
这是一篇Medium上获得近2万赞的深度学习入门指南,用图文为你详解深度学习中的各个基础概念。
在我们的日常生活中,几乎随处可见AI和机器学习这些术语。但,绝大多数人并不明白什么是AI。
小七希望当你阅读完这篇文章后,会对AI和ML的基本知识有更多的了解和认识。更重要的是明白什么是深度学习,以及这类最热门的技术如何运作。
背景知识
理解深度学习如何工作的第一步是掌握下列重要术语之间的区别。
人工智能(AI)v.s.机器学习(ML)
人工智能是对人类智能在计算机上的复制。
机器学习,指的是机器使用大量数据集而非硬编码规则来进行学习的能力。
在整个人工智能发展史上,几乎一直随同人工神经网络研究的进展而起起伏伏。近期引发人工智能新一轮热潮的深度学习,其名称中的“深度”某种意义上就是指人工神经网络的层数,深度学习本质上是基于多层人工神经网络的机器学习算法。 ML允许计算机通过自身来学习。这种学习方法得益于现代计算机的强大性能,性能保证了计算机能够轻松处理样本数巨大的数据集。
监督学习 v.s. 非监督学习
监督学习指的是从标记的训练数据来推断一个功能的机器学习任务。训练数据包括一套训练示例。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。
当你利用监督学习来训练AI时,你提供给它一份输入,并告诉它预期的输出。
比如:预测天气的AI便是监督学习的典型案例之一。它通过学习过往数据来预测未来天气,其训练数据拥有输入(气压、湿度、风速)和输出(温度)。
非监督学习是指根据类别未知(没有被标记)的训练样本/数据来进行学习,以解决模式识别中的各种问题。
无监督学习里典型例子是聚类。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了。
具体来说,电商网站上的行为预测AI就属于非监督学习。它在输入数据上创建它自己的分类。它将会告诉你哪一种用户最可能购买差异化的商品。
深度学习又是如何运作的呢?
现在我们再来了解什么是深度学习,以及它是如何运作的。
深度学习的概念由Hinton等人于2006年提出。
它是机器学习中一种基于对数据进行表征学习的方法。在给予它一组输入后,它使我们能够训练AI来预测结果。其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像、声音和文本。
我们将通过建立一个假设的机票价格预估系统来阐述深度学习是如何运作的。我们将应用监督学习方法来训练它。
我们想要该机票价格预估系统基于下列输入来进行预测(为了简洁,我们除去了返程机票):
起飞机场
到达机场
起飞日期
航空公司
神经网络
接下来我们将视角转向AI的“大脑”内部。
人工神经网络(Artificial Neural Networks,简称ANNs),也简称为神经网络(NNs)或称作连接模型(Connection Model),它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。
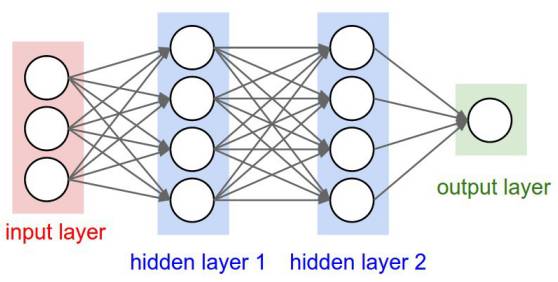 Image credit: CS231n
Image credit: CS231n
这些神经元又被分为三种层次:
输入层
隐藏层
输出层
输入层接收输入数据。在本案例中,在输入层中有4个神经元:起飞机场,到达机场,起飞日期以及航空公司。输入层将输入传递给第一个隐藏层。
