
数组是软件开发过程中非常重要的一种数据结构,但是数组至少有两个局限:
编译期需要确定元素大小
数组在内存中是连续的,插入或者删除需要移动数组中其他数据
数组适合处理确定长度的,对于插入或者删除不敏感的数据。如果数据是频繁变化的,就需要选择其他数据结构了。链表是一种逻辑简单的、实用的数据结构,几乎被所有程序设计语言支持。我们从最简单的链式结构开始,根据需求的变化一步步改进,满足产品需求。
1、单向链表
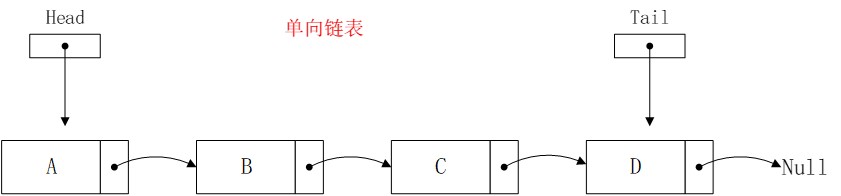
单向链表是由一个个节点组成的,每个节点是一种信息集合,包含元素本身以及下一个节点的地址。节点在内存中是非连续分布的,在程序运行期间,根据需要可以动态的创建节点,这就使得链表的长度没有逻辑上的限制,有限制的是堆的大小。在单向链表中,每个节点中存储着下一个节点的地址,就像这样:
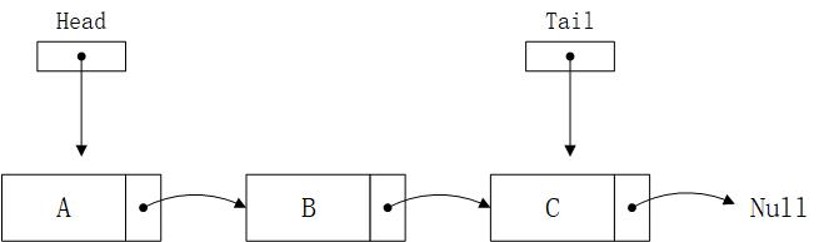
事实上,我们更加关注的是基于数据结构的算法,链表是一种简单的数据组织方式,适合中等数量的数据,我们考察链表的添加、删除、查找即可,更加复杂的操作需求最好使用更加高级的数据结构。
首先定义链表:
