
最近看了Eduardo Pérez-Pellitero 的AIS超分辨方法,里面用到 Spherical_Hashing的结构用于KNN搜索。
一开始并不清楚球哈希到底怎么建立的,看了原论文做个小总结。
Spherical Hashing
球哈希是什么呢?一般哈希方法都有哈希函数对不对?球哈希的哈希函数长这样: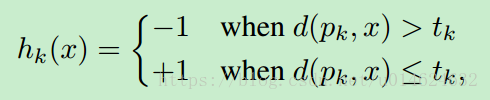
也就是说球哈希函数描述了数据空间的k个球,球心分别是Pk,半径分别是tk。(Pk,tk也是球哈希里最重要的参数,怎么设置呢?后面说。)
那么对于定义K个球的球哈希,最后的hash code就是长度为k的-1/+1字串,每一位分别表示样本是否属于某个球。
球哈希区别于其他哈希算法的最大不同是,其他哈希基于超平面对原始数据进行划分,但球哈希是基于一个一个球的。
看图说话: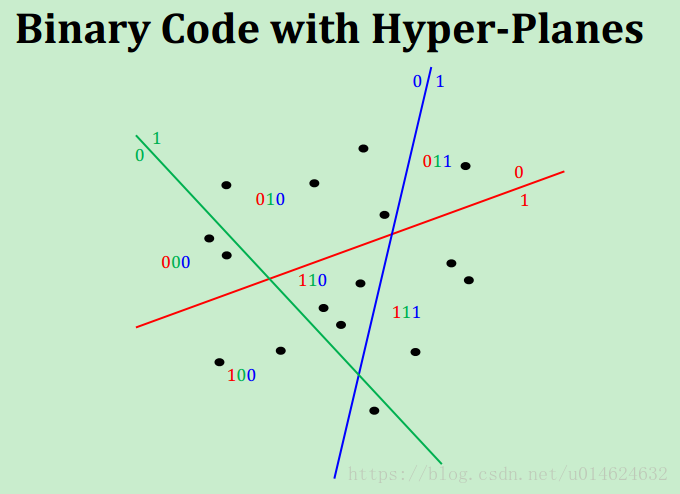
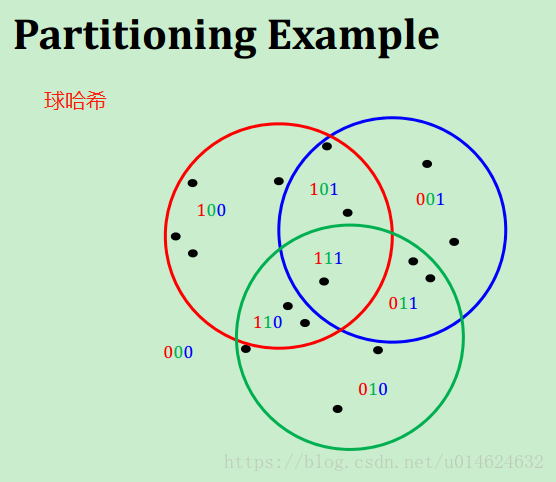
那么球哈希对比于基于超平面划分的哈希算法有什么优势呢?
