2.1 Hadoop简介
面对数据量日益增大的今天,如何面对大数据量的处理需求,这是一个问题。一台机器解决不了的问题,那就放在多台机器上,把大量的数据分割成互不依赖的小份数据,在每台机器上处理,这就是分而治之的思想体现。Hadoop为这种云计算需求提供了一套计算框架和分布式文件系统。起初的Hadoop框架一提出,立马就能想到他的MapReduce编程模型和HDFS分布式文件系统,随着技术不断的发展,现在提到Hadoop都在指向Hadoop生态这个概念。Hive,Pig,Hbase等子项目填充Hadoop生态圈中,使得能为用户提供更好的更多样性的服务。起初的Hadoop1.x版本,由于核心架构问题,导致扩展性不是很好,Hadoop的工程师们意识到这个问题,重新设计核心架构,现在大部分公司都在使用的Hadoop2.x诞生了。
2.2 MapReduce编程模型简介
提到Hadoop,不得不提MapReduce编程模型。该模型的提出,使得用商务服务器搭建的大规模集群处理千兆级数据量成为现实。
MapReduce编程模型需要两个步骤,Map和Reduce。这个两个步骤需要用户编写代码,来让框架了解用户需要如何处理数据。其他的许多细节问题都被Hadoop框架所处理好了。什么样的状况下才需要使用Hadoop框架呢?我们试想完成一个这样的程序,它需要统计出一篇文档中的每个单词的数量,我们假定每个单词用空格分隔。显而易见,我们想的是把文档加载进内存,定义一个HashMap,单词为key,词数位value,文档每行用空格分隔,从而统计出词频。若文档足够小,这是可以实现的,可是当你有成百上千的文档,加起来数量级达到了T量级,一台机器的内存如何能够放下,就算采取折中的办法分批读,逐步统计,可这花费的时间是不足以忍受的。这个时候我们就需要使用Hadoop框架来完成我们的任务。下图所示的是MapReduce模型。

MapReduce首先将输入数据逻辑上分割成多个数据块,每个数据块被一个用户所定义的Map任务处理,Map任务可以在集群中的任意计算节点上并行运行,Map任务的输出为一个个kv对,且kv对会按照用户定义的逻辑分区,每个kv对都有属于自己的分区,在每个分区中,kv对会按照用户定义的逻辑进行排序,一个分区排序好的kv对数据会发送个一个Reduce任务来处理。
回到刚才的词频统计的问题上来,现在我们需要统计1000W个文件中的词频,我们拥有50台机器,每台机器8核所组成的集群,现在我们假定一个文件由一个Map任务来处理,一台机器有多少个CPU核心数,就能让多少个Map任务并行执行,所以我们要运行1000W个Map任务,每台机器要运行20W个Map任务,每次每台机器同时执行8个,所以共需要25000次执行。每个Map任务抽取该任务所处理文件中的单词,并输出<单词,1>这样的键值对。Reduce任务接收到的数据为<单词,[1,1,1,1........]>,所以我们可以在Reduce任务中写出逻辑,得到词频。过程如下图所示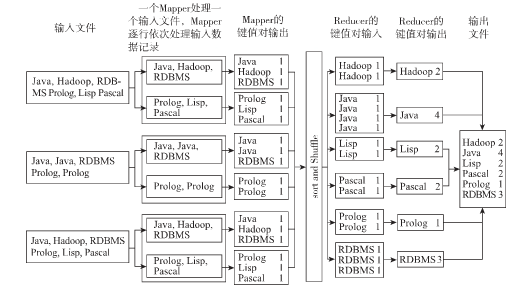
2.3 Hadoop系统的组成
Hadoop1.x有如下几个守护进程
NameNode(名称节点,1个):维护着存储在HDFS上的文件的元数据信息。元数据信息包括数据块信息,以及数据块的位置。
Secondary NameNode(辅助名称节点,1个):并不是NameNode的热备,只是帮助NameNode执行一些内务处理。
DataNode(数据节点,多个):把文件的数据块存放在本地磁盘上。
JobTracker(作业跟踪器,1个):负责一个MapReduce任务的整个执行过程,调度各个子任务(Map任务和Reduce任务)到计算节点运行,监控计算节点的状况,失败任务重新调度。
TaskTracker(任务跟踪器,多个):与JobTracker通信,启动管理各个Map任务和Reduce任务。
2.3.1 HDFS
1 Hadoop的分布式文件系统(HDFS)由上述所述的NameNode,DataNode,Secondary NameNode守护进程提供服务,有一次写多次读的特点。HDFS也使用分而治之的思想,将数据量大的文件分割成数据块存放到不同的运行着DataNode守护进程的集群节点上,满足用户存储大数据量文件的需求。HDFS对上提供一个统一的文件系统命名空间,从而使得用户感觉不到集群的存在。
