFactory<T> {
T x; public <F extends Factory<T>> GenericFactory(F factory) {
x = factory.create();
} //....}public class FactoryConstraint { public static void main(String[] args) { new GenericFactory(new IntegerFactory()); new GenericFactory(new OtherClass.FactoryOther());
}
}传入显示工厂的方法只是传入Class<T>的一种变体。实际上,两种方法都传递了工厂对象,Class<T>碰巧是內建的工厂。显示的工厂对象可以使我们获得编译时期的检查。
还有一种创建泛型类型对象的方法便是模板设计模式。下面示例中,create()是模板方法,create()在子类中定义,用来产生子类类型的对象。
abstract class GenericWithCreate<T>{ final T element; public GenericWithCreate() {
element = create();
} abstract T create();
}class Tree{}class Creator extends GenericWithCreate<Tree>{ Tree create() { return new Tree();
}
void f() {
System.out.println(element.getClass().getSimpleName());
}
}public class CreatorGeneric { public static void main(String[] args) {
Creator creator = new Creator();
creator.f();
}
}/*
output:
Tree
*/创建泛型数组
正如在Erased.java中看见的不可以创建泛型数组
T[] array1 = new T[SIZE]; // Cannot create a generic array of T
一般的解决方案是在任何想要创建泛型数组的地方都使用ArrayList:
public class ListOfGenerics <T> { private List<T> array = new ArrayList<T>(); public void add(T item){ array.add(item);} public T get(int index) { return array.get(index);}
}若是真想创建一个泛型数组,那么唯一的方式就是创建一个被擦除类型的新数组,然后对其转型。
public class GenericArray <T> { private T[] array; @SuppressWarnings("unchecked") public GenericArray(int size) {// array = new T[size]; //Cannot create a generic array of T
array = (T[]) new Object[size];
}
public void put(int index, T item) {
array[index] = item;
}
public T get(int index) {
System.out.println("array[index].getClass().getSimpleName() = " + array[index].getClass().getSimpleName()); return array[index];
}
public T[] rep() {
System.out.println("array.getClass().getSimpleName() = " + array.getClass().getSimpleName()); return array;
}
public static void main(String[] args) {
GenericArray<Integer> ga = new GenericArray<>(10);
// java.lang.ClassCastException: [Ljava.lang.Object; cannot be cast to [Ljava.lang.Integer;// Integer[] ia = (Integer[])ga.rep();
ga.put(0, 1);
ga.get(0);
Object[] oa = ga.rep();
}
}/*
output:
array[index].getClass().getSimpleName() = Integer
array.getClass().getSimpleName() = Object[]
*/我们不能创建array = new T[size];,所以我们创建了一个对象数组,并将其转型。rep()方法返回的是T[],那么在main()中,按理说会返回Integer[],但是却出现ClassCastException,这只能说明程序实际运行时,数组的类型为Object。
因为有了擦除,数组运行时的类型就只能是Object。如果我们立即将其转型为T[],那么在编译期该数组的类型就会丢失,而编译器可能会错过某些潜在的错误检查。正是因为这样,最好在集合内部就使用Object[],然后使用数组元素时再添加一个对T的转型。
public class GenericArray2<T> { private Object[] array;
public GenericArray2(int size) {
