
之前我们都是学习使用MapReduce处理一张表的数据(一个文件可视为一张表,hive和关系型数据库Mysql、Oracle等都是将数据存储在文件中)。但是我们经常会遇到处理多张表的场景,不同的数据存储在不同的文件中,因此Hadoop也提供了类似传统关系型数据库的join操作。Hadoop生态组件的高级框架Hive、Pig等也都实现了join连接操作,编写类似SQL的语句,就可以在MapReduce中运行,底层的实现也是基于MapReduce。本文介绍如何使用MapReduce实现join操作,为以后学习hive打下基础。
1、Map端连。
数据在进入到map函数之前就进行连接操作。适用场景:一个文件比较大,一个文件比较小,小到可以加载到内存中。如果两个都是大文件,就会出现OOM内存溢出的异常。实现Map端连接操作需要用到Job类的addCacheFile()方法将小文件分发到各个计算节点,然后加载到节点的内存中。
下面通过一个例子来实现Map端join连接操作:
1、雇员employee表数据如下:
name gender age dept_no
Tom male 30 1
Tony male 35 2
Lily female 28 1
Lucy female 32 3
2、部门表dept数据如下:
dept_no dept_name
1 TSD
2 MCD
3 PPD
代码实现如下:

1 package join; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.conf.Configured; 5 import org.apache.hadoop.fs.FileSystem; 6 import org.apache.hadoop.mapreduce.Job; 7 import org.apache.hadoop.mapreduce.Reducer; 8 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 9 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 10 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 11 import org.apache.hadoop.util.Tool; 12 import org.apache.hadoop.io.*; 13 import org.apache.hadoop.util.ToolRunner; 14 import org.apache.hadoop.mapreduce.Mapper; 15 16 import java.io.BufferedReader; 17 import java.io.FileReader; 18 import java.io.IOException; 19 import java.net.URI; 20 import java.util.HashMap; 21 import java.util.Map; 22 import org.apache.hadoop.fs.Path; 23 24 public class MapJoin extends Configured implements Tool { 25 26 public static class MapJoinMapper extends Mapper<LongWritable, Text, Text,NullWritable> { 27 private Map<Integer, String> deptData = new HashMap<Integer, String>(); 28 29 @Override 30 protected void setup(Mapper<LongWritable, Text, Text,NullWritable>.Context context) throws IOException, InterruptedException { 31 super.setup(context); 32 //从缓存的中读取文件。 33 Path[] files = context.getLocalCacheFiles(); 34 // Path file1path = new Path(files[0]); 35 BufferedReader reader = new BufferedReader(new FileReader(files[0].toString())); 36 String str = null; 37 try { 38 // 一行一行读取 39 while ((str = reader.readLine()) != null) { 40 // 对缓存中的数据以" "分隔符进行分隔。 41 String[] splits = str.split(" "); 42 // 把需要的数据放在Map中。注意不能操作Map的大小,否则会出现OOM的异常 43 deptData.put(Integer.parseInt(splits[0]), splits[1]); 44 } 45 } catch (Exception e) { 46 e.printStackTrace(); 47 } finally{ 48 reader.close(); 49 } 50 } 51 52 @Override 53 protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text,NullWritable>.Context context) throws IOException, 54 InterruptedException { 55 // 获取从HDFS中加载的表 56 String[] values = value.toString().split(" "); 57 // 获取关联字段depNo,这个字段是关键 58 int depNo = Integer.parseInt(values[3]); 59 // 根据deptNo从内存中的关联表中获取要关联的属性depName 60 String depName = deptData.get(depNo); 61 String resultData = value.toString() + " " + depName; 62 // 将数据通过context写入到Reduce中。 63 context.write(new Text(resultData),NullWritable.get()); 64 } 65 } 66 67 public static class MapJoinReducer extends Reducer<Text,NullWritable,Text,NullWritable> { 68 public void reduce(Text key, Iterable<NullWritable> values,Context context)throws IOException,InterruptedException{ 69 context.write(key,NullWritable.get()); 70 } 71 } 72 73 @Override 74 public int run(String[] args) throws Exception { 75 Configuration conf = new Configuration(); 76 Job job = Job.getInstance(conf, "Total Sort app"); 77 //将小表加载到缓存中。 