#ifndef INT_LINKED_LIST
#define INT_LINKED_LIST
class Node {
public:
//构造函数,创建一个节点
Node(int el = 0, Node* ptr = nullptr) {
info = el;
next = ptr;
}
//节点的值
int info;
//下一个节点地址
Node* next;
};
class NodeList {
public:
//构造函数,创建一个链表,用于管理节点
NodeList() {
head = tail = nullptr;
}
//节点插入到头部
void addToHead(int);
//节点插入到尾部
void addToTail(int);
//删除头部节点
int deleteFromHead();
//删除尾部节点
int deleteFromTail();
//删除指定节点
void deleteNode(int);
private:
//头指针、尾指针
Node *head, *tail;
};
#endif这里定义了两个class,分别用来表示节点以及管理节点的链表。其中,节点具有两个成员变量,分别是当前节点的值以及指向下个节点的指针。链表也具有两个成员变量,分别指向头结点以及尾节点。链表class具有5个成员方法,分别代表着节点的添加、删除、查找,我们来考察下这3种操作在链表中的表现。
单向链表的操作比较简单,这里直接使用动图来代替代码,更加易于理解。
假设已有链表如下:
节点插入到头部
节点插入到头部的逻辑比较简单,算法复杂度能在固定时间O(1)内完成,也就是说,无论链表中有多少个节点,该函数所执行操作的数目都不会超过某个常数c。注意,该操作的实现依赖head指针,否则无法确定头结点的地址,那么算法的复杂度将会大大增加。
节点插入到尾部
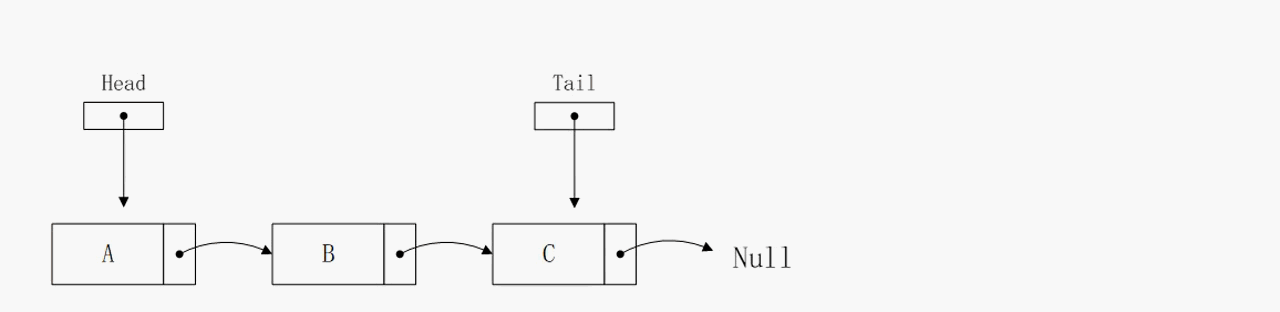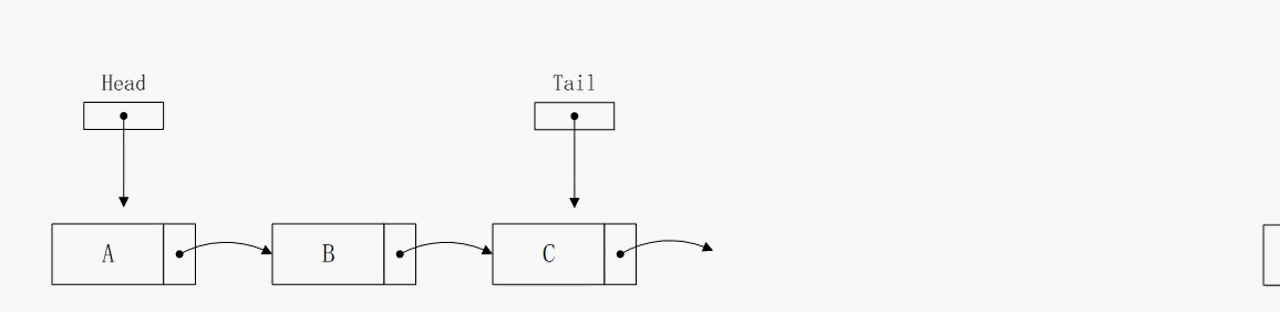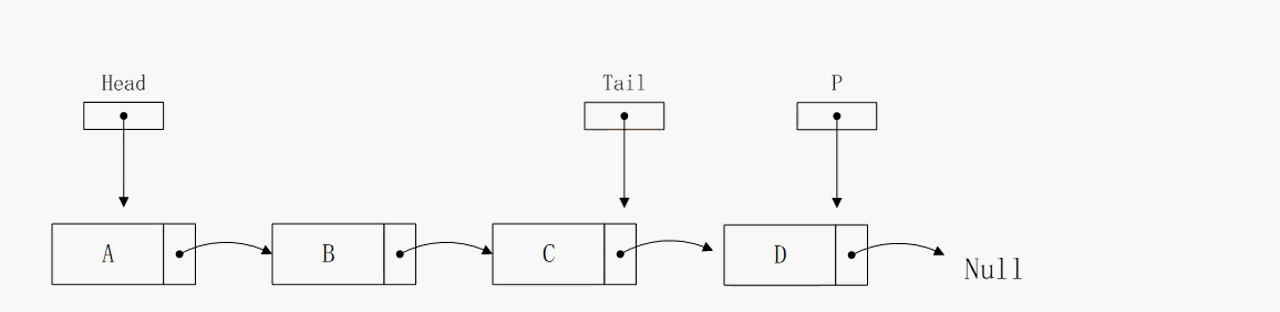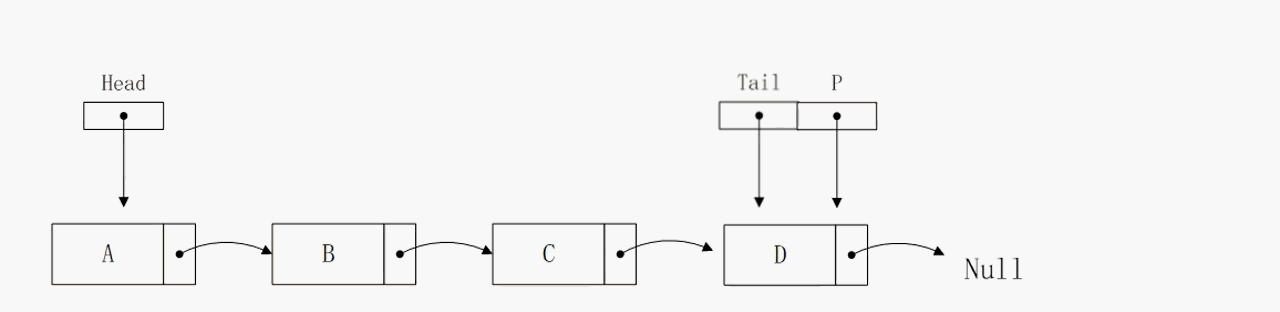
节点插入到尾部的逻辑和插入到头部相似,算法复杂度也是O(1),区别在于该操作的实现依赖tail指针,否则无法确定尾节点的地址,那么算法的复杂度将会大大增加。
删除头部节点