隐藏层针对我们的输入进行数学运算。创建神经网络的一大难点便是决定隐藏层的层数,以及每层中神经元的个数。
深度学习中的“深度”所指的是拥有多于一层的隐藏层。
输出层返回的是输出数据。在本案例中,输出层返回的是价格预测。
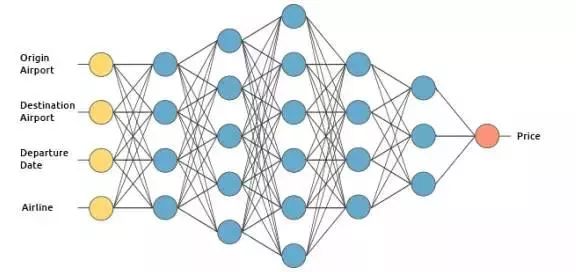
那么它到底是如何来运算价格预测的呢?这便是我们将要揭晓的深度学习的奇妙之处了。
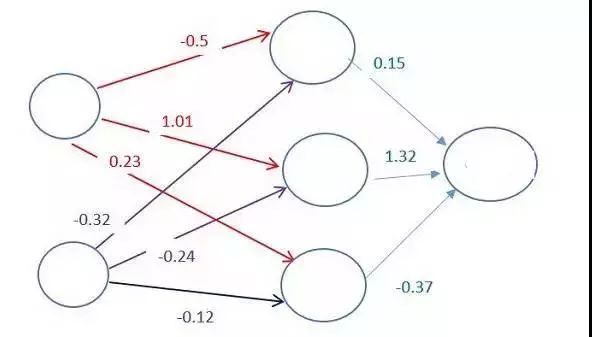
每两个神经元之间的连接,都对应着一个权重。该权重决定了输入值的重要程度。初始的权重会被随机设定。
当预测机票价格时,起飞日期是决定价格的最重要的因素之一。因此,与起飞日期这个神经元相连的连接将会有更高的权重。
 每个神经元都有一个激活函数(https://en.wikipedia.org/wiki/Activation_function)。若没有数学推导,这些函数十分晦涩难懂。
每个神经元都有一个激活函数(https://en.wikipedia.org/wiki/Activation_function)。若没有数学推导,这些函数十分晦涩难懂。
简而言之,激活函数的作用之一便是将神经元的结果“标准化”。
一旦一组输入数据通过了神经网络的所有层,神经网络将会通过输出层返回输出数据。
一点也不复杂,是吧?
训练神经网络
训练AI是深度学习中最难的部分了。这又是为什么呢?
你需要一个庞大的数据集
你还需要强大的算力
对于我们的机票价格预估系统,我们需要得到过往的票价数据。由于起始机场和起飞时间拥有大量可能的组合,所以我们需要的是一个非常庞大的票价列表。
为了训练机票价格预估系统的AI,我们需要将数据集的数据给予该系统,然后将它输出的结果与数据集的输出进行比对。因为此时AI仍然没有受过训练,所以它的输出将会是错误的。
一旦我们遍历完了整个数据集,我们便能创造出一个函数,该函数告诉我们AI的输出和真实输出到底相差多少。这个函数我们称为损失函数。
在理想情况下,我们希望我们的损失函数为0,该理想情况指的是AI的输出和数据集的输出相等之时。
如何减小损失函数呢?
改变神经元之间的权重。我们可以随机地改变这些权重直到损失函数足够小,但是这种方法并不够高效。
取而代之地,我们应用一种叫做梯度下降的技巧。
梯度下降是一种帮助我们找到函数最小值的技巧。在本案例中,我们寻找损失函数的最小值。
在每次数据集迭代之后,该方法以小增量的方式改变权重。通过计算损失函数在一组确定的权重集合上的导数(梯度),我们便能够知悉最小值在哪个方向。

为了最小化损失函数,你需要多次迭代数据集。这便是需要高算力的原因了。利用梯度下降更新权重的过程是自动进行的。这便是深度学习的魔力所在!
一旦我们训练好机票价格预估的AI之后,我们便能够用它来预测未来的价格了。
小结
1. 深度学习应用神经网络来模仿动物智能。
2. 神经网络中有三个层次的神经元:输入层、隐藏层以及输出层。
3. 神经元之间的连接对应一个权重,该权重决定了各输入数据的重要程度。
4. 神经元中应用一个激活函数来“标准化”神经元输出的数据。
5. 你需要一个庞大的数据集来训练神经网络。
6. 在数据集上迭代并与输出结果相比较,我们将会得到一个损失函数,损失函数能告诉我们AI生成的结果和真实结果相差多少。
7. 在每次数据集的迭代之后,都会利用梯度下降方法调整神经元之间的权重,以减小损失函数。






