

大数据的测试工作:
1、模块的单独测试
2、模块间的联调测试
3、系统的性能测试:内存泄露、磁盘占用、计算效率
4、数据验证(核心)
下面对各个模块的测试工作进行单独讲解。

0. 功能测试
1. 性能测试
2. 自动化测试
3. 文档评审
4. 脚本开发
一、后台数据处理端
后端的测试重点,主要集中在数据的采集处理、标签计算效率、异常数据排查(功能),测试脚本编写(HiveQL)、自动化脚本编写(造数据、数据字段检查等)
1.数据的采集处理(Extract-Transform-Load)
ETL:即将数据从源系统加载到数据仓库的过程。源系统包括:数据文件(excel、log等)、RDD数据库、非RDD数据库等;
extract:从源系统提取需求数据。
transform:清洗数据(数据格式转化、异常数据处理等)。
Load:将清洗的数据加载至数据仓库。

ETL测试:即确保根据需求将源系统的数据经过处理后加载到目标的数据是准确的。即源和目的数据之间转化过程中的数据验证。
测试类型

测试场景
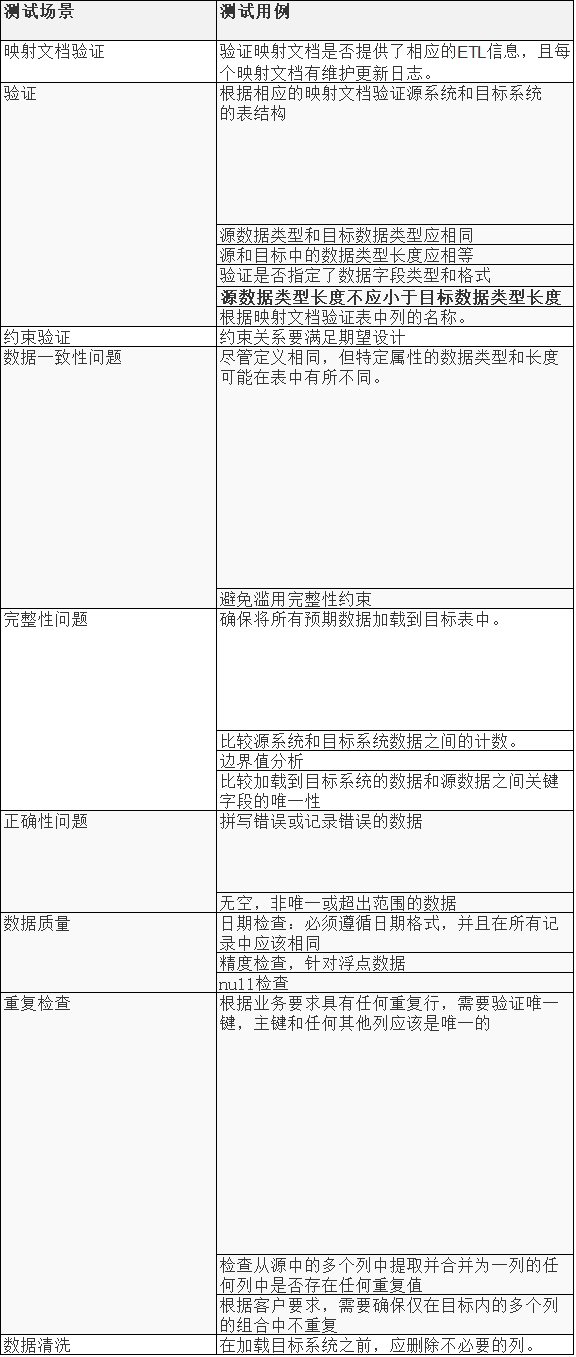
券商等金融机构,其用户每天都会产生大量的交易数据,这部分数据最初都会存储在客户的关系型数据库中(oracle),因此后台每天需要先进行数据采集,将数据采集至Hadoop的hdfs系统;数据采集过后,需要对源数据进行一次数据清洗工作:过滤异常数据(NULL)、筛掉关联性较高的数据。
2.标签计算效率
根据标签文档编写hiveSQL、MR等标签计算代码,针对hiveSQL,不同的开发人员编写的sql质量不同,执行的效率也不相同;此部分不仅需要开发人员具备基本的复杂sql编写功底,也需要开发人员掌握一定的sql性能调优能力;在数据,服务器配置一定的情况下,效率的提升来源于对sql的优化;
由于hivesql的计算(都会转化成一个MR),需要大量的读写数据到磁盘的操作,因此计算效率较低;
impala则是将数据push到内存中,然后从内存中读取数据,效率有大幅提升,但是耗费了较高的服务器内存,成本较高;
Spark :内存计算引擎,提供Cache机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的IO开销;
3.异常数据排查
异常值:分为两类:null,计算错误的值。 (1)Null值(标签下的数据均为NULL),首先 需求排查是否是数据的影响(例如 依赖数据缺失)。其次排查依赖数据的因素后,就需要排查是否是hiveSQL编写的问题和MR代码问题。(2)标签计算错误: 通过手工根据标签公式计算标签的值和通过hive计算得出的值进行对比,如果不一致,则需要排查是否是hivesql没有对标签公式进行精确实现。计算错误的值可以分为两类:1.明显错误(可以通过sql筛选出来的异常值,针对存在阈值的标签,比如股票仓位:仓位不得>1,如果出现>1的数据,则可以断定此标签计算有问题);2.非明显错误(此部分无法筛选出来,必须通过计算才能验证)
由于此部分计算好的数据需要导入到中台进行进一步运用,所以此部分的数据准确性有至关重要的作用。(测试人员需要对业务十分了解)
二、中台管理端
中台产品一般以web服务呈现。测试内容除了与普通的Java web项目相同,还要测试后台数据Export中台的过程中,数据类型、准确性、完整性、性能进行测试。
就目前的项目而言:测试计划的内容包括:需求文档测试、后台导出表的测试(表字段类型、数据完整性、浮点型数据精度、导出性能等)、中台接口测试(自动化)、前端UI页面测试、性能测试、安全测试、兼容性测试。
需求文档:需求点梳理、整理测试点、编写测试用例
数据连表导出:后台数据和中台数据的类型、精度要保持一致(中台数据库为MySQL,数据类型可能和后台的数据类型定义不一致,要确保数据类型转化的正确性);
中台接口测试:此部分可以进行接口自动化测试。
UI页面测试:根据需求文档、UI设计图编写测试用例
性能测试:中台接口的压测、中台服务缓存数据占服务器的内存空间测试
安全测试:根据公司安全测试手册进行测试(安全漏洞扫描)
兼容性测试:IE10
三、前端应用端
主要是app端的测试工作:一般的app测试工作,数据的核对(类型、精度等)
四、结尾
可以看出来,整个项目始终包含数据的验证工作。
附录:
异常值检查: https://www.cnblogs.com/xiaohuahua108/p/6237906.html
spark 优势: https://www.zhihu.com/question/31930662
接口测试: https://www.cnblogs.com/iloverain/p/9429116.html
本文版权归作者所有,转载请注明出处http://www.cnblogs.com/iloverain/.未经作者同意必须保留此段声明,否则保留追究法律责任的权利.






