
使用抽象数据类型可以帮助我们更好的理解数据所需的操作,之后再进行具体的数据类型实现。实际上,往往是操作影响着我们决定数据类型该如何实现,这里有两种典型的数据结构-栈和队列。
本质上,栈和队列都是线性表,只是根据操作的需求我们人为地在线性表上加上限制,形成了两种具有独特功能的数据结构。
1、栈
首先,普通的线性表实现是有两个端口可以访问的,但是如果作为栈就要封闭一端,只能访问另一端。这当然不是自讨苦吃,栈是一种抽象数据结构,是对现实世界对象的模拟。比如,自助餐厅中的一叠盘子,新盘子放在这一叠盘子的最上面,取得时候也是从最上面取。将其抽象出来就是栈,这是最合适的抽象方式。
基于栈的操作非常简单:
将数据压入栈顶-push
将栈顶数据弹出-pop
查看栈顶数据-top
栈的实现不是难点,基于栈的操作也很简单,重点是栈的运用。
动态图:
栈的先进后出规则,本质上代表着数据的次序,常见的二叉树先序、中序、后序非递归遍历,其实就是借用这种规则实现的。想要深入理解栈,没有取巧的方法,见多识广用在这里再合适不过了,这里使用一个简单的例子来加深对栈的理解。
大整数加法,现在有个需求,将1856845129568452684和8948756841235879相加,怎么处理?这两个整数太大了,寻常的整数类型根本无法存储他们,更别说他们相加的结果。为了解决这个问题,可以将这种非常大的数看成一串数字,分别存到两个栈中,然后从栈中弹出数,进行加法操作。
伪代码如下:
largeNumAdd()
{
读第一个数的数字,并将这些数字压入到一个栈中;
读第二个数的数字,并将这些数字压入到另一个栈中;
carry = 0; //代表进位
while(至少有一个栈不为空)
从每个非空的栈中弹出一个数,将这两个数字与进位相加;
将和的个位数字压入到结果栈中;
将和的进位存到carry中;
如果进位不为0,将其压入到结果栈中;
从结果栈中弹出数字并显示;
}简单起见,这里给出456和7891相加时栈的结构:
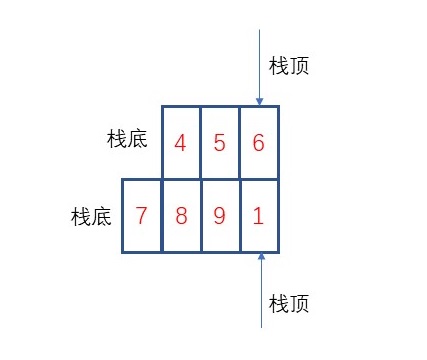
这不就是我们学过的加法计算公式嘛,是的,这里使用栈模拟了加法过程。
将数字压入栈中,其实维持了千位、百位、十位、个位之间的次序,正是这个原因才能保证栈弹出的时候数字相加是合理的。这只是栈简单的一种运用,在现实生活中,所有需要保持次序的数据,都可以使用栈这种先进后出的结构,通过巧妙的设计完成算法逻辑。
2、队列
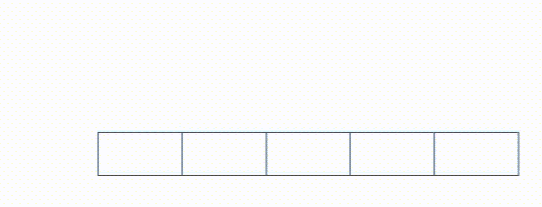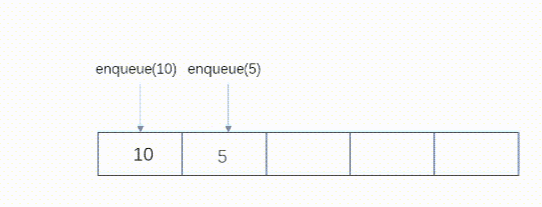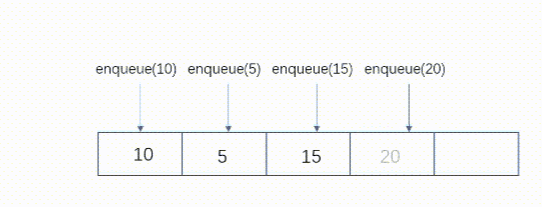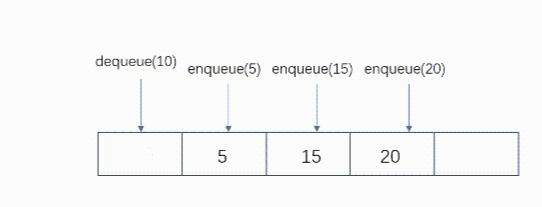
队列是一种简单的等待序列,在尾部加入元素时队列加长,在前端删除数据时队列缩短。与栈不同,队列是一种使用两端的结构:一端用来加入新元素,另一端用来删除元素。队列是先进先出的结构。
队列的操作与栈操作相似:
在队列尾部加入元素-enqueue(el)
取出队列的第一个元素-dequeue()
查看队列头部元素-firstEI()
动态图:
队列的实现:
队列的一种可能实现方式是使用数组,但这并非最佳选择。元素从队尾加入而从队首删除,这会释放数组中的某些单元,这些单元不应该浪费。一种可能的做法是使用循环数组,如果队尾已满而队首有空的单元,可以将新加元素放入队首,形成循环数组,这种做法是空间比较紧张时的无奈之举,因为它破坏了队列的简单易用性,所以不推荐。