array = new Object[size];
}
public void put(int index, T item) {
array[index] = item;
}
@SuppressWarnings("unchecked") public T get(int index) {
System.out.println("array[index].getClass().getSimpleName() = "+ array[index].getClass().getSimpleName()); return (T) array[index];
}
@SuppressWarnings("unchecked") public T[] rep() {
System.out.println("array.getClass().getSimpleName() = "+ array.getClass().getSimpleName()); return (T[]) array;
}
public static void main(String[] args) {
GenericArray2<Integer> ga2 = new GenericArray2<>(5);
ga2.put(0, 7);
ga2.get(0); try {
Integer[] ia = ga2.rep();
} catch (Exception e) {
System.out.println(e);
}
}
}/*
array[index].getClass().getSimpleName() = Integer
array.getClass().getSimpleName() = Object[]
java.lang.ClassCastException: [Ljava.lang.Object; cannot be cast to [Ljava.lang.Integer;
*/在调用rep()时,尝试将Object[]转换为T[],是不正确的。因此,没有任何方式推翻底层的数组类型,它只能是Object[]。将内部数组类型作为Object而不是T[],是使我们可以随时记着泛型类中数组运行时的类型为Object。
其实,我们真正要创建泛型数组,应该要想创建泛型类对象一样,传入一个类型参数(类型标记)。
public class GenericArrayWithTypeToken <T>{ private T[] array;
@SuppressWarnings("unchecked") public GenericArrayWithTypeToken(Class<T> type, int size) {
array = (T[]) Array.newInstance(type, size);
}
public void put(int index, T item) {
array[index] = item;
}
public T get(int index) { return array[index];
}
public T[] rep() {
System.out.println("array.getClass().getSimpleName() = "+ array.getClass().getSimpleName()); return array;
}
public static void main(String[] args) {
GenericArrayWithTypeToken<Integer> ga = new GenericArrayWithTypeToken<>(Integer.class, 7);
Integer[] ia = ga.rep();
}
}/*
output:
array.getClass().getSimpleName() = Integer[]
*/类型标记Class<T>被传入到构造器中,以便从擦除中恢复,使得我们可以创建需要的实际类型的数组。
边界
我们在“定义擦除的边界”那儿提到了边界。边界使得我们可以在泛型的类型参数上设置限制条件:可以强制泛型可以应用的类型,以及可以按照自己的边界来调用方法。
因为擦除机制移除了类型信息,所以若是没有给类型参数指定边界,那么调用的方法就只能是Object的方法。若是将类型参数限制为某个类的子集,那么我们就用这些子集来调用这个类的方法。为了执行这种限制,Java泛型重用了extends关键字(需要注意与继承关系中的含义区分)。
下面示例展示了边界的基本要素:
import java.awt.Color;interface HasColor {
java.awt.Color getColor();
}class Colored <T extends HasColor>{
T item; public Colored( T item) { this.item = item; } T getItem() {return item;} //有了边界 允许调用getColor()方法
Color color(){ return item.getColor();}
}class Dimension { public int x, y, z;}//多边界 类要放在第一个 接口放在后面//class ColoredDimension<T extends HasColor & Dimension> class ColoredDimension <T extends Dimension & HasColor>{ //...}interface Wight{int wight();}//拥有多个边界的泛型类 多边界只能有一个具体类 但是可以有多个接口class Solid <T extends Dimension & HasColor & Wight>{