答案是,球哈希划分的区域是封闭且更紧凑的。
至少三个超平面才可画出一个封闭区域,而球哈希只要一个。
而且每个区域内样本的最大距离的平均值会更小,说明各个区域的样本是更紧凑的。这样更符合邻近的含义啊,更适合在进行相似搜索时使用。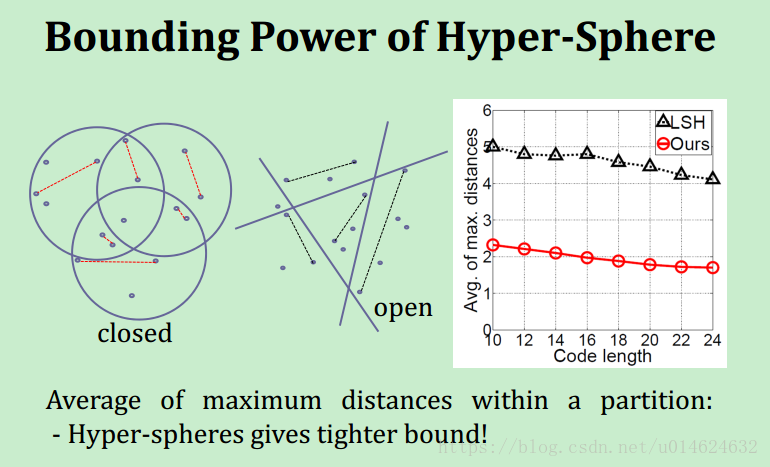
注意C个超球体划分出的有界区域个数高达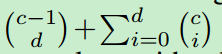 。这个公式没整明白,,留个坑。。。
。这个公式没整明白,,留个坑。。。
现在就说球哈希函数的Pk,tk怎么确定。
Spherical Hashing训练过程
首先看我们的目标。
1、我们希望每个球把样本都是均分的,就是球内球外各占一半。
2、希望每个球的交叉部分不要太多,也就是每个哈希函数相对独立。
基于第一个目标我们会动态选择半径tk,基于第二个目标我们会动态移动球心的位置。
方便起见,可以定义两个辅助变量: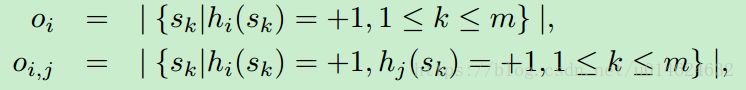
第一个表示落入第i个球中的样本数量,第二个表示落入第i,第j个球交叉部分的样本数量。
这样一来就有思路了,先随机选k个球心,然后根据目标1设定半径。
对于交叉样本太多的两个球心,赋予一个repulsive的力,对离得太远的两个球赋予一个attractive 的力。
然后计算这些力的累加作用,更新球心,再根据目标一更新半径。
重复这个过程,直到满足收敛条件。
论文给出的算法时间复杂度O((c^2+cD)m),没看明白。D是数据的维度,m是样本个数,c是编码长度,也就是超球体个数。
第一个for循环c^2复杂度,第二个for循环c复杂度。计算每个样本到中心的距离,cm的复杂度。确定半径,排序,最低也是cm的复杂度。计算Oij,每列求和,m的复杂度。。。。神晕() 留个坑。。。
那么基于编好的球哈希code,怎么定义两个code之间的距离,也就是类间距呢?
传统方法是用汉明距离。但没有考虑到球内距离更近的事实。所以作者对汉明距离进行了一点改动: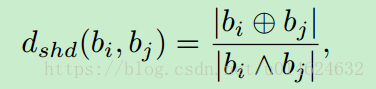
注意,球哈希的生成方式只保证了数据分配的均衡性,以及每个哈希函数的相对独立性。
但是,对于一个封闭区域,可能有多个样本,也存在对于某个样本不属于任何一个球的情况!
在AIS中的应用
AIS用球哈希来干什么?
