
简介
园子里已经有不少介绍HTTP的的好文章。对HTTP的一些细节介绍的比较好,所以本篇文章不会对HTTP的细节进行深究,而是从够高和更结构化的角度将HTTP协议的元素进行分类讲解。
HTTP的定义和历史
在一个网络中。传输数据需要面临三个问题:
1.客户端如何知道所求内容的位置?
2.当客户端知道所求内容的位置后,如何获取所求内容?
3.所求内容以何种形式组织以便被客户端所识别?
对于WEB来说,回答上面三种问题分别采用三种不同的技术,分别为:统一资源定位符(URIs),超文本传输协议(HTTP)和超文本标记语言(HTML)。对于大多数WEB开发人员来说URI和HTML都是非常的熟悉。而HTTP协议在很多WEB技术中都被封装的过多使得HTTP反而最不被熟悉。
HTTP作为一种传输协议,也是像HTML一样随着时间不断演进的,目前流行的HTTP1.1是HTTP协议的第三个版本。
HTTP 0.9
HTTP 0.9作为HTTP协议的第一个版本。是非常弱的。请求(Request)只有一行,比如:
GET www.imooc.com
从如此简单的请求体,没有POST方法,没有HTTP 头可以看出,那个时代的HTTP客户端只能接收一种类型:纯文本。并且,如果得不到所求的信息,也没有404 500等错误出现。
虽然HTTP 0.9看起来如此弱,但已经能满足那个时代的需求了。
HTTP 1.0
随着1996年后,WEB程序的需求,HTTP 0.9已经不能满足需求。HTTP1.0最大的改变是引入了POST方法,使得客户端通过HTML表单向服务器发送数据成为可能,这也是WEB应用程序的一个基础。另一个巨大的改变是引入了HTTP头,使得HTTP不仅能返回错误代码,并且HTTP协议所传输的内容不仅限于纯文本,还可以是图片,动画等一系列格式。
除此之外,还允许保持连接,既一次TCP连接后,可以多次通信,虽然HTTP1.0 默认是传输一次数据后就关闭。
HTTP 1.1
2000年5月,HTTP1.1确立。HTTP1.1并不像HTTP1.0对于HTTP0.9那样的革命性。但是也有很多增强。
首先,增加了Host头,比如访问我的博客:
GET /Careyson HTTP/1.1 Host: www.imooc.com
Get后面仅仅需要相对路径即可。这看起来虽然仅仅类似语法糖的感觉,但实际上,这个提升使得在Web上的一台主机可以存在多个域。否则多个域名指向同一个IP会产生混淆。
此外,还引入了Range头,使得客户端通过HTTP下载时只下载内容的一部分,这使得多线程下载也成为可能。
还有值得一提的是HTTP1.1 默认连接是一直保持的,这个概念我会在下文中具体阐述。
HTTP的网络层次
在Internet中所有的传输都是通过TCP/IP进行的。HTTP协议作为TCP/IP模型中应用层的协议也不例外。HTTP在网络中的层次如图1所示。

可以看出,HTTP是基于传输层的TCP协议,而TCP是一个端到端的面向连接的协议。所谓的端到端可以理解为进程到进程之间的通信。所以HTTP在开始传输之前,首先需要建立TCP连接,而TCP连接的过程需要所谓的“三次握手”。概念如图2所示。