T item; public Solid(T item) { this.item = item; } T getItem() { return item;} Color color(){ return item.getColor();} int getX() {return item.x; } int getY() {return item.y; } int getZ() {return item.z; } int weight() {return item.wight(); }
}class Bounded extends Dimension implements HasColor, Wight{ public int wight() { return 0; } public Color getColor() { return null;}
}public class BasicBounds { public static void main(String[] args) {
Solid<Bounded> solid = new Solid<>(new Bounded());
solid.color();
solid.getX();
solid.weight();
}
}泛型类的类型参数被限制为多边界时,具体类要放在第一个,接口放在后面
多边界时,具体类只能有一个,可以有多个接口
通配符
在介绍通配符之前,我们先举一个关于数组的特殊例子:使用基类的引用指向子类的对象,将导致一些问题
class Fruit{}class Apple extends Fruit{}class Jonathan extends Apple{}class Orange extends Fruit{}public class CovriantArrays { public static void main(String[] args) {
Fruit[] fruit = new Apple[10];
fruit[0] = new Apple();
fruit[1] = new Jonathan();
try {
fruit[2] = new Fruit();
}catch (Exception e) {
System.out.println(e);
}
try {
fruit[3] = new Orange();
} catch (Exception e) {
System.out.println(e);
}
System.out.println(fruit.getClass().getSimpleName());
}
}/*
java.lang.ArrayStoreException: blogTest.Fruit
java.lang.ArrayStoreException: blogTest.Orange
Apple[]
*/我们将Apple数组赋值给Fruit数组,是因为Apple也是一种Fruit。我们将Fruit放到Fruit数组中,这是被编译器允许的,因为引用类型就是Fruit。向Fruit中添加Orange也是被允许的,因为Orange也是一种Fruit。虽然在编译时期,这种赋值是被允许的,但是在运行时期却抛出了异常。原因是因为,运行时期数组机制知道它处理的是Apple[],添加除Apple以及Apple子类之外的对象都是不允许的。数组对象可以保留它们包含的对象类型的规则。
对数组的这种赋值,将在运行时期才可以看出错误。但是泛型的主要目标之一就是将这种错误检查移入到编译期!当我们使用泛型容器代替以上数组时:
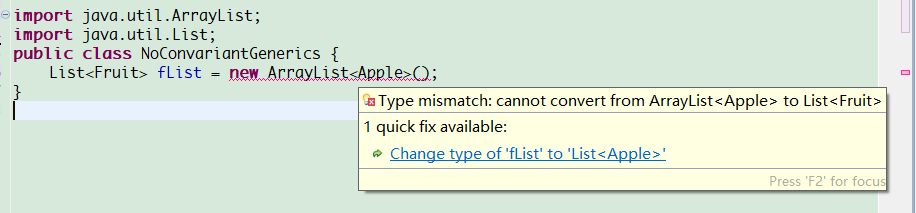
编译时的报错信息为:不能将一个Apple容器赋值给一个Fruit容器。但是更准确的说法是:不能将一个涉及Apple的泛型赋值给一个涉及Fruit的泛型。
我们讨论的是容器的类型,不是容器持有的类型,所以Apple的List不是Fruit的List。与数组不同,泛型没有內建的协变类型。数组中Apple可以赋值给Fruit,是因为编译器知道Apple是Fruit的协变类型,因此可以向上转型。泛型中,若是想在两个类之间建立类似这种向上转型的关系,就需要使用通配符(即类型参数中的?)。

List<? extends Fruit>可以理解为:具有任何从Fruit继承的类型的列表。这样的List持有的类型将是不稳定的,编译器无法确保可以安全地向其中添加对象。
返回一个Fruit则是安全的,因为列表中存的就是Fruit或者其子类。
查看List的实现源码,我们可以发现add()的参数会变成? extends Fruit,因此编译器不能知道需要Fruit的哪个子类型,因此它不会接受任何的Fruit。编译器将直接拒绝对参数列表中涉及通配符的方法的调用(例如add())。
超类型通配符
若是我们想向基类型列表中写入子类型,完成上述add()方法的功能,那么我们可以使用超类型通配符。这里,可以声明通配符是由某个特定类的任何基类来界定的,方法是指定<? super MyClass> 或者使用类型参数<? super T>(但是不能对泛型类型参数给出一个超类型边界,即不能声明<T super MyClass>)。这样,我们便可以安全地传递一个类型对象到泛型类型中。因此,有了超类型通配符,我们可以做如下插入:
public class SuperTypeWildcards{ static void writeTo(List<? super Apple> apples){
apples.add(new Apple());
apples.add(new Jonathan()); // apples.add(new Fruit()); //Error
}
}我们可以向apples中添加Apple或者Apple的子类型是安全的。
超类型边界放松了在可以向方法传递参数上所做的限制!