首先AIS是基于字典来做超分辨的。这里不细说。AIS在训练好一个字典(包含K个字典原子,作为anchor,代表了每个regressor),把input image分成很多个patch。
球哈希在AIS中做的是这样一件事:对于每个patch,最邻近的regressor。
这里有歧义。
根据原文中 in testing time, find the right regressor(也就是说已经有了回归器啊)判断为对于每个patch,最邻近的regressor。。但是VI-C部分说,Our hashing scheme defines several hash codes or buckets, and the regressors are labeled with them during training time. 这个training time是线下计算回归器还是hash函数训练呢??这里暂且认为是hash函数训练阶段。因为前一句中是“the number of hyperspheresused during testing time. ”
AIS给每个regressor和每个patch都会进行球哈希编码。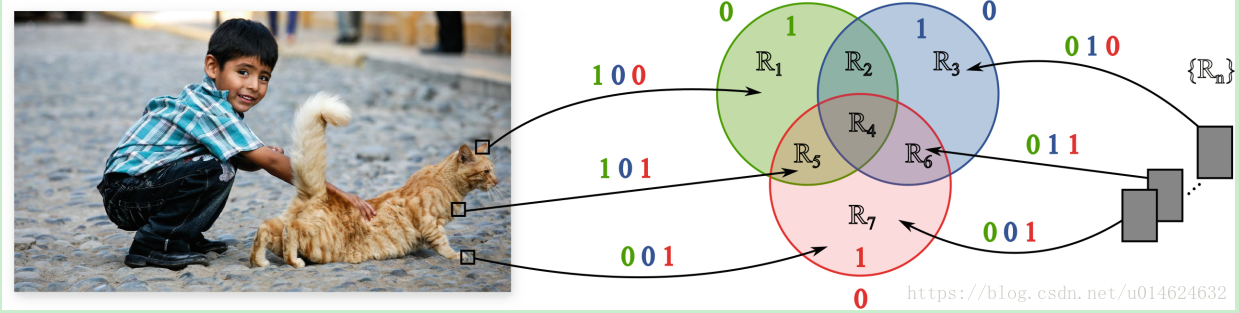
最佳情况是一个hash code 对应一个regressor(对应patch个数没有限制),这样就解决了回归邻域的搜索问题。
但是这样hash code会很长啊,总的regressor个数是K,hash code数目是2^s,只要每个类的regressor数目不是很多就可以了~~reranking的时间也不会很长~~~
也就是作者提到的逆搜索。
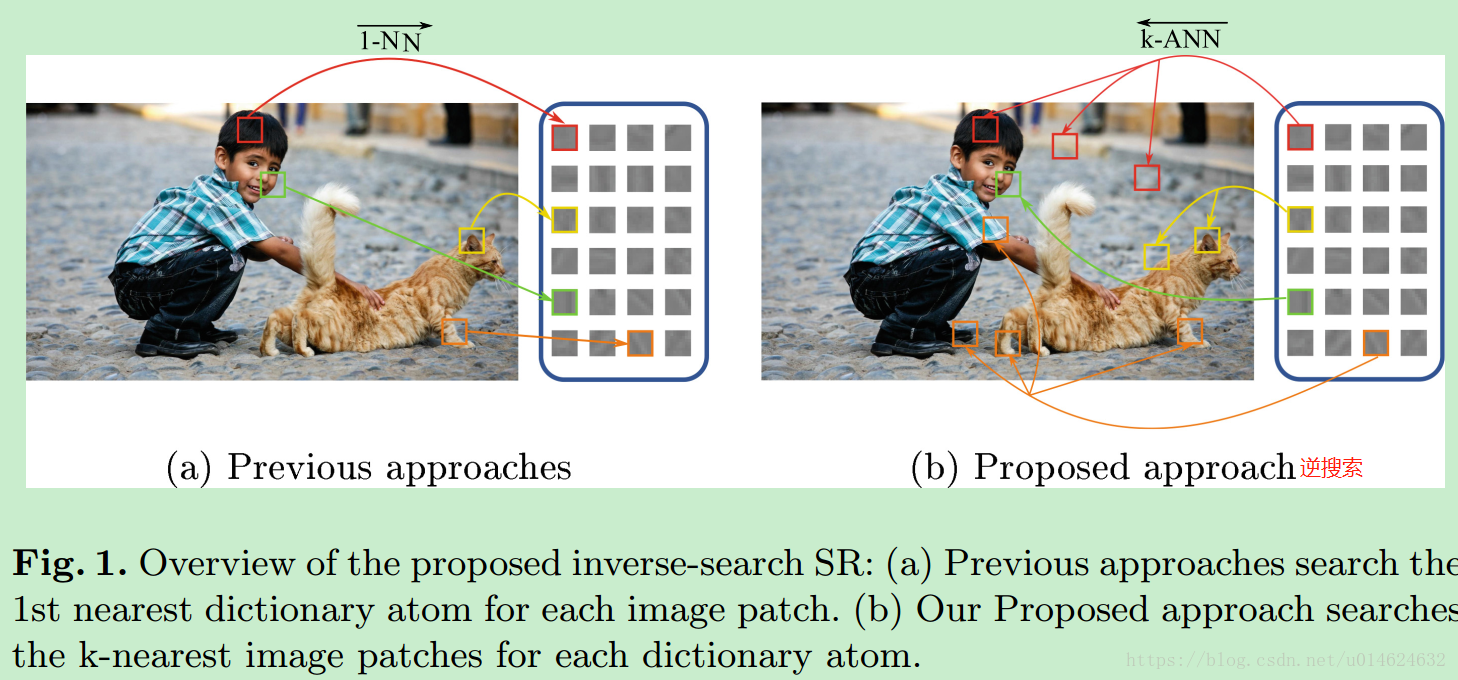
那么问题就来了。
一个hash code对应多个patch没有问题,那对应多个regressor呢?
这相当于一个patch可选择的regressor不唯一了!!文中提到这种情况要re-ranking,具体怎么做呢?