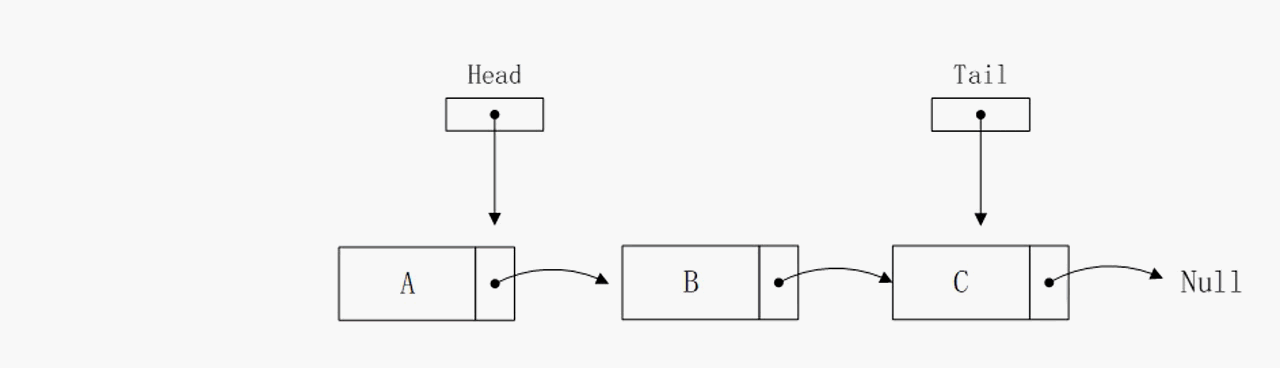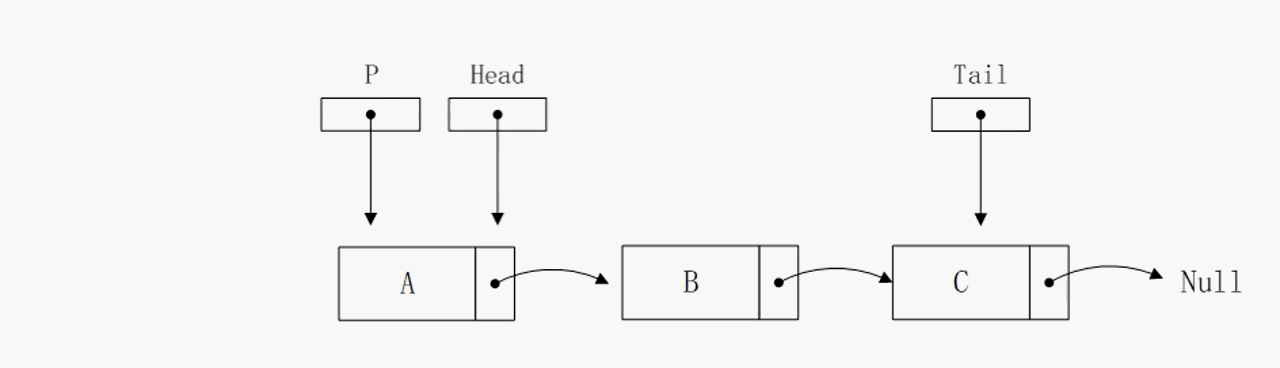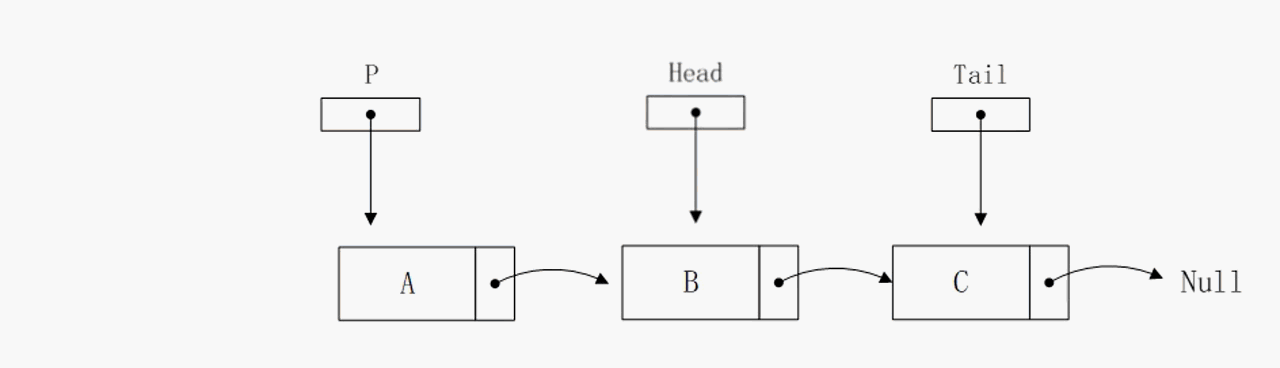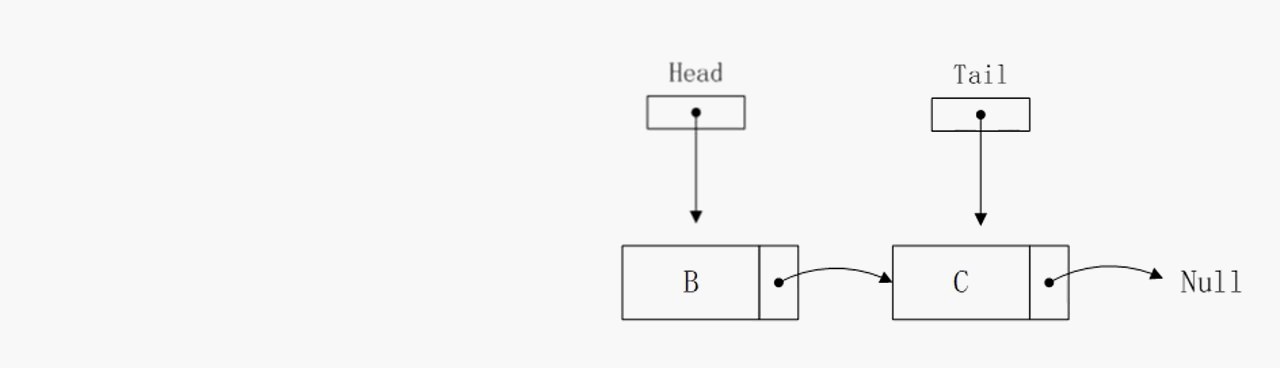
删除头部节点操作的算法复杂度也是O(1),该操作依赖head指针,通过head指针可以直接获取到下个节点的地址,所以复杂度很低。
删除尾部节点
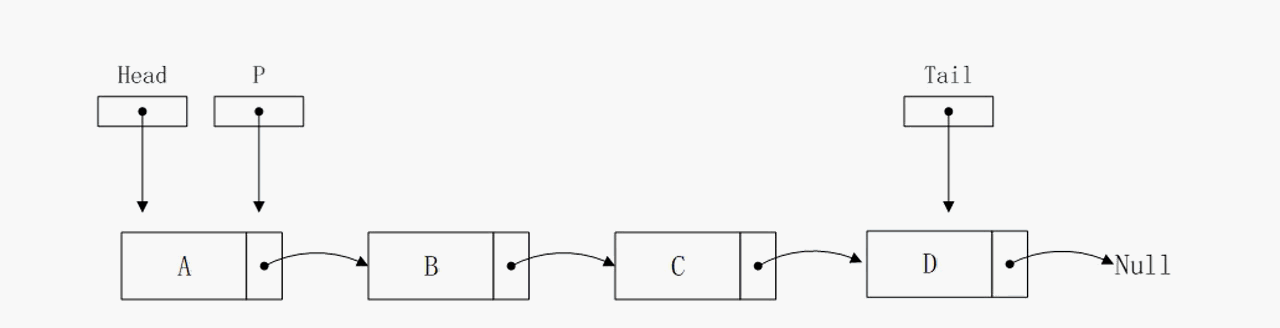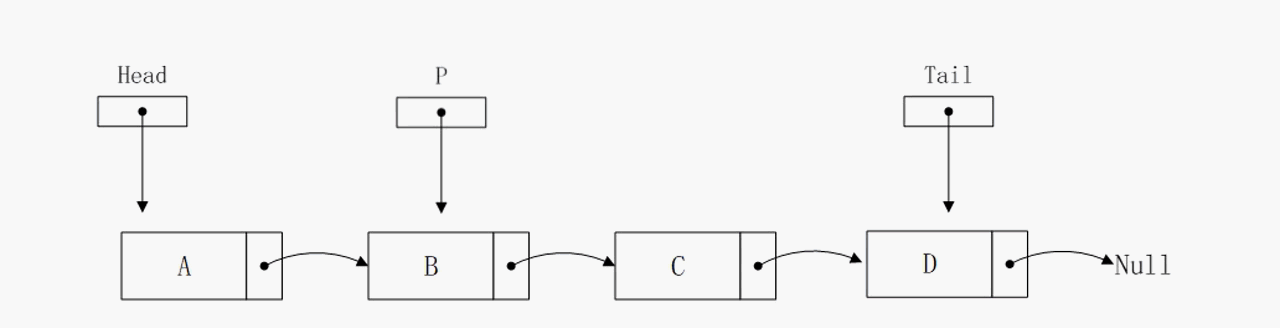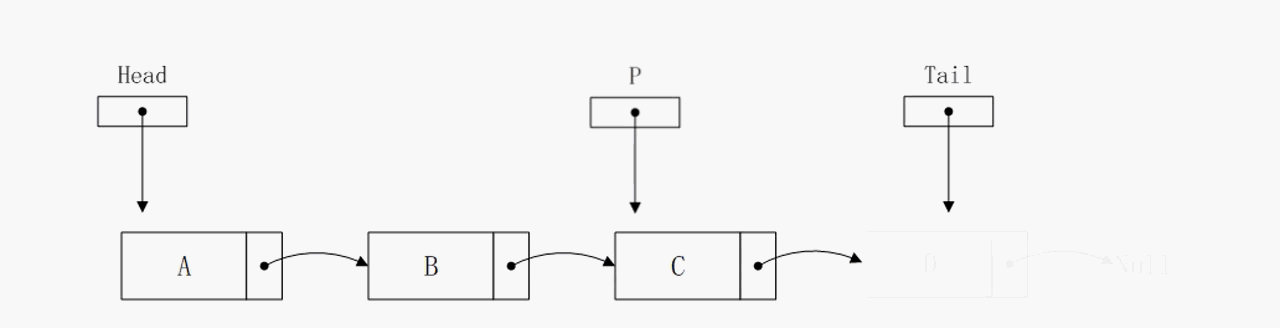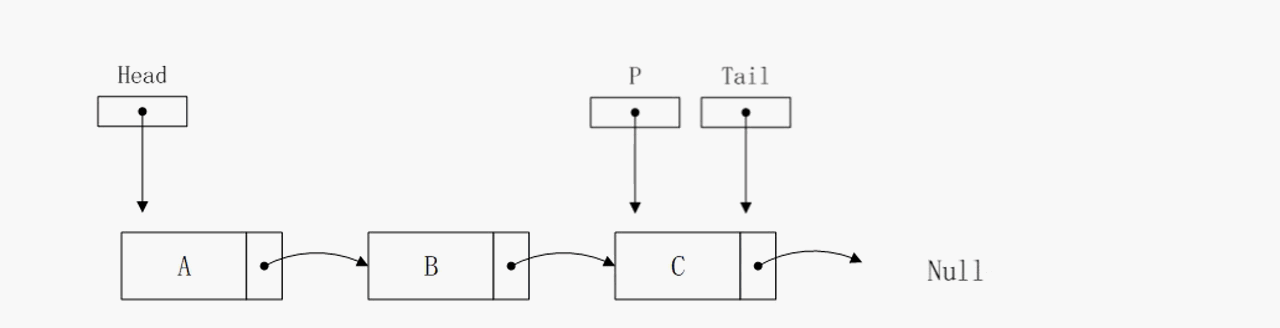
注意这里,删除尾部节点的算法复杂度是O(n),相比于前面的O(1),提升了两个量级。原因在于我们需要一个临时指针p,从头结点一直遍历到倒数第二个节点。因为删除尾节点之后,tail指针需要向头结点方向移动一次,但是在链表中不能直接获取到倒数第二个节点的地址,只能依靠遍历的方式,这就导致算法复杂度上升为O(n)。在单向链表中没有更好的解决方式了,在后面我们需要改进链表结构避免这种情况。