2 HDFS把文件分割成的数据块大小可以由用户设置,1.x默认为64MB,2.x为128MB。每个数据块不单单只存储一份,为了集群的稳定性,通常会把每个数据块冗余备份,多存储几份。默认为存储3份,当然这也可以设置。
3 NameNode负责维护文件的元数据信息,包括文件/目录的名称及相对于父目录的位置,所有权和权限,文件所对应的各个数据块的名称。但要注意,NameNode并不负责存储各个数据块的位置,这个信息是当集群启动时从DataNode获取。集群启动时,NamoNode会把存储在本地磁盘上的元数据信息载入到内存中,方便用户快速的访问。因为对于每个数据块都要存储元数据信息,所以HDFS不适用于存储多个小文件,因为每个小文件都会记录元数据信息,这些大量的元数据信息会导致占用更多的内存,海量的小文件会拖垮运行NameNode的服务器。
4 HDFS写文件过程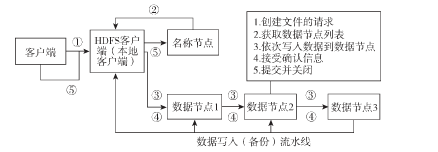
(1)客户端流式把要写入的文件读到本地文件系统一个临时目录中,当读到一个数据块大小时,通知NameNode。
(2) NameNode把这个数据块的标识符和应该存储到哪台节点的位置信息发送回客户端(因为备份数目为3,我们默认返回3个数据节点的位置)。
(3) 客户端根据位置信息,把数据块发送到第一个数据节点上,此时第一个数据节点,还会把这个数据块发送给第二个数据节点,第二个则会发送给第三个。三台节点写完后,这个数据块及其备份就存储好了(除了存储了数据块,还会为每个数据块存储一个校验和,用来在读取的时候检验文件是否完整)。第三个数据节点会把确认信息发回给第二个,第二个给第一个,第一个给客户端,客户端发送确认信息给NameNode节点。其中若有一个数据节点发生故障,NameNode会重新寻找状态良好的运行着DataNode的数据节点,重新执行备份操作。
(4) 文件的数据块都被保存时,NameNode会执行一个提交操作,使得文件在HDFS中可见。
5 HDFS读过程
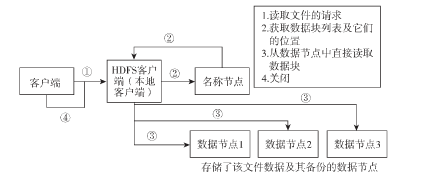
(1) 客户端访问NameNode,NameNode返回文件的数据块列表及位置(包括备份的数据块)
(2) 客户端通过位置信息,访问运行着DataNode的数据节点,从而访问数据块数据,若数据节点有故障,或者计算的数据块校验和不正确,就会访问存放备份数据块的数据节点。
2.3.2 Secondary NameNode
NameNode的元数据信息存放在本地文件系统中的fsimage文件中,Hadoop系统在运行时,对于文件的一系列操作除了改变了存放在内存中的元数据信息,这些操作记录还被记录在edits本地文件中,防止Hadoop重启后在内存中改变的元数据信息不丢失。
可若是Hadoop系统每次启动时,把edits记录的操作应用到fsimage文件中,这显然是不太可靠的办法。Secondary NameNode就是解决这一问题的,它会周期性的把edits的操作与fsimage文件合并。过程如下。
(1)Secondary NameNode通知NameNode,它要合并edits和fsimage文件了,NameNode会在此刻把新的操作记录到edits.new中。
(2) Secondary NameNode获取fsimage和edits文件,合并生成一个新的fsimage文件。
(3)NameNode从Secondary NameNode获取新的fsimage文件,替代旧的文件,同时将edit.new的内容替换带edit文件中。
2.3.3 TaskTracker
TaskTracker守护进程会根据他所在的机器来拥有一定数量的槽位,槽位数量一般与CPU核数一致。TaskTracker接受来自JobTracker的任务请求(诸如Map,Reduce,Shuffle任务),为一个任务分配槽位,启动jvm,向JobTracker反馈任务的运行状况,并向JobTracker报告当前可用的槽位。
2.3.4 JobTracker
JobTracker负责启动和监控MapReduce作业,过程如下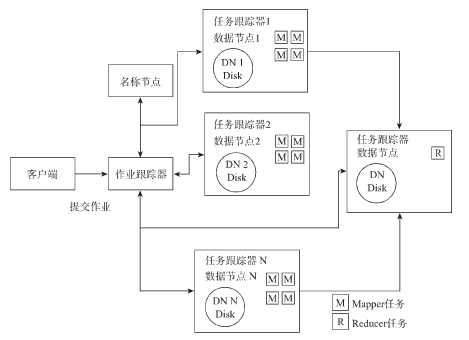
(1)JobTracker接受作业的请求,因为作业需要的数据存储在HDFS上,所以它会请求NameNode获取对应文件数据块列表