在TCP三次握手之后,建立了TCP连接,此时HTTP就可以进行传输了。一个重要的概念是面向连接,既HTTP在传输完成之间并不断开TCP连接。在HTTP1.1中(通过Connection头设置)这是默认行为。所谓的HTTP传输完成我们通过一个具体的例子来看。
比如访问我的博客,使用Fiddler来截取对应的请求和响应。如图3所示。
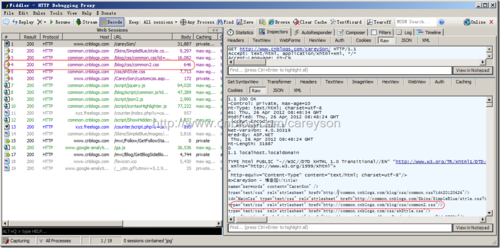
可以看出,虽然仅仅访问了我的博客,但锁获取的不仅仅是一个HTML而已,而是浏览器对HTML解析的过程中,如果发现需要获取的内容,会再次发起HTTP请求去服务器获取,比如图2中的那个common2.css。这上面19个HTTP请求,只依靠一个TCP连接就够了,这就是所谓的持久连接。也是所谓的一次HTTP请求完成。
HTTP请求(HTTP Request)
所谓的HTTP请求,也就是Web客户端向Web服务器发送信息,这个信息由如下三部分组成:
1.请求行
2.HTTP头
3.内容
一个典型的请求行比如:
GET www.imooc.com HTTP/1.1
请求行写法是固定的,由三部分组成,第一部分是请求方法,第二部分是请求网址,第三部分是HTTP版本。
第二部分HTTP头在HTTP请求可以是3种HTTP头:1.请求头(request header) 2.普通头(general header) 3.实体头(entity header)
通常来说,由于Get请求往往不包含内容实体,因此也不会有实体头。
第三部分内容只在POST请求中存在,因为GET请求并不包含任何实体。
我们截取一个具体的Post请求来看这三部分,我在一个普通的aspx页面放一个BUTTON,当提交后会产生一个Post请求,如图4所示。
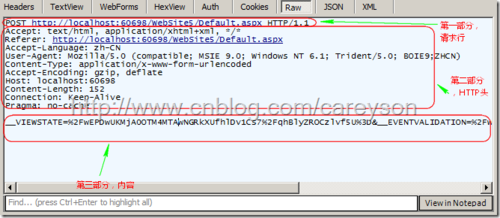
HTTP请求方法
虽然我们所常见的只有Get和Post方法,但实际上HTTP请求方法还有很多,比如: PUT方法,DELETE方法,HEAD方法,CONNECT方法,TRACE方法。这里我就不细说了,自行Bing。
这里重点说一下Get和Post方法,网上关于Get和Post的区别满天飞。但很多没有说到点子上。Get和Post最大的区别就是Post有上面所说的第三部分:内容。而Get不存在这个内容。因此就像Get和Post其名称所示那样,Get用于从服务器上取内容,虽然可以通过QueryString向服务器发信息,但这违背了Get的本意,QueryString中的信息在HTTP看来仅仅是获取所取得内容的一个参数而已。而Post是由客户端向服务器端发送内容的方式。因此具有请求的第三部分:内容。
HTTP响应(HTTP Response)
当Web服务器收到HTTP请求后,会根据请求的信息做某些处理(这些处理可能仅仅是静态的返回页,或是包含Asp.net,PHP,Jsp等语言进行处理后返回),相应的返回一个HTTP响应。HTTP响应在结构上很类似于HTTP请求,也是由三部分组成,分别为:
1.状态行
2.HTTP头
3.返回内容
首先来看状态行,一个典型的HTTP状态如下:
HTTP/1.1 200 OK
第一部分是HTTP版本,第二部分是响应状态码,第三部分是状态码的描述,因此也可以把第二和第三部分看成一个部分。
对于HTTP版本没有什么好说的,而状态码值得说一下,网上对于每个具体的HTTP状态码所代表的含义都有解释,这里我说一下分类。
信息类 (100-199)
响应成功 (200-299)
重定向类 (300-399)
客户端错误类 (400-499)
服务端错误类 (500-599)
HTTP响应中包含的头包括1.响应头(response header) 2.普通头(general header) 3.实体头(entity header)。
第三部分HTTP响应内容就是HTTP请求所请求的信息。这个信息可以是一个HTML,也可以是一个图片。比如我访问百度,HTTP Response如图5所示。
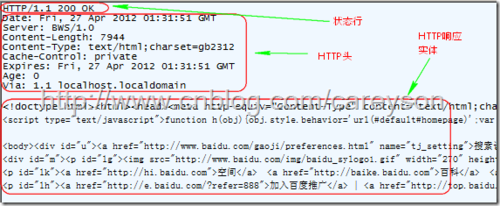
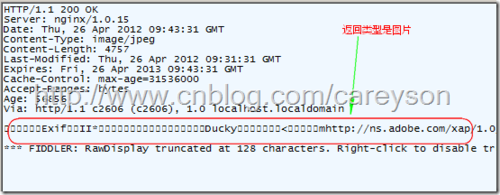
图5中的响应是一个HTML,当然还可以是其它类型,比如图片,如图6所示。
这里会有一个疑问,既然HTTP响应的内容不仅仅是HTML,还可以是其它类型,那么浏览器如何正确对接收到的信息进行处理?
这是通过媒体类型确定的(Media Type),具体来说对应Content-Type这个HTTP头,比如图5中是text/html,图6是image/jpeg。
媒体类型的格式为:大类/小类 比如图5中的html是小类,而text是大类。
IANA(The Internet Assigned Numbers Authority,互联网数字分配机构)定义了8个大类的媒体类型,分别是:
application— (比如: application/vnd.ms-excel.)
audio (比如: audio/mpeg.)
image (比如: image/png.)
message (比如,:message/http.)
model(比如:model/vrml.)
multipart (比如:multipart/form-data.)
text(比如:text/html.)
video(比如:video/quicktime.)
HTTP头
HTTP头仅仅是一个标签而已,比如我在Aspx中加入代码:
Response.AddHeader("测试头","测试值");对应的我们可以在fiddler抓到的信息如图7所示。