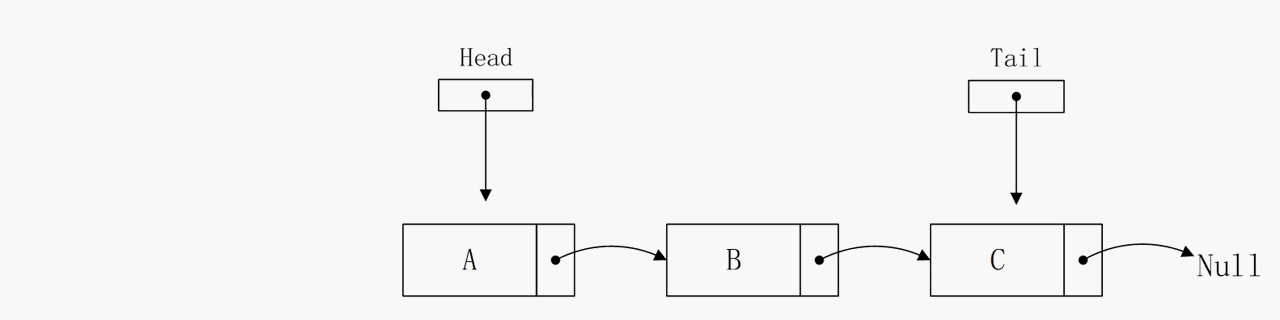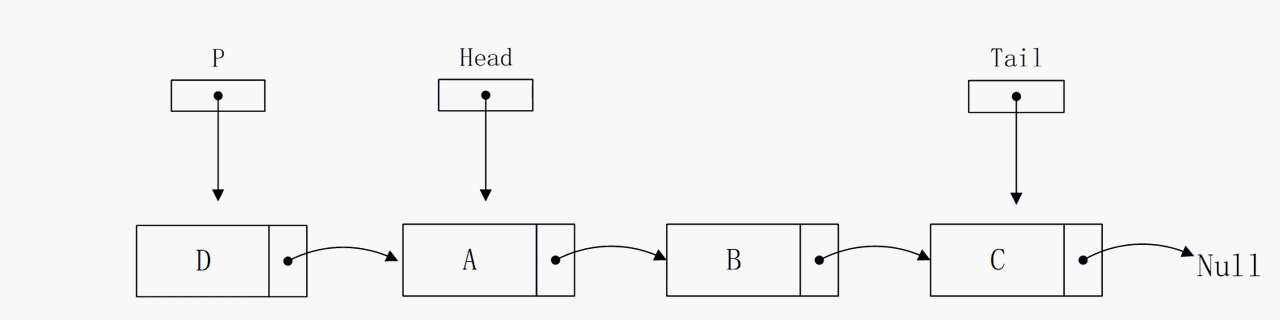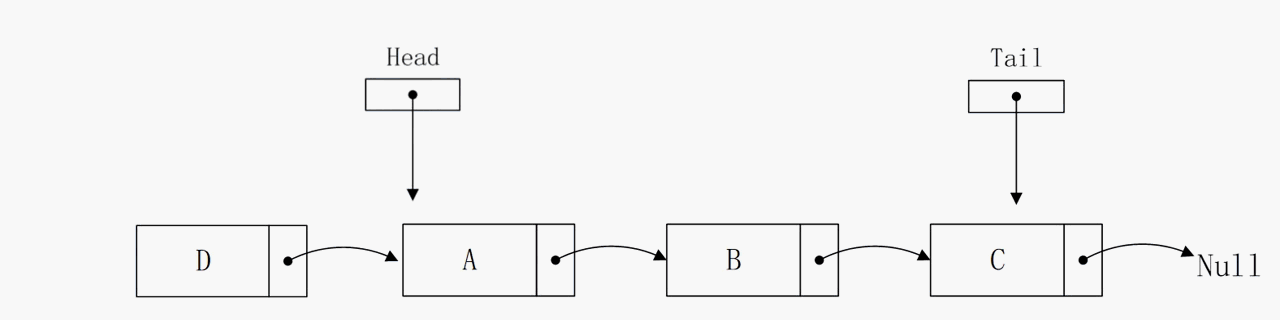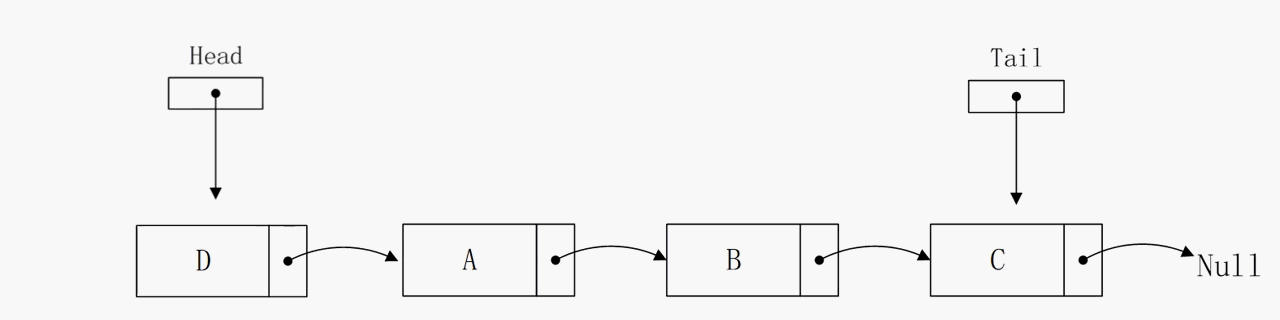
删除指定节点
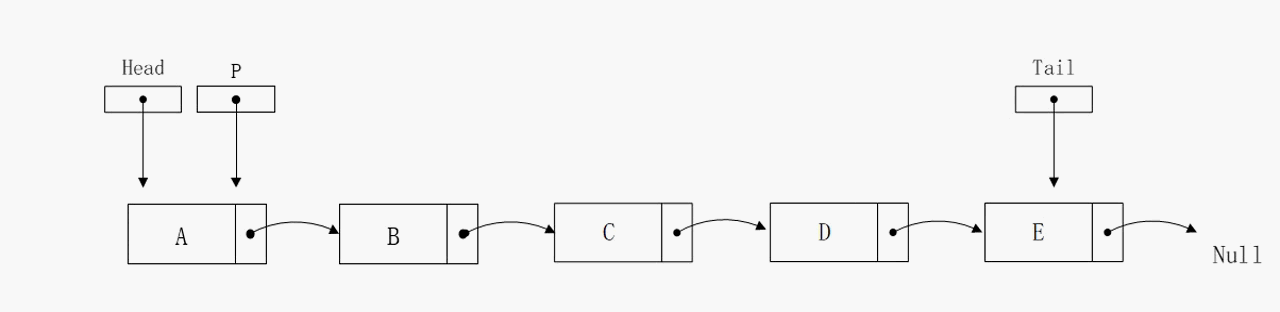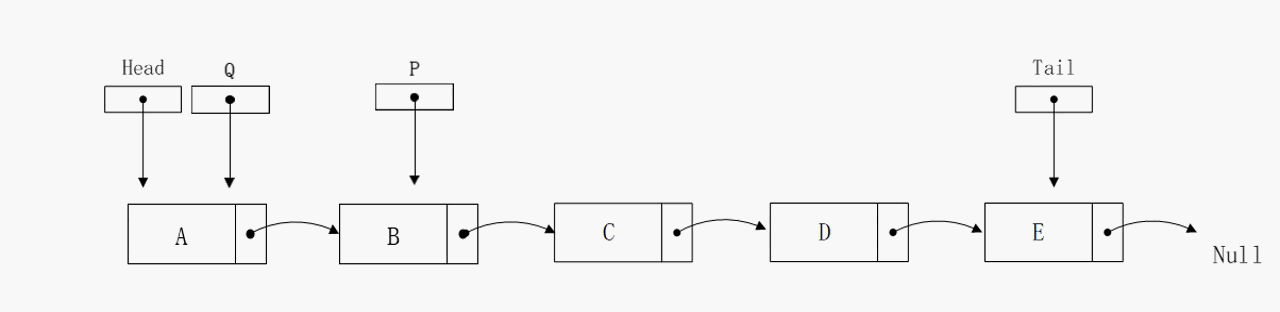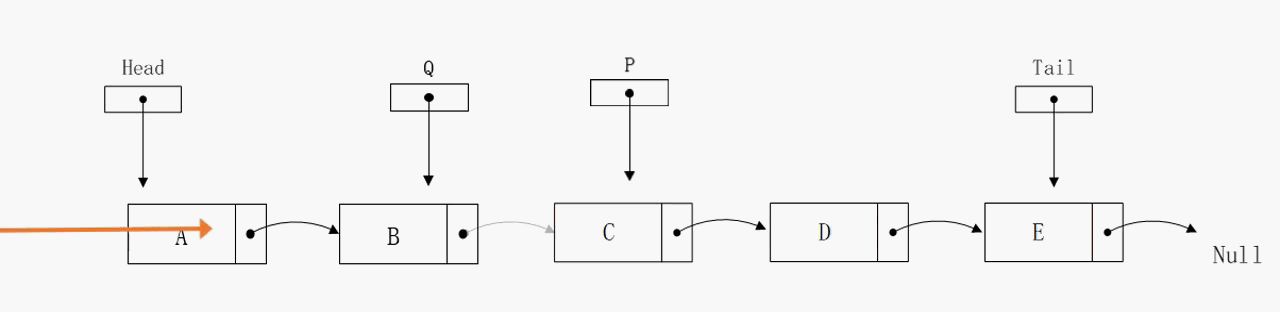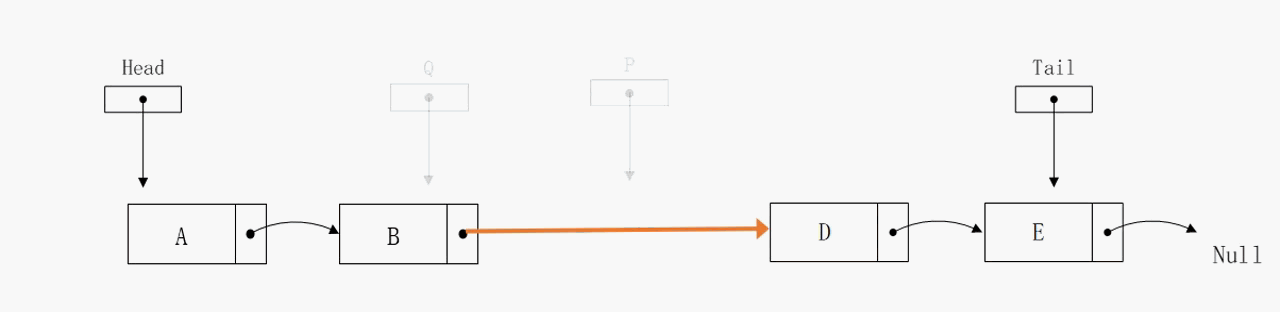
删除指定节点的算法复杂度也是不尽人意,在最好的情况下花费O(1)的时间,在最坏和平均情况下则是O(n)。通过动态图可以发现,我们定义P指针指向目标节点,定义Q节点指向目标节点的前驱节点。这两个变量的存在意义在于修正单向链表的指向,是不可或缺的。
