
本次案例用到的是kaggle网站(Bike Sharing Demand | Kaggle)提供了某城市的共享单车2011年到2012年的数据集。该数据集包括了租车日期,租车季节,租车天气,租车气温,租车空气湿度等数据。本次将使用python对这一数据集进行探索性分析,以了解共享单车的租用情况与哪些因素有关。
Data Fields(数据特征描述):
datatime - 日期+时间
season -
1=春天
2=夏天
3=秋天
4=冬天
holiday - 是否是节假日
workingday -
1=工作日
0=周末
weather -
1:晴天,多云
2:雾天,阴天
3:小雪,小雨
4:大雨,大雪,大雾
temp - 气温摄氏度
atemp - 体感温度
humidity - 湿度
windspeed - 风速
casual - 非注册用户个数
registered - 注册用户个数
count - 给定日期时间(每小时)总租车人数
0,环境搭建
环境:win10+Anaconda +jupyter Notebook
包:
数据分析包:Numpy,pandas,
画图包:matplotlib,seaborn ,
缺失值可视化查询包:missingno
日期变量处理相关的包:calendar,datetime
1,准备工作
用jupyter notebook处理数据,需要先做一些准备,需先把一些必要的数据分析包导入操作台。
#数据处理包导入
import numpy as np
import pandas as pd
#画图包导入
import matplotlib.pyplot as plt
import missingno as msno
import seaborn as sns
sns.set()
#日期处理包导入
import calendar
from datetime import datetime
#jupyter notebook绘图设置
%matplotlib inline
%config InlineBackend.figure_format="retina"
#读取数据
BikeData = pd.read_csv("bike.csv")数据读取后,可以开始对数据进行简单的预览。
预览内容主要包括了解数据集的大小,字段的名称,数据格式等等,为后续的数据处理工作做准备。
数据集大小
BikeData.shape #输出: (10886, 12)
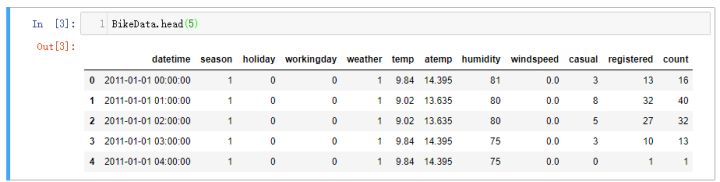
查看数据表中具体的数据内容,不查看所有数据,只查看开始或结束的几行,熟悉一下数据具体内容即可。
BikeData.head(5)
查看数据类型
BikeData.dtypes #输出: datetime object season int64 holiday int64 workingday int64 weather int64 temp float64 atemp float64 humidity int64 windspeed float64 casual int64 registered int64 count int64 dtype: object
2,数据处理
数据处理的内容主要是对数据集进行数据清洗和加工,然数据集变得更利于下一步分析。
具体来说数据清洗包括:查漏,去重,补缺,纠错,而数据加工就是对数据集字段进行提取,计算,分组,转换等操作。
这一步骤也叫做特征构造。
日期字段的处理,从"datetime"字段中,提取"date,"hour","weekDay","month"
#提取“date”