public class GenericWriting {
static List<Apple> apples = new ArrayList<Apple>(); static List<Fruit> fruits = new ArrayList<Fruit>();
static <T> void writeExact(List<T> list, T item) {
System.out.println(item.getClass().getSimpleName());
list.add(item);
}
//在“精确”类型下 也可以向fruit中添加对象
static void f1() {
writeExact(fruits, new Fruit());
writeExact(fruits, new Apple());
writeExact(fruits, new Orange());// writeExact(fruits, new Object()); //Error
}
static <T> void writeWithWildcard(List<? super T> list, T item) {
System.out.println(item.getClass().getSimpleName());
list.add(item);
}
static void f2() {
writeWithWildcard(fruits, new Fruit());
writeWithWildcard(fruits, new Apple());
writeWithWildcard(fruits, new Orange());// writeWithWildcard(fruits, new Object()); //Error
}
public static void main(String[] args) {
f1();
System.out.println("--------------");
f2();
}
}/*
output:
Fruit
Apple
Orange
--------------
Fruit
Apple
Orange
*/Java编写思想中
writeExact(fruits, new Apple());或者 writeExact(fruits, new Orange());
在“精确”类型中是不可以向列表中添加的,然而在JDK 1.8上运行,确实是可以添加的。看来是做了优化?还是我理解理解错了?这里暂时有点迷惑。望各位看官解答。
我们在做一个相同的联系,对协变和通配符做一个复习,也与超类型通配符比较下:
public class GenericReading {
//Arrays.asList()生成大小不可变的列表
static List<Apple> apples = Arrays.asList(new Apple()); static List<Fruit> fruits = Arrays.asList(new Fruit());
//使用“精确”的泛型
static class Reader<T> { T readExact(List<T> list) {
System.out.println(list.get(0).getClass().getSimpleName()); return list.get(0);
}
}
static void f1() {
Reader<Fruit> fruitReader = new Reader<Fruit>();
Fruit f = fruitReader.readExact(fruits);// Fruit a = fruitReader.readExact(apples); //Error
}
//协变
static class CovariantReader<T> { //可以接受T类型或者是T导出的类型
T readCovariant(List<? extends T> list) {
System.out.println(list.get(0).getClass().getSimpleName()); return list.get(0);
}
}
static void f2() {
CovariantReader<Fruit> fReader = new CovariantReader<>();
Fruit f = fReader.readCovariant(fruits);
Fruit a = fReader.readCovariant(apples);
}
public static void main(String[] args) {
f1();
System.out.println("---");
f2();
}
}/*
output:
Fruit
---
Fruit
Apple
*/个人的理解,<? extends T> 常用于一个泛型类型中“读取”(从一个方法返回);<? super T> 常用于向一个泛型类型“写入”(传递给一个方法)。
无界通配符
无界通配符<?>表示具有某种特定类型,不过暂时还未知,与Object类型还是有区别的。
自限定类型
在Java泛型中,有这样一个奇怪的惯用法:
class SelfBounded<T extends SelfBounded<T>>
SelfBounded将接受一个泛型参数T,这个T由一个边界限定,而这个边界就是拥有T作为其参数的SelfBounded。这样的使用方法一眼看去有点难以理解,我们看看下面的解释,就会理解这种用法的效果了。
古怪的循环泛型
为了理解自限定类型的含义,我们先从这个惯用法的一个简单版本入手,它没有包含自限定的边界(即 不包含extends SelfBounded<T>这句代码)。
我们不能直接继承一个带有类型参数的泛型类,但是我们却被允许继承 将自己的类作为类型参数传给泛型类的这种情况
即:
class GenericType<T>{}public class CuriouslyRecurringGeneric extends GenericType<CuriouslyRecurringGeneric>{}我们称这个为古怪的循环泛型(CRG)来源C++中古怪的循环模板模式的命名方式。“古怪的循环”指的是当前类出现在基础的基类中。
那么这个泛型基类有什么作用呢?
