
大多数开发人员的主要时间都是花费在与现有的软件打交道上,而不是编写全新的应用程序。
这就意味着,我经常要遇到很多我写的 shit 一样的代码,你经常要遇到很多你写的 shit 一样的代码。不对,别人要经常遇到别人写的 shit 一样的代码。总之,你写的代码可能不是 shit,但是你看别人的可能就是。
先说结论——适合阅读人群:
有一定工作经验(2~3 年),并且对代码有追求的程序员。
面向复杂的遗留/旧系统,无法下手的项目。
熟悉面向对象的程序员
如果你工作 2~3 年,并且遇到瓶颈,也不妨来看看。
引言
不过这些并不重要,重要的是,你遇到一坨代码时,你要怎么做?
正确的做法应该是这样的(PS:我整理了两个晚上的图):
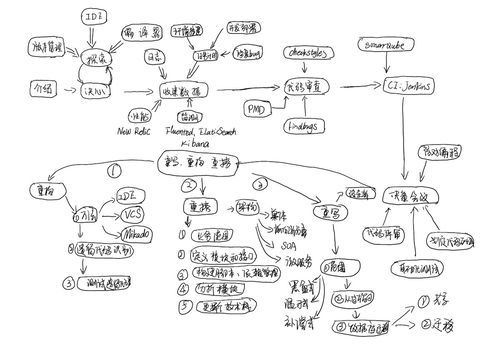
对, 这就是这本书的主要流程(前 6 章)。
后四章的内容在讲重构以外的东西,比如自动化开发环境、自动化部署、使用持续集成。很多知识点和工具上,与《全栈应用开发:精益实践》一书是相似的。如果你熟悉书中的 RePractise 一图的话:
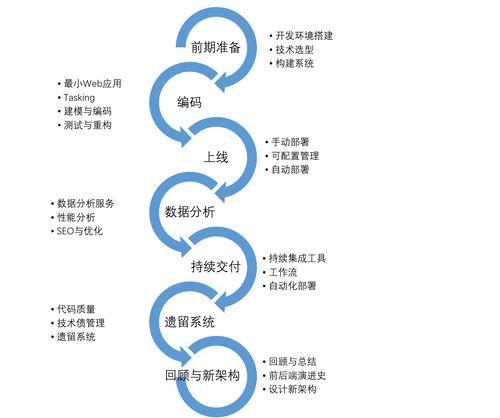
很多流程都是相似的,唯一不同的是起点。《全栈应用开发:精益实践》一书的终点,是《遗留系统:重建实战》的起点。我们在之前写了那么多的代码,有一天成为了遗留代码,这些代码可能会到别人的手里,也可能回到我们自己的手里。这时,我们应该怎么做了。
要点
考虑到,这本书的内容这么多,并且已经有了上面的那张图,我这里就只列出一些比较重要的知识:
进行重构计划之前
先进行探索性重构——使用 IDE、编译器辅助、版本管理
收集数据来对项目进行评估——性能、错误日志、异常监测
对常见任何进行计时——环境搭建时间、开发部署、修复bug
使用代码审查工具,如 PMD、Findbugs、CheckStyles
使用 Jenkins 和 SonarQube 进行持续检查
重构决策会议
会议应该决定重构、重写或者重搭
重构
这一个篇幅里,着重介绍如何识别遗留代码及测试。至于重构相关的内容,可以参见《重构》一书。
重搭
方法:
识别业务和重搭范围
定义模块和接口
构建脚本和依赖管理
分拆模块
更新技术栈
重写
确认重写范围:黑盒式、温习式、补偿式
从过去学习
数据库迁移:共享或迁移
结论
从重构项目中学习,更容易学到新的东西。