BikeData["date"] = BikeData.datetime.apply(lambda x: x.split()[0])
#提取"hour"
BikeData["hour"]=BikeData.datetime.apply(lambda x: x.split()[1].split(":")[0])
dateString = BikeData.datetime[1].split()[0]
#提取"weekday"
BikeData["weekday"] = BikeData.date.apply(lambda dateString : calendar.day_name[datetime.strptime(dateString,"%Y-%m-%d").weekday()])
#提取"month"
BikeData["month"] = BikeData.date.apply(lambda dateString: calendar.month_name[datetime.strptime(dateString,"%Y-%m-%d").month] )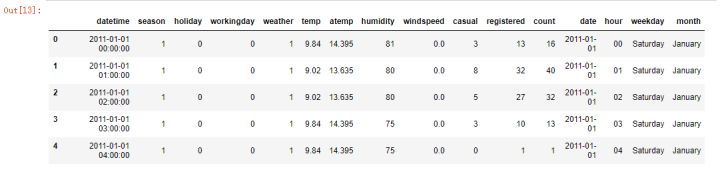
变量映射处理,把数据集中"season","weather"字段属于定性变量,将定性变量的数值取值,做映射处理,转化为描述性取值
#季节映射处理
BikeData["season_label"] = BikeData.season.map({1: "Spring", 2 : "Summer", 3 : "Fall", 4 :"Winter" })
#天气映射处理
BikeData["weather_label"] = BikeData.weather.map({1:"sunny",2:"cloudy",3:"rainly",4:"bad-day"})
#是否是节假日映射处理
BikeData["holiday_map"] = BikeData["holiday"].map({0:"non-holiday",1:"hoiday"})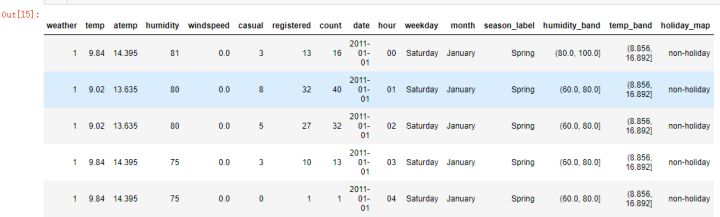
缺失值处理,数据缺失值是影响数据集的质量的一个重要因素,需要看看缺失值的情况。
#可视化查询缺失值 msno.matrix(BikeData,figsize=(12,5))

从上面看到,本次数据集没有缺失值。
如果数据集中有缺失值,在缺失值处理中,我们一般会删除缺失值。pandas模块中,提供了将包含NaN值的行删除的方法dropna(),但其实处理缺失值最好的思路是“用最接近的数据替换它”
对于数值型数据,可用该列的数据的均值或者中位数进行替换。
对于分类型数据,可利用该列数据的出现频数最多的数据(众数)来填充。
实在处理不了的空值,可以暂时先放着,不必着急删除。因为在后续的情况可能会出现:后续运算可以跳过该空值进行。
3,数据分析(数据探索和可视化)
数据科学通常被认为完全是由高等统计学和机器学习技术组成。然而,另一个重要组成部分往往被低估或遗忘:探索性数据分析(Exploratory Data Analysis,简称EDA)。
EDA指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。
我们来探索文章开头提出的问题:
共享单车的租用情况与哪些因素有关?