(2)TaskTracker确定运行该作业需要的任务(Map,Reduce)数量,JobTracker尽量把这些任务调度到里数据块近的位置。
(3)JobTracker把任务分发给TaskTracker,并按照设定的时间间隔,接收来自TaskTracker的任务运行信息。若时间间隔内,某些TaskTracker并没有发送心跳信息给JobTracker,JobTracker会把原先运行在该TaskTracker上的任务调度给其他的TaskTracker上。
(4) 所有任务执行完毕,任务成功,若任务失败次数达到设定值,则任务失败。
2.4 Hadoop2.0
在Hadoop1.x中,我们可以发现在作业执行方面Hadoop框架有着两大功能,资源管理和任务调度与监控。Hadoop2.x针对这个两方面功能,摒弃了原来的JobTracker和TaskTracker设计,专门设计了一个全局的资源管理器和每种程序所对应的一个应用程序管理器。Hadoop生态圈随着时间不断扩大,MapReduce不能适用于所有场景,所以诸如Spark等其他的计算框架出现了。为了使计算框架能统一使用底层的HDFS,在集群中有个统一的资源管理方式,Hadoop2.x引入了yarn这一资源管理器,其上不单单可以运行MapReduce作业,其他计算框架作业也可以在其上运行,使之都能运行在统一的Hadoop系统之上。
Yarn由以下几部分组成
ResourceManager(全局资源管理器,守护进程,一个)
NodeManager(节点管理器,守护进程,多个)
ApplicationMaster(应用程序管理器)
Scheduler(调度器)
Container(容器)
2.4.1 容器
容器是yarn中的计算单元,是已分配的一组计算资源 (Cpu核心数和内存),集群中的一个节点可以运行多个容器,是一个任务执行的单元。
2.4.2 NodeManager
运行在集群中节点上的一个守护进程,接收ResourceManager的请求,负责分配本机上的容器给应用程序,管理已启动容器的生命周期,监控本节点的健康状况,向ResoureceManager汇报本机可用资源数量。
2.4.3 REsoureceManager
运行在集群中节点上的一个守护进程,全局一个。负责集群整体的资源调度,其中REsourceManager有一个插件化的调度器,不同的调度器根据不同的方式为多个提交到yarn上的应用程序分配集群的资源。
2.4.4 ApplicationMaster
提交到yarn上不同种类(如MapREduce,Spark)的应用程序会对应着不同的ApplicationMaster。ApplicationMaster负责管理他所负责类型的应用程序的执行,请求资源时则与ResoureceManager协商解决,通过NodeManager获得资源(容器),从而执行任务。可以说,ApplicationMaster是Hadoop1.x与2.x最大的区别,在1.x中,JobTracker除了要给所要执行的程序分配资源,作业的运行,失败重启等也需要JobTracker。2.x中管理作业这一方面由ApplicationMaster负责,且我们说过,ApplicationMaster支持不同类型的应用程序,不再仅仅局限于MapReduce。这样使得Hadoop更加通用,可以支持不同种类的计算框架,相互协作工作。
2.4.5 Hadoop2.x的作业执行过程
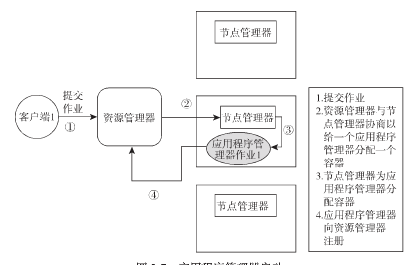
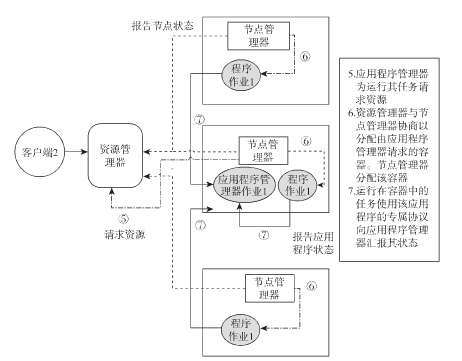
(1)客户端提交作业,确定应用程序类型,确定使用何种ApplicationMaster。
(2) ResoureceManager与NodeManager协调资源,给ApplicationMaster一个容器运行。ApplciationMaster在REsourceManager中注册。
(3)ApplciationMaster向REsourceManager协商资源,REsourceManager与NodeManager协商来分配ApplciationMaster请求的容器。NodeManager分配容器。
(4) 运行在容器中的任务向ApplciationMaster汇报其状态。