我们可以产生 使用导出类作为泛型基类参数和泛型基类方法返回类型的 基类,还可以将导出类型作为基类的域类型,甚至那些将被擦除为Object的类型。 下面举例说明:
class BasicHolder<T>{
T element; void set(T arg) {element = arg;} T get() {return element;} void f() {
System.out.println(element.getClass().getSimpleName());
}
}class SubType extends BasicHolder<SubType>{}public class CRGExample { public static void main(String[] args) {
SubType t1 = new SubType();
SubType t2 = new SubType();
t1.set(t2);
SubType t3 = t1.get();
t1.f();
}
}/*
output:
SubType
*/我们需要注意:新类SubType接受的参数和返回的值具有SubType类型,而不仅仅是基类BasicHolder类型。所以CRG的核心在于:基类用导出类代替其参数。可以说泛型基类变成了一种其所有导出类的公共功能的模板,但是这些功能的所有参数和返回值将使用导出类型。
但是BasicHolder可以使用任何类型作为其泛型参数,我们即将要介绍的自限定则可以强制将正在定义的类作为自己的边界参数使用。
自限定
class SelfBounded<T extends SelfBounded<T>>{
T element; public SelfBounded<T> set(T arg) {
element = arg; return this;
}
public T get() { return element;
}
}class A extends SelfBounded<A>{}class B extends SelfBounded<A>{}class C extends SelfBounded<C>{ C setAndGet(C arg) {
set(arg); return get();
}
}//The type D is not a valid substitute for the bounded parameter <T extends SelfBounded<T>> of the type SelfBounded<T>class D{}//class E extends SelfBounded<D>{}class F extends SelfBounded{}public class SelfBounding { public static void main(String[] args) {
A a = new A();
a.set(new A());
a = a.set(new A()).get();
a = a.get();
C c = new C();
c = c.setAndGet(new C());
}
}自限定要求的就是在继承关系中,像下面这样使用这个类:
class A extends SelfBouned<A>
那么我们又想知道自限定的参数有什么作用呢?
它可以保证参数类型必须与正在被定义的类相同!
我们从代码中可以看出虽然可以使用,B虽然可以继承从SelfBounded导出的A,但是B类中的类型参数都是为A类。A类的那种继承为最常用的用法。对E类进行定义说明不能使用不是SelfBounded的类型参数。F可以编译,不会有任何警告,说明自限定惯用法不是可强制执行的。
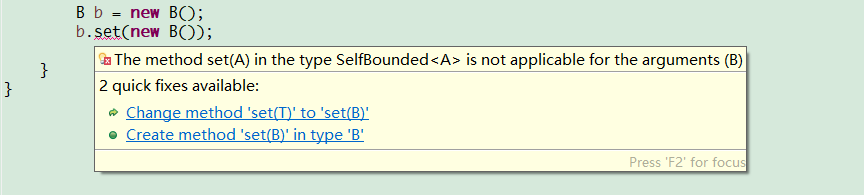
自限定类型只能强制作用于继承关系,如果使用了自限定,就应该了解这个类的所有类型参数将与使用这个参数的类具有相同类型。即类型参数与类具有相同类型。
还可以将自限定用于泛型方法:
public class SelfBoundingMethods{ static <T extends SelfBounded<T>> T f(T arg){ return arg.set(arg).get();
} public static void main(String args[]){
A a = f(new A());
}
}这可以放置这个方法被应用于除以上形式的自限定类型参数之外的任何事物上。
参数协变
自限定类型的价值在于:可以产生协变参数类型(方法参数类型会随着子类而变化)。
class GenericGetter<T extends GenericGetter<T>>{
T element; void set(T element) { this.element = element; } T get() { return element; }
}class Getter extends GenericGetter<Getter>{
}public class GenericAndReturnTypes { static void test(Getter g) {
Getter result = g.get();
GenericGetter genericGetter = g.get();
}
public static void main(String[] args) {
Getter getter = new Getter();
test(getter);
}
}但是在非泛型代码中,参数类型却不可以随子类变化而变化。
class Base{}class Derived extends Base{}class OrdinarySetter{ void set(Base base) {
System.out.println("OrdinarySetter.set(Base)");
}
}class DerivedSetter extends OrdinarySetter{ void set(Derived derived) {
System.out.println("DerivedSetter.set(Derived)");
}
}public class OrdinaryArguments { public static void main(String[] args) {
Base base = new Base();
Derived derived = new Derived();
DerivedSetter ds = new DerivedSetter();
ds.set(base);
ds.set(derived);
}
}/*
output:
OrdinarySetter.set(Base)
DerivedSetter.set(Derived)
*/ds.set(base);和ds.set(derived);都可以可以的,是因为DerivedSetter.set()没有重写OrdinarySetter.set()中的方法,而是重载了。于是DerivedSetter中含有两个set方法。ds.set(base);调用的是父类OrdinarySetter的set的。
但是使用自限定类型,在导出类中就只会有一个方法,并且这个方法接受导出类型而不是基类型为参数!!!
