
- 最早的机器学习应用-垃圾邮件分辨
- 传统的计算机解决问题思路:
- 编写规则,定义“垃圾邮件”,让计算机执行
- 对于很多问题,规则很难定义
- 规则在不断变化
- 传统的计算机解决问题思路:
- 图像识别
- 人脸识别
- 数字识别
基础概念
数据
- 著名的鸢尾花数据https:/len.wikipedia.org/wiki/lris flower data set


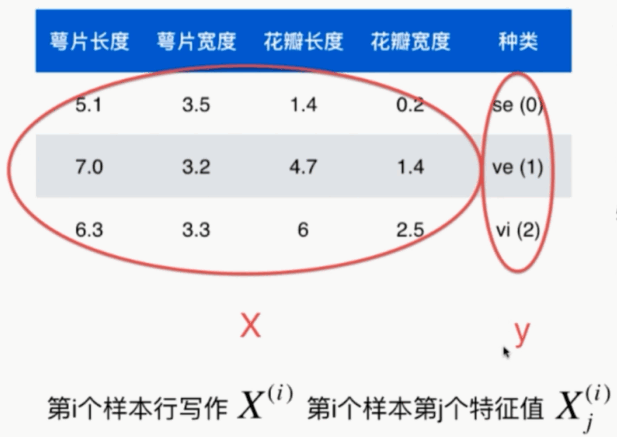
- 数据整体叫数据集(data set)
- 每一行数据称为一个样本(sample)
- 除最后一列,每一列表达样本的一个特征(feature)
- 最后一列,称为标记(label)
- (P.S. 大写字母表示矩阵,小写字母表示向量)
- 本文表征用列向量表示





特征可以很抽象

基本任务之分类任务
- 二分类
- 判断邮件是垃圾邮件;不是垃圾邮件
- 判断发放给客户信用卡有风险;没有风险
- 判断病患良性肿瘤;恶性肿瘤
- 判断某支股票涨;跌
- 多分类
- 数字识别
- 图像识别
- 判断发放给客户信用卡的风险评级
- 很多复杂的问题也可以转换成多分类问题
- 自动玩游戏,围棋,无人车,2048
- 一些算法只支持完成二分类的任务
- 但是多分类的任务可以转换成二分类的任务
- 有一些算法天然可以完成多分类任务
- 多标签分类


基本任务之回归任务
- 结果是一个连续数字的值,而非一个类别
- 房屋价格
- 市场分析
- 学生成绩
- 有一些算法只能解决回归问题
- 有一些算法只能解决分类问题
- 有一些算法的思路既能解决回归问题,又能解决分类问题。
- 一些情况下,回归任务可以简化成分类任务
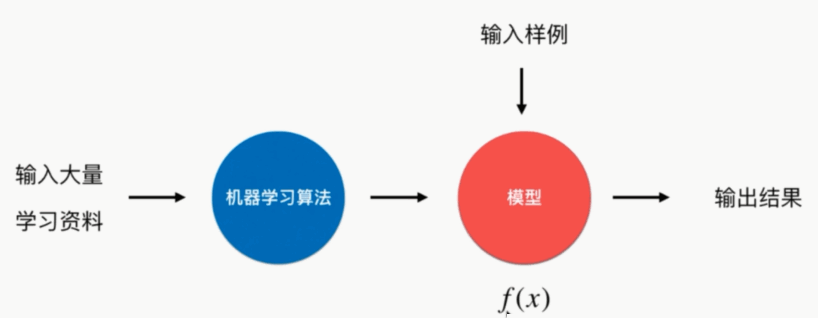

学习方法之监督学习
- 给机器的训练数据拥有“标记”或者“答案”
- 图像已经拥有了标定信息
- 银行已经积累了一定的客户信息和他们信用卡的信用情况
- 医院已经积累了一定的病人信息和他们最终确诊是否患病的情况
- 市场积累了房屋的基本信息和最终成交的金额
- k近邻
- 线性回归和多项式回归
- 逻辑回归
- SVM
- 决策树和随机森林

学习方法之非监督学习
- 给机器的训练数据没有任何“标记”或者“答案”
- 对没有“标记”的数据进行分类-聚类分析
- 对数据进行降维处理
- 特征提取:信用卡的信用评级和人的胖瘦无关?
- 特征压缩:PCA
- 降维处理的意义:方便可视化
- 异常检测


学习方法之半监督学习
- 一部分数据有“标记”或者“答案”,另一部分数据没有更常见:各种原因产生的标记缺失
- 通常都先使用无监督学习手段对数据做处理,之后使用监督学习手段做模型的训练和预测
学习方法之增强学习
- 根据周围环境的情况,采取行动,根据采取行动的结果,学习行动方式。
- 很适合机器人的自我学习

其他方向
在线学习和批量学习(离线学习) Online Learning And Batch Learning
- Batch 不用校正模型
- 优点:简单
- 问题:如何适应环境变化?
- 解决方案:定时重新批量学习
- 缺点:每次重新批量学习,运算量巨大
- 在某些环境变化非常快的情况下,甚至不可能的。
- Online 坏数据怎么办?
- 优点:及时反映新的环境变化
- 问题:新的数据带来不好的变化?
- 解决方案:需要加强对数据进行监控
- 其他:也适用于数据量巨大,完全无法批量学习的环境。
参数学习和非参数学习 Parametric Nonparametric
- 参数学习
- 一旦学到了参数,就不再需要原有的数据集。先假设

- 非参数学习
- 不对模型进行过多假设
- 非参数不等于没参数!
- 不对整个问题做一个建模,不把问题定义为学习参数
思考
- 数据确实非常重要
- 收集更多的数据
- 数据驱动·提高数据质量
- 提高数据的代表性
- 研究更重要的特征

- 奥卡姆的剃刀
- 简单的就是好的
- 到底在机器学习领域,什么叫“简单”?
- 没有免费的午餐定理
- 可以严格地数学推导出:任意两个算法,他们的**期望性能(简单可以理解为平均值)**是相同的!
- 具体到某个特定问题,有些算法可能更好
- 但没有一种算法,绝对比另一种算法好
- 脱离具体问题,谈那个算法好是没有意义的。
- 在面对一个具体问题的时候,尝试使用多种算法进行对比试验,是必要的。
- 面对不确定的世界,怎么看待使用机器学习进行预测的结果?