correlation = BikeData[["temp","atemp","casual","registered","humidity","windspeed","count"]].corr() mask = np.array(correlation) mask[np.tril_indices_from(mask)] = False fig,ax= plt.subplots() fig.set_size_inches(20,10) sns.heatmap(correlation, mask=mask,vmax=.8, square=True,annot=True) plt.show()
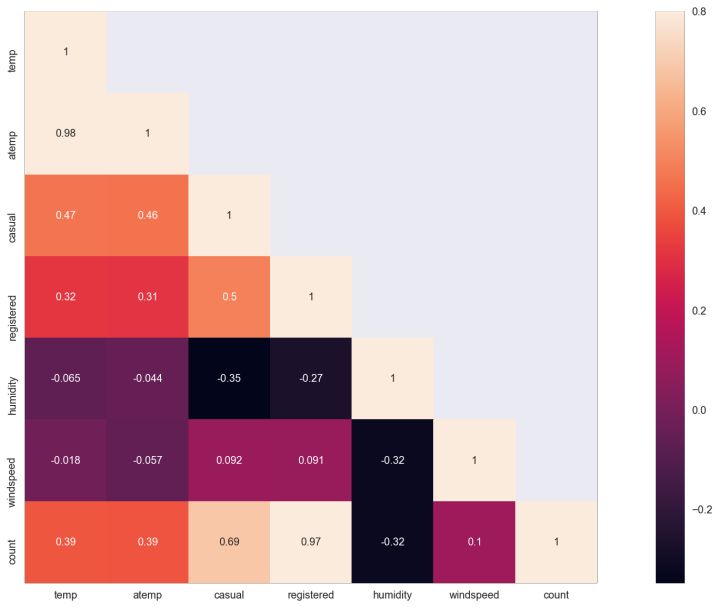
insight:
count 和 registered、casual高度正相关,相关系数分别为0.69 与0.97。因为 count = casual + registered ,所以这个正相关和预期相符。
count 和 temp 正相关,相关系数为 0.39。一般来说,气温过低人们不愿意骑车出行。
count 和 humidity(湿度)负相关,湿度过大的天气不适宜骑车。当然考虑湿度的同时也应该考虑温度。
windspeed似乎对租车人数影响不大(0.1),但我们也应该考虑到极端大风天气出现频率应该不高。风速在正常范围内波动应该对人们租车影响不大。
租车人数,按不同的因素划分的分布情况
# 设置绘图格式和画布大小 fig, axes = plt.subplots(nrows=2,ncols=2) fig.set_size_inches(12, 10) # 添加第一个子图, 租车人数分布的箱线图 sns.boxplot(data=BikeData,y="count",orient="v",ax=axes[0][0]) #添加第二个子图,租车人数季节分布的箱线图 sns.boxplot(data=BikeData,y="count",x="season",orient="v",ax=axes[0][1]) #添加第三个子图,租车人数时间分布的箱线图 sns.boxplot(data=BikeData,y="count",x="hour",orient="v",ax=axes[1][0]) #添加第四个子图,租车人数工作日分布的箱线图 sns.boxplot(data=BikeData,y="count",x="workingday",orient="v",ax=axes[1][1]) # 设置第一个子图坐标轴和标题 axes[0][0].set(ylabel='Count',title="Box Plot On Count") # 设置第二个子图坐标轴和标题 axes[0][1].set(xlabel='Season', ylabel='Count',title="Box Plot On Count Across Season") # 设置第三个子图坐标轴和标题 axes[1][0].set(xlabel='Hour Of The Day', ylabel='Count',title="Box Plot On Count Across Hour Of The Day") # 设置第四个子图坐标轴和标题 axes[1][1].set(xlabel='Working Day', ylabel='Count',title="Box Plot On Count Across Working Day") plt.show()
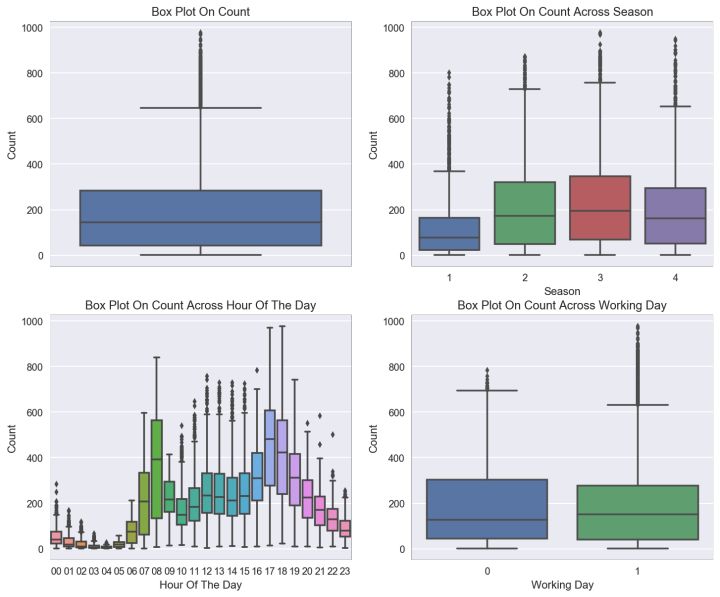
insight:
从“Hour Of The Day”这幅图看到,此图有双高峰,一个是7- 8 点,另外两个是 17 -18 点。按照上班群体的角度看,正好是上下班的早晚高峰。
什么样的温度和湿度情况下租车的人数最多?