基于单向链表的某些操作的算法复杂度无法满足我们的需求,这里主要指删除尾部节点以及删除指定节点,它们的平均复杂度达到了O(n),相比于O(1)增加了两个量级。为了改进算法,我们需要修改链表的结构。对于删除尾部节点来说,瓶颈在于无法直接获取尾节点的前驱节点地址,我们可以为节点加上一个指向前节点的指针来解决,这就是所谓的双向链表。
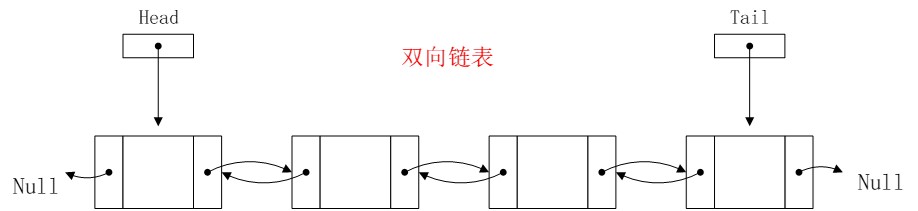
2、双向链表
双向链表是这个样子:
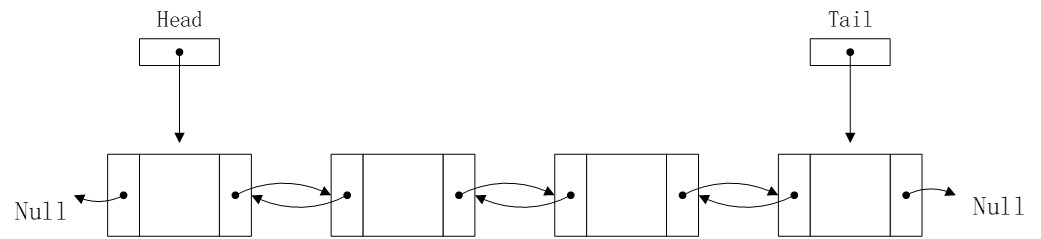
首先是定义:
#ifndef INT_LINKED_LIST
#define INT_LINKED_LIST
class Node {
public:
//构造函数,创建一个节点
Node(int el = 0, Node* p = nullptr, Node* q = nullptr) {
info = el;
pre = p;
next = q;
}
//节点的值
int info;
//前一个节点地址
Node* pre;
//下一个节点地址
Node* next;
};
class NodeList {
public:
//构造函数,创建一个链表,用于管理节点
NodeList() {
