
如我们所知,大家在介绍表分区的时候一直在歌颂其好处。但一句古谚语说的好,每个人都有其阴暗面,表分区也会在特定情况下反而降低其性能。
例如:
CREATE TABLE dbo.Orders ( Id INT NOT NULL , OrderDate DATETIME NOT NULL , DateModified DATETIME NOT NULL , Placeholder CHAR(500) NOT NULL CONSTRAINT Def_Data_Placeholder DEFAULT 'Placeholder', );
CREATE UNIQUE CLUSTERED INDEX IDX_Orders_Id ON dbo.Orders(ID);
然后插入测试数据:
WITH N1 ( C ) AS ( SELECT 0 UNION ALL SELECT 0 )-- 2 rows , N2 ( C ) AS ( SELECT 0 FROM N1 AS T1 CROSS JOIN N1 AS T2 )-- 4 rows , N3 ( C ) AS ( SELECT 0 FROM N2 AS T1 CROSS JOIN N2 AS T2 )-- 16 rows , N4 ( C ) AS ( SELECT 0 FROM N3 AS T1 CROSS JOIN N3 AS T2 )-- 256 rows , N5 ( C ) AS ( SELECT 0 FROM N4 AS T1 CROSS JOIN N4 AS T2 )-- 65,536 rows , N6 ( C ) AS ( SELECT 0 FROM N5 AS T1 CROSS JOIN N2 AS T2 CROSS JOIN N1 AS T3 )-- 524,288 rows , IDs ( ID ) AS ( SELECT ROW_NUMBER() OVER ( ORDER BY ( SELECT NULL ) ) FROM N6 ) SELECT * FROM IDs INSERT INTO dbo.Orders ( ID , OrderDate , DateModified ) SELECT ID , DATEADD(second, 35 * ID, @StartDate) , CASE WHEN ID % 10 = 0 THEN DATEADD(second, 24 * 60 * 60 * ( ID % 31 ) + 11200 + ID % 59 + 35 * ID, @StartDate) ELSE DATEADD(second, 35 * ID, @StartDate) END FROM IDs;
插入测试数据的代码貌似复杂,其实只是通过递归CTE的办法生成自1开始的数字,然后为每一个行插入略微递增的日期。对于modifyDate列,每10个记录插入一个略微大的值。此时执行如下查询:
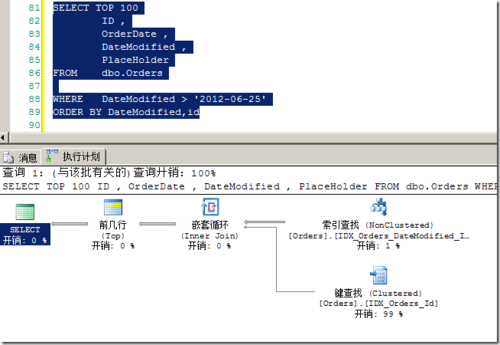
对应的,得到的统计信息:
(100 行受影响) 表 'Orders'。扫描计数 1,逻辑读取 310 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 SQL Server 执行时间: CPU 时间 = 15 毫秒,占用时间 = 756 毫秒。
我们DROP掉上面的索引后,重新进行表分区,如代码3所示:
--drop索引
DROP INDEX IDX_Orders_DateModified_Id ON dbo.Orders;
DROP INDEX IDX_Orders_Id ON dbo.Orders;
GO
--分区函数
CREATE PARTITION FUNCTION pfOrders(DATETIME)
AS RANGE RIGHT FOR VALUES
('2012-02-01', '2012-03-01',
'2012-04-01','2012-05-01','2012-06-01',
'2012-07-01','2012-08-01');
GO
--分区方案
CREATE PARTITION SCHEME psOrders
AS PARTITION pfOrders
ALL TO ([primary]);
GO
--再次创建聚集索引
CREATE UNIQUE CLUSTERED INDEX IDX_Orders_OrderDate_Id
ON dbo.Orders(OrderDate,ID)
ON psOrders(OrderDate);
GO
--再次创建非聚集索引
CREATE UNIQUE INDEX IDX_Data_DateModified_Id_OrderDate
ON dbo.Orders(DateModified, ID, OrderDate)
ON psOrders(OrderDate);然后,我们通过代码2中的代码,再次插入测试数据。然后再次运行图1中所示查询,得到的结果如图2所示。
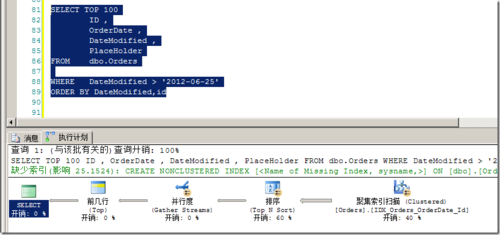
由执行计划可以看出,查询完全忽视了非聚集索引的存在,进行了表扫描。因此产生了巨大的消耗。
对应的统计信息,如下:
(100 行受影响) 表'Worktable'。扫描计数0,逻辑读取0 次,物理读取0 次,预读0 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。 表'Orders'。扫描计数2,逻辑读取10071 次,物理读取0 次,预读2 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。 SQL Server 执行时间: CPU 时间= 219 毫秒,占用时间= 783 毫秒。
不难看出,性能下降的十分明显。
因此,不要在生产环境中数据量一大就想到表分区。在进行表分区之前,首先考虑一下对分区计划进行测试,否则在生产环境中出现上面的情况就悲剧了。