#温度和湿度离散化
BikeData["humidity_band"] = pd.cut(BikeData['humidity'],5)
BikeData["temp_band"] = pd.cut(BikeData["temp"],5)
#假期字段映射处理
BikeData["holiday_map"] = BikeData["holiday"].map({0:"non-holiday",1:"hoiday"})
sns.FacetGrid(data=BikeData,row="humidity_band",size=3,aspect=2).\
map(sns.barplot,'temp_band','count','holiday_map',palette='deep',ci=None).\
add_legend()
plt.show()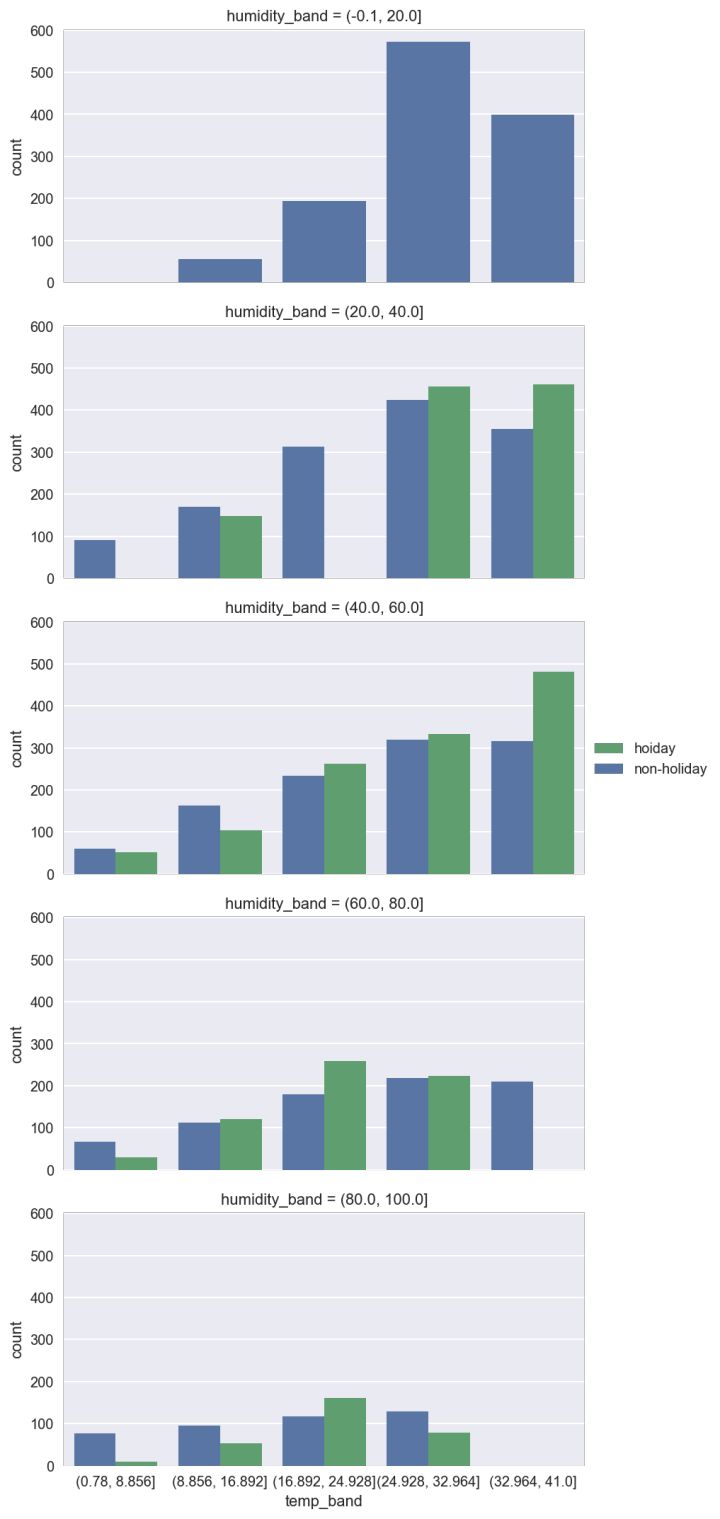
insight:
湿度在 0-60, 温度在20-40之间的租车人数较多。
一般情况下,假日的平均租车人数比非假日多。
寒冷的天气下,非假日的租车人数比假日多。
不同季节下每小时平均租车人数如何变化?
sns.FacetGrid(data=BikeData,size=8,aspect=1.5).\ map(sns.pointplot,'hour','count','season_label',palette="deep",ci=None).\ add_legend() plt.show()
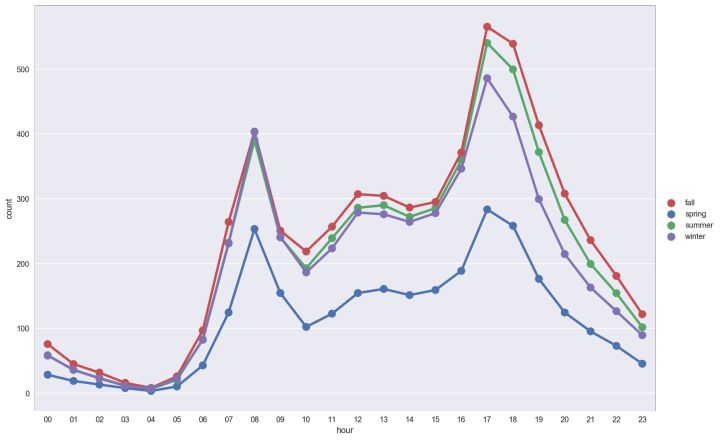
insight:
秋天和夏天租车人数最多
春天租车人数显著低于其他季节
不同天气情况下,每个月的平均租车人数如何变化?