head = tail = nullptr;
}
//节点插入到头部
void addToHead(int);
//节点插入到尾部
void addToTail(int);
//删除头部节点
int deleteFromHead();
//删除尾部节点
int deleteFromTail();
//删除指定节点
void deleteNode(int);
private:
//头指针、尾指针
Node *head, *tail;
};
#endif基于双向链表的操作和单向链表非常相似,我们是从单向链表中扩展出双向链表的,目的是改进删除尾部节点的算法。
删除尾部节点
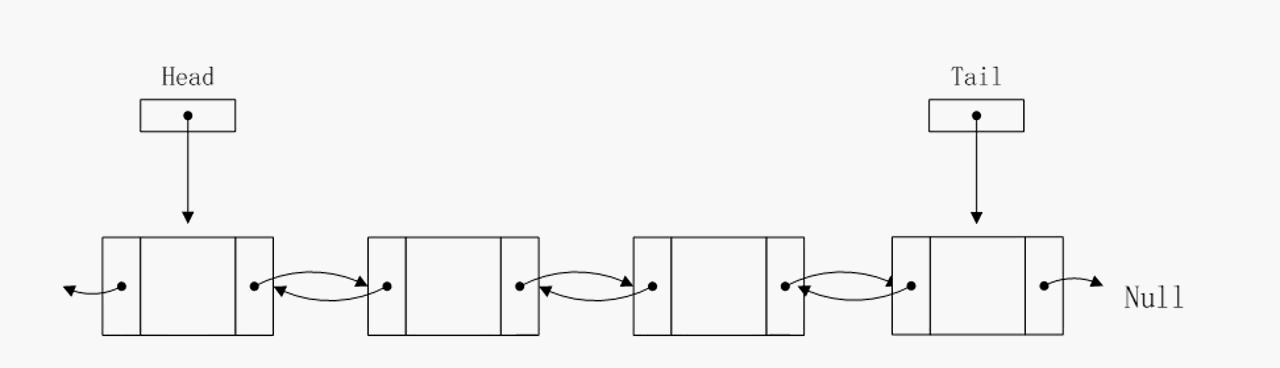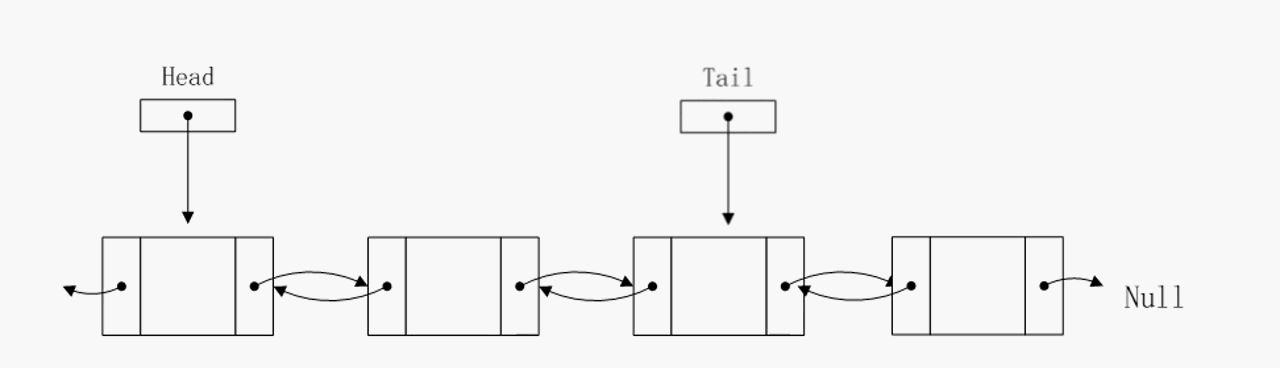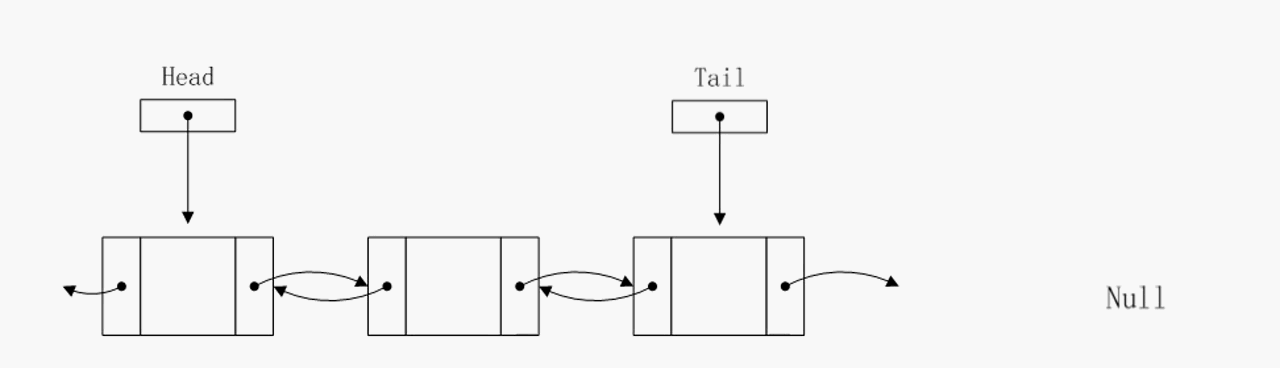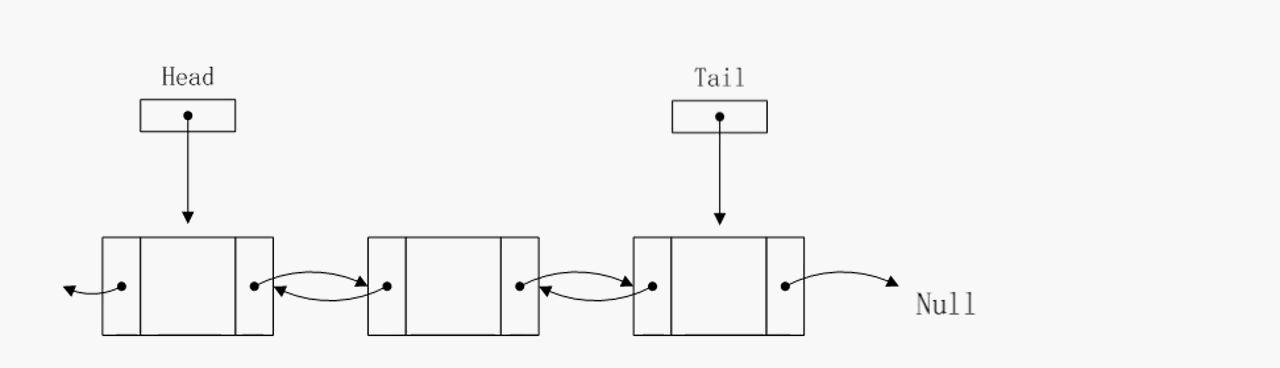
可以看到删除尾部节点的算法复杂度已经降至O(1),事实上pre指针不仅仅简化了删除尾节点操作,对于其他O(1)的操作也有简化,因为有了pre指针,有些临时指针就没必要定义了。