队列的另一种可能实现是使用双向链表,那么执行入队列和出队列操作仅需要常数时间,并且没有数组实现中空间的浪费,因此,推荐这种方法。
队列的变种:
优先队列
在许多情况下,简单的队列结构是不够的,先入先出机制需要使用某些优先规则来完善。在邮政局中,残疾人应该比其他人享有一定的优先权。在进程队列中,由于系统的功能需求,即使在等待队列中进程P1在P2之前,P2也需要在P1之前执行。以此类推,需要一种修正的队列,这就是所谓的优先队列。
优先队列可以用两种链表的变种实现。一种变种是所有的元素按照进入顺序排序,出队时按照优先级。另一种是根据元素的优先级决定新增元素的位置。在这两种情况下,总的执行时间都是O(n),在标准库中使用后一种方式实现的,因为我们希望在元素出队时可以尽可能的快。
双端队列
顾名思义,双端队列就是可以在队列的两端压入、弹出元素。这就有问题了,双端队列和普通的数组、链表有什么区别?不都可以两端访问嘛。当然是有区别的,双端队列的产生是基于以下需求的。众所周知,数组和链表是线性表的两种实现方式,数组的优势在于可以常数时间内随机访问元素,链表的优势在于可以常数时间内在两端插入数据。那么,有没有一种实现方式可以综合这两个特点呢?答案是双端队列。
一切的奥妙在于双端队列的实现方式。首先从数组讲起,我们定义了数组A,数组A本身是支持常数时间内随机访问元素的,但是如果在头部插入数据,就会造成大量元素后移,这是不能容忍的。怎么解决呢?那就再定义一个数组B,如果在A头部插入新元素a,就将a放到数组B的尾端,这时候数组A和数组B都是被封装在双端队列中的,并且双端队列维护了一段链式结构,其中每个节点指向一个数组。看到这里想必大家已经明白,双端队列通过维护多个数组来避免头部插入操作造成的大量数据后移,尽管双端队列的实现比较复杂,但是作为使用者,既可以常数时间内随机访问元素,又可以常数时间内在队列两端插入数据,这对于某些场景下非常合适。
双端队列并不能取代数组和链表,因为数组和链表的实现简单、直观,可以满足大部分需求,只有在特殊场景下才去考虑双端队列,这就是所谓的对症下药。
3、标准库实现
这里简单介绍下标准库中的栈和队列。
在标准库中栈和队列是一种容器适配器。什么叫做容器适配器呢?其实就是拿一种已有的容器,在上面重新封装对外暴漏的接口,拼装成一种新的特殊容器。
标准库首先实现了双端队列,它是一种真正的容器,不是容器适配器。
标准库中的栈是一种容器适配器,默认是基于双端队列实现的,我们在使用过程中可以指定新的底层容器,比如向量或者链表。
标准库中的队列也是一种容器适配器,默认也是基于双端队列实现的,但是我们只能选择链表作为新的底层容器,不能选择向量。这是因为队列是允许在头部删除数据的,而向量没有实现这种操作。
标准库中的优先队列也是一种容器适配器,默认是基于向量实现的,但是我们也能选择使用双端队列作为底层容器。注意,这里不能选择链表,因为标准库中的优先队列要求底层容器提供随机访问迭代器,而链表并没有提供。所谓的随机访问迭代器是指通过该迭代器可以访问容器中任一元素,而链表的迭代器只能自增或者自减,并不能随机访问任一元素。
到此为止,栈和队列的相关概念已经探讨完毕,本文也只是浅尝辄止,更加深入的知识需要在实践中摸索获取,毕竟,成就在于个人。