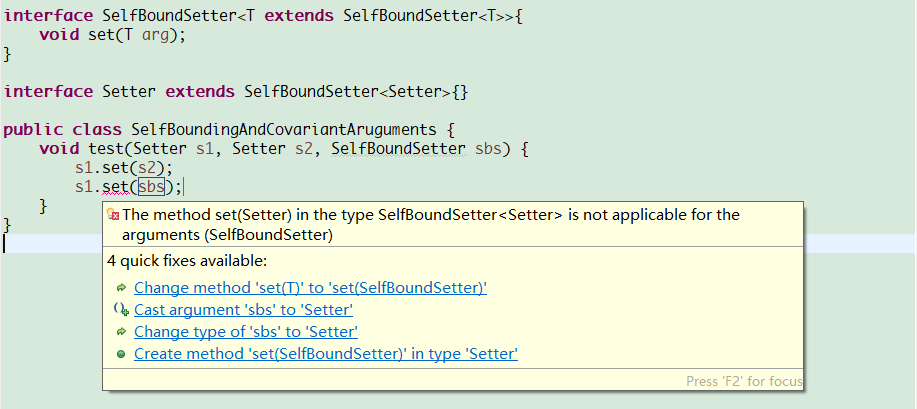
interface SelfBoundSetter<T extends SelfBoundSetter<T>>{ void set(T arg);
}interface Setter extends SelfBoundSetter<Setter>{}public class SelfBoundingAndCovariantAruguments { void test(Setter s1, Setter s2, SelfBoundSetter sbs) {
s1.set(s2); //The method set(Setter) in the type SelfBoundSetter<Setter>
//is not applicable for the arguments (SelfBoundSetter)
//s1.set(sbs);
}
}若是使用了自限定类型,基类型就不可以传入到子类型方法中。
若是不使用自限定类型,而使用普通泛型,则子类中就是重载基类的方法,结果就像在OrdinaryArguments.java中一样。

可以看出不使用自限定类型将重载参数,使用自限定类型将只能获得方法的一个版本,它将接受确切的参数类型。
小结
在看过《Java编程思想》对Java泛型的介绍后,总结了以上的内容。再次总体回顾,感觉到Java中的泛型还是有很多不足的。毕竟Java语言也不是一开始就有泛型,而且引入了泛型之后还有兼顾以前的旧代码。
于是泛型的实现原理就是在运行时将实际类型擦除为指定的第一个边界类型(未指定则擦除为Object),从而应用于多个类型。
擦除的代价也是显著的,不能用于显示地引用运行时类型信息的操作之中,例如转型、instanceof操作和new表达式。
然后介绍了类型擦除的补偿,可以指定类型标签,让泛型类知道确切类型
最后又总结了边界、通配符、自限定类型的含义以及用法
还有一个文中没有提到但是要知道的:不能不捕获泛型类型的异常,因为在编译时和运行时都必须要知道异常的确切类型,泛型类也不能直接或者间接继承Throwable,阻止定义不能捕获的泛型异常。
参考:
《Java编程思想》第四版
作者:SakuraOne