package com.pthc.com.mr;
import java.io.IOException;
import java.util.Set;
import java.util.TreeMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountTopN{
// map
public static class WordCountTopNMap extends Mapper<LongWritable, Text, Text, IntWritable> {
private final IntWritable ONE = new IntWritable(1);
private Text outkey = new Text();
private String[] infos;
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
infos = value.toString().split("[\\s\"\\(\\)]+");
for (String word : infos) {
outkey.set(word);
context.write(outkey, ONE);
}
}
}
// combinner
public static class WordCountTopNReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private int sum;
private Text outkey = new Text();
private IntWritable outvalue = new IntWritable();
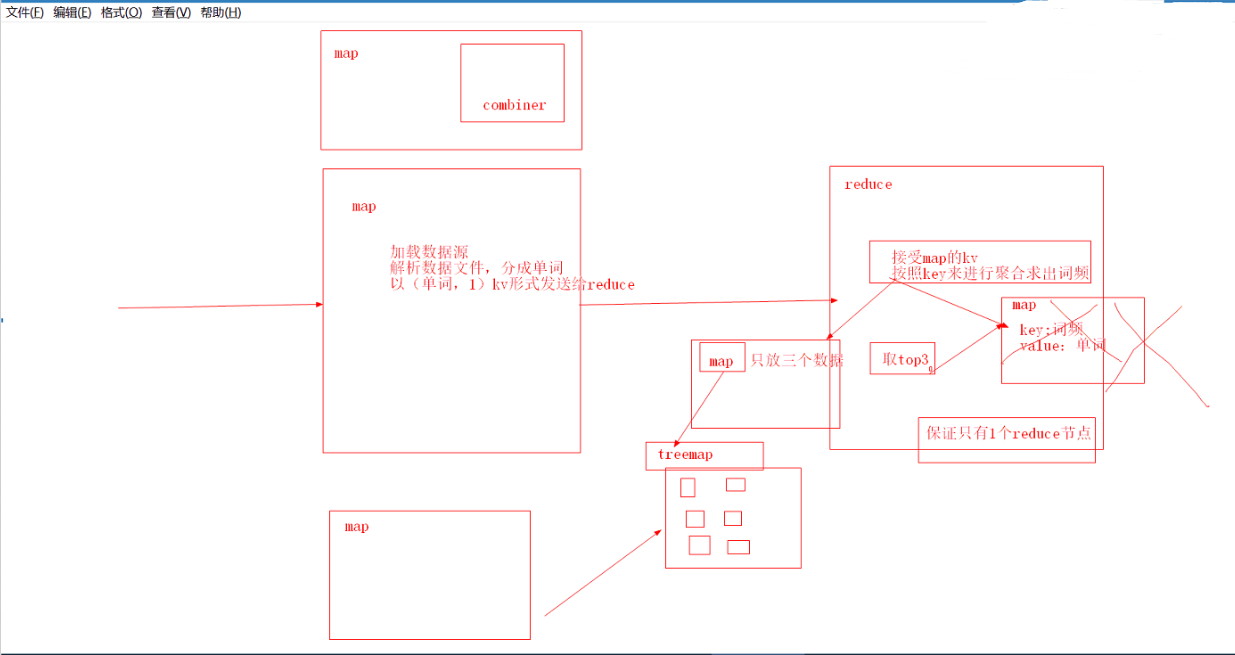
// 开辟内存空间保存topN
// treeMap是一个排序的map.按照key进行排序
private TreeMap<Integer, String> TopN = new TreeMap<Integer, String>();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
// 把计算结果放入topN,如果topN中不满N个元素的话,可以直接往里面方然后还得
// 先看topN中有没有相同的key,如果有吧topN中相同key对相应的value单词穿在一起,如果没有的话,就直接放进去
if (TopN.size() < 3) {
if (TopN.get(sum) != null) {
TopN.put(sum, TopN.get(sum) + "-----" + key.toString());
} else {
TopN.put(sum, key.toString());
}
} else {
// 大于等于N的话.放进去一个,然后在删除掉一个,始终保持topN中有N个元素
if (TopN.get(sum) != null) {
TopN.put(sum, TopN.get(sum) + "------" + key.toString());
// 因为有同key,是归并操作,因此没有增也不用删
} else {
TopN.put(sum, key.toString());
TopN.remove(TopN.lastKey());
}
}
// 放进去后treemap会自动排序,这时候把最后一个删掉,保证topN中只有n个kv对
}
@Override
protected void cleanup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
if (TopN != null && !TopN.isEmpty()) {
Set<Integer> keys = TopN.keySet();
for (Integer key : keys) {
outkey.set(TopN.get(key));
outvalue.set(key);
context.write(outkey, outvalue);
}
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(WordCountTopN.class);
job.setJobName("topN");
job.setMapperClass(WordCountTopNMap.class);
job.setCombinerClass(WordCountTopNReducer.class);
job.setReducerClass(WordCountTopNReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path inputPath = new Path("/Invert/reverse1.txt");
Path outputDir = new Path("/Invert/WordCountTopN");
outputDir.getFileSystem(configuration).delete(outputDir, true);
FileInputFormat.addInputPath(job, inputPath);
FileOutputFormat.setOutputPath(job, outputDir);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
打开App,阅读手记











热门评论
-

会飞的兔子c2017-10-18 1
-

JetaimeCsj2017-10-16 1
查看全部评论备注太少了,对于我这中小白完全看不懂