sns.FacetGrid(data=BikeData,size=8,aspect=1.5).\ map(sns.pointplot,'month','count','weather_label',palette="deep",ci=None).\ add_legend() plt.show()
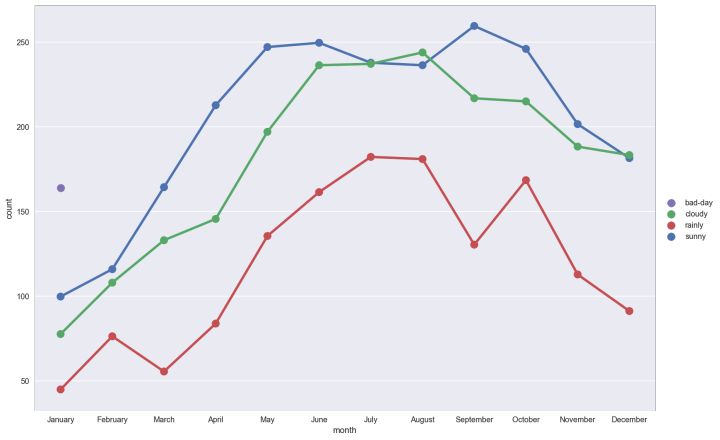
insgth:
总体上,天气越好,租车的人数越多(晴天 > 多云、阴天 > 雨天)
5-10月的租车人数较多,从1月到5月,总体呈上升趋势,10月以后有明显的下降趋势。
按星期数划分,每小时的平均租车人数如何变化?
sns.FacetGrid(data=BikeData,size=8,aspect=1.5).\ map(sns.pointplot,'hour','count','weekday',palette="deep",ci=None).\ add_legend() plt.show()
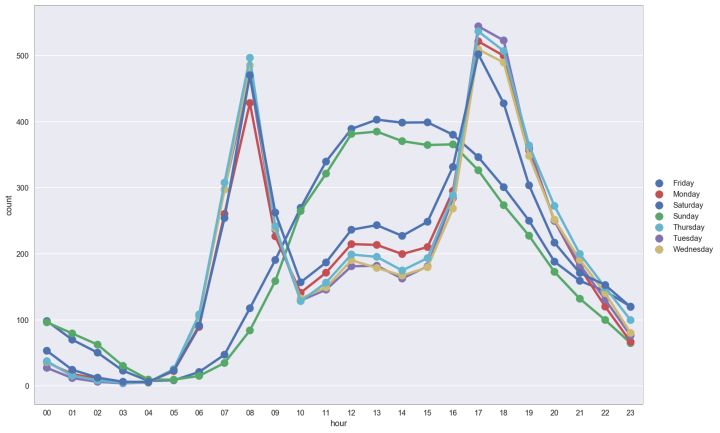
insight:
周六和周天租车高峰期在下午期间。
工作日租车的高峰期是上下班高峰期。
结束语:
在深入机器学习或统计建模之前,EDA是一个重要的步骤,EDA目的是最大化对数据的直觉,完成这个事情的方法只能是结合统计学的图形以各种形式展现出来。通常涉及以下几种方法的组合:
原始数据集中每个字段的单变量可视化和汇总统计
数据集中每个自变量与目标变量之间的关系的双变量可视化和汇总统计
多元可视化以了解数据中不同字段之间的交互作用
让观察值聚类成有区别的小组






热门评论
-

朱可耐2021-01-04 0
-

qq_慕虎24654802019-05-16 0
-

qq_慕虎24654802019-05-16 0
查看全部评论你好,数据可以发一份嘛
你好,你的数据可以提供下吗?急用,谢谢
你好,你下载的数据可以给我提供一份吗?我去下载的跟你们的不一样,谢谢