不难看出,HTTP头并不是严格要求的,仅仅是一个标签,如果浏览器可以解析就会按照某些标准(比如浏览器自身标准,W3C的标准)去解释这个头,否则不识别的头就会被浏览器无视。对服务器也是同理。假如你编写一个浏览器,你可以将上面的头解释成任何你想要的效果。
下面我们说的HTTP头都是W3C标准的头,我不会对每个头的作用进行详细说明,关于HTTP头作用的文章在网上已经很多了,请自行Bing。HTTP头按照其不同的作用,可以分为四大类。
通用头(General header)
通用头即可以包含在HTTP请求中,也可以包含在HTTP响应中。通用头的作用是描述HTTP协议本身。比如描述HTTP是否持久连接的Connection头,HTTP发送日期的Date头,描述HTTP所在TCP连接时间的Keep-Alive头,用于缓存控制的Cache-Control头等。
实体头(Entity header)
实体头是那些描述HTTP信息的头。既可以出现在HTTP POST方法的请求中,也可以出现在HTTP响应中。比如图5和图6中的Content-Type和Content-length都是描述实体的类型和大小的头都属于实体头。其它还有用于描述实体的Content-Language,Content-MD5,Content-Encoding以及控制实体缓存的Expires和Last-Modifies头等。
请求头(HTTP Request Header)
请求头是那些由客户端发往服务端以便帮助服务端更好的满足客户端请求的头。请求头只能出现在HTTP请求中。比如告诉服务器只接收某种响应内容的Accept头,发送Cookies的Cookie头,显示请求主机域的HOST头,用于缓存的If-Match,If-Match-Since,If-None-Match头,用于只取HTTP响应信息中部分信息的Range头,用于附属HTML相关请求引用的Referer头等。
响应头(HTTP Response Header)
HTTP响应头是那些描述HTTP响应本身的头,这里面并不包含描述HTTP响应中第三部分也就是HTTP信息的头(这部分由实体头负责)。比如说定时刷新的Refresh头,当遇到503错误时自动重试的Retry-After头,显示服务器信息的Server头,设置COOKIE的Set-Cookie头,告诉客户端可以部分请求的Accept-Ranges头等。
状态保持
还有一点值得注意的是,HTTP协议是无状态的,这意味着对于接收HTTP请求的服务器来说,并不知道每一次请求来自同一个客户端还是不同客户端,每一次请求对于服务器来说都是一样的。因此需要一些额外的手段来使得服务器在接收某个请求时知道这个请求来自于某个客户端。如图8所示。

图8.服务器并不知道请求1和请求2来自同一个客户端
通过Cookies保持状态
为了解决这个问题,HTTP协议通过Cookies来保持状态,对于图8中的请求,如果使用Cookies进行状态控制,则变成了如图9所示。

图9.通过Cookies,服务器就可以清楚的知道请求2和请求1来自同一个客户端
通过表单变量保持状态
除了Cookies之外,还可以使用表单变量来保持状态,比如Asp.net就通过一个叫ViewState的Input=“hidden”的框来保持状态,比如:
<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="/wEPDwUKMjA0OTM4MTAwNGRkXUfhlDv1Cs7/qhBlyZROCzlvf5U=" />
这个原理和Cookies大同小异,只是每次请求和响应所附带的信息变成了表单变量。
通过QueryString保持状态
这个原理和上述两种状态保持方法原理是一样的,QueryString通过将信息保存在所请求地址的末尾来向服务器传送信息,通常和表单结合使用,一个典型的QueryString比如:
www.xxx.com/xxx.aspx?var1=value&var2=value2
总结
本文从一个比较高的视角来看HTTP协议,对于HTTP协议中的细节并没有深挖,但对于HTTP大框架有了比较系统的介绍,更多关于HTTP的细节信息,请去Bing或参看相关书籍:-)