没有找到明确的解释。我认为是对这个闭域里的每一个regressor计算一次距离,取距离最小对应的regeressor。因为球哈希在这里目的就是减少搜索范围。
一个patch所在的闭域没有一个regressor怎么办?
这种情况比较少,所以设置一个通用的regressor就可以了。
AIS中训练哈希函数用什么数据集呢?是train set吗?从前面对Our hashing scheme defines several hash codes or buckets, and the regressors are labeled with them during training time的理解,推断为用字典原子训练。因为最后希望哈希函数均分的也是regressor的数目。
AIS对球哈希的修改:
球哈希函数中用欧拉距离来判断是否属于某个球,但AIS认为,极对称的点也是相似甚至相同的,如果用欧拉距离就无法描述这种相似性。因此提出一种变换方案处理极对称的点。
一、设计一个超平面,做对称变换。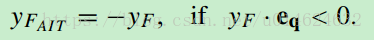
eq is the qth standard basis in the Euclidean m space.
二、把欧拉距离换成新定义的距离。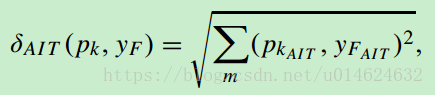
变换之后达到的效果:把所有的样本都强制变换到一个“正”的半空间。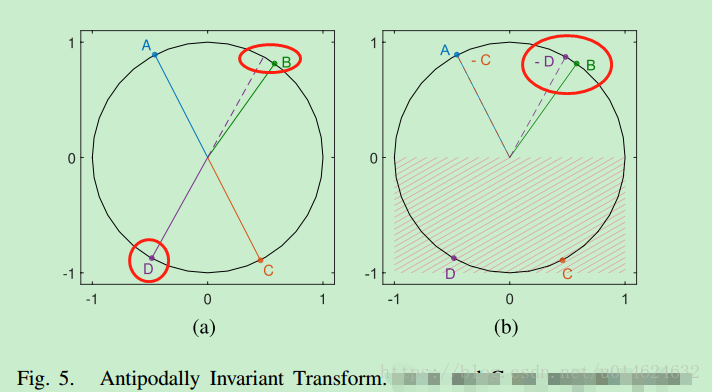
参考:
Spherical_Hashing主页:https://sglab.kaist.ac.kr/Spherical_Hashing/
主页上面可以下载论文/slide/源码(matlab/c++)
AIS: https://perezpellitero.github.io/project_websites/ais_sr.html