尽管如此,我们还是增加了空间的使用程度才降低了时间上的消耗,本质上是空间换取时间的做法。对于现代软件开发来讲,硬件已经不是主要瓶颈,一些空间上的代价是值得的。
也许有人了解过所谓的循环单向链表、循环双向链表,它们到底是什么东西呢?
循环单向链表和单向链表的差别:
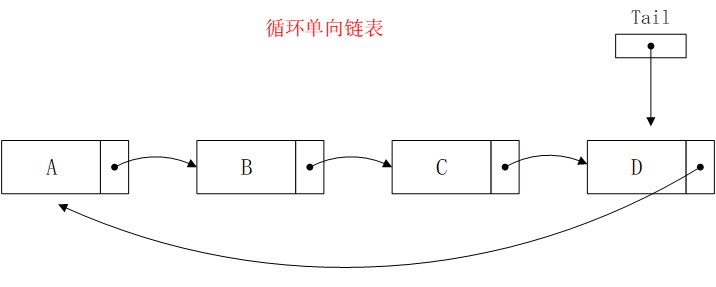
差别就在于尾节点的next指针循环指向了头结点,这时候head指针就没必要存在了,如果继续定义head指针,只是更加方便一些,但它已经不是不可或缺的了。
循环双向链表和双向链表的差别:
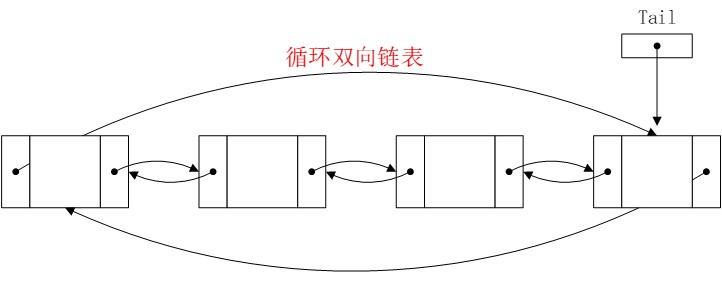
同样的道理,head指针根据需要添加。循环链表和普通链表没有本质的差别,可以根据需要自行选择。
到目前为止,我们还有一个问题没有解决,那就是删除指定节点。该操作本质上是查找问题,为了优化查找算法,我们需要继续对链表结构进行改动。事实上,上述链表已经足够满足需求了,因为我们假设对象是中等数量的数据,O(n)级别的操作可以接受,对于更加复杂的数据,需要更加复杂的数据结构进行处理。出于学习的态度,可以继续研究,毕竟有句话叫做-厚积薄发。