78 job.addCacheFile(new URI(args[0])); 79 job.setJarByClass(MapJoinMapper.class); 80 //1.1 设置输入目录和设置输入数据格式化的类 81 FileInputFormat.setInputPaths(job,new Path(args[1])); 82 job.setInputFormatClass(TextInputFormat.class); 83 84 //1.2 设置自定义Mapper类和设置map函数输出数据的key和value的类型 85 job.setMapperClass(MapJoinMapper.class); 86 job.setMapOutputKeyClass(Text.class); 87 job.setMapOutputValueClass(NullWritable.class); 88 89 //1.3 设置reduce数量 90 job.setNumReduceTasks(1); 91 //设置实现了reduce函数的类 92 job.setReducerClass(MapJoinReducer.class); 93 94 //设置reduce函数的key值 95 job.setOutputKeyClass(Text.class); 96 //设置reduce函数的value值 97 job.setOutputValueClass(NullWritable.class); 98 99 // 判断输出路径是否存在,如果存在,则删除100 Path mypath = new Path(args[2]);101 FileSystem hdfs = mypath.getFileSystem(conf);102 if (hdfs.isDirectory(mypath)) {103 hdfs.delete(mypath, true);104 }105 106 FileOutputFormat.setOutputPath(job, new Path(args[2]));107 108 return job.waitForCompletion(true) ? 0 : 1;109 }110 111 public static void main(String[] args)throws Exception{112 113 int exitCode = ToolRunner.run(new MapJoin(), args);114 System.exit(exitCode);115 }116 }
执行脚本文件如下::
1 /usr/local/src/hadoop-2.6.1/bin/hadoop jar MapJoin.jar \2 hdfs://hadoop-master:8020/data/dept.txt \3 hdfs://hadoop-master:8020/data/employee.txt \4 hdfs://hadoop-master:8020/mapjoin_output
运行结果:
Lily female 28 1 TSD Lucy female 32 3 PPD Tom male 30 1 TSD Tony male 35 2 MCD
2、Reduce端连接(Reduce side join)。
数据在Reduce进程中执行连接操作。实现思路:在Map进程中对来自不同表的数据打上标签,例如来自表employee的数据打上a标签,来自文件dept表的数据打上b标签。然后在Reduce进程,对同一个key,来自不同表的数据进行笛卡尔积操作。请看下图,我们对表employee和表dept的dept_no字段进行关联,将dept_no字段当做key。
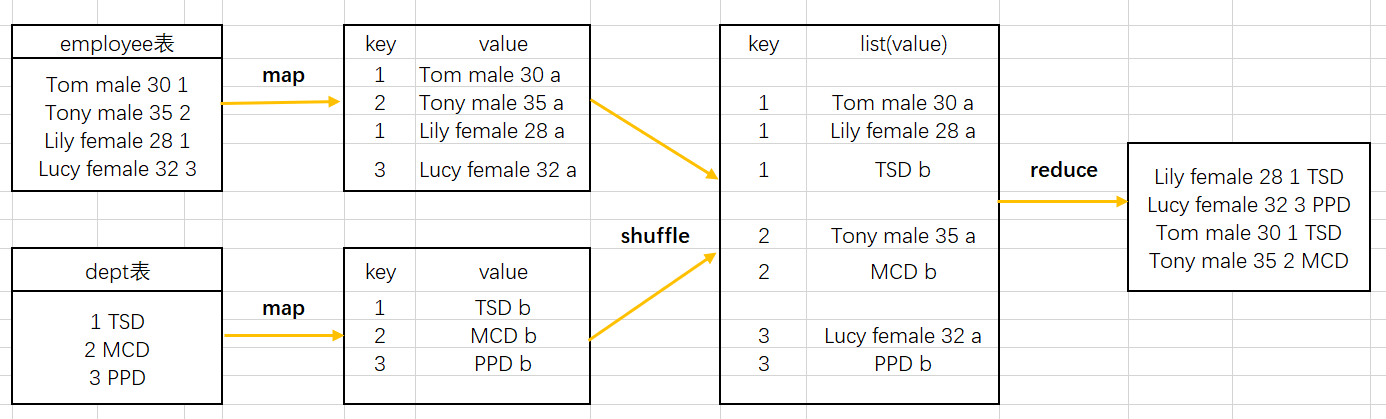
在MapReduce中,key相同的数据会放在一起,因此我们只需在reduce函数中判断数据是来自哪张表,来自相同表的数据不进行join。
代码如下:
1 public class ReduceJoin extends Configured implements Tool { 2 public static class JoinMapper extends 3 Mapper<LongWritable,Text,Text,Text> { 4 String employeeValue = ""; 5 protected void map(LongWritable key, Text value, Context context) 6 throws IOException,InterruptedException { 7 /* 8 * 根据命令行传入的文件名,判断数据来自哪个文件,来自employee的数据打上a标签,来自dept的数据打上b标签 9 */ 10 String filepath = ((FileSplit)context.getInputSplit()).getPath().toString(); 11 String line = value.toString(); 12 if (line == null || line.equals("")) return; 13 14 if (filepath.indexOf("employee") != -1) { 15 String[] lines = line.split(" "); 16 if(lines.length < 4) return; 17 18 String deptNo = lines[3]; 19 employeeValue = line + " a"; 20 context.write(new Text(deptNo),new Text(employeeValue)); 21 } 22 23 else if(filepath.indexOf("dept") != -1) { 24 String[] lines = line.split(" "); 25 if(lines.length < 2) return; 26 String deptNo = lines[0]; 27 context.write(new Text(deptNo), new Text(line + " b")); 28 } 29 } 30 } 31 32 public static class JoinReducer extends 33 Reducer<Text, Text, Text, NullWritable> { 34 protected void reduce(Text key, Iterable<Text> values, 35 Context context) throws IOException, InterruptedException{ 36 List<String[]> lista = new ArrayList<String[]>(); 37 List<String[]> listb = new ArrayList<String[]>(); 38 39 for(Text val:values) { 40 String[] str = val.toString().split(" "); 41 //最后一位是标签位,因此根据最后一位判断数据来自哪个文件,标签为a的数据放在lista中,标签为b的数据放在listb中 42 String flag = str[str.length -1]; 43 if("a".equals(flag)) { 44 //String valueA = str[0] + " " + str[1] + " " + str[2]; 45 lista.add(str); 46 } else if("b".equals(flag)) { 47 //String valueB = str[0] + " " + str[1]; 48 listb.add(str); 49 } 50 } 51 52 for (int i = 0; i < lista.size(); i++) { 53 if (listb.size() == 0) { 54 continue; 55 } else { 56 String[] stra = lista.get(i); 57 for (int j = 0; j < listb.size(); j++) { 58 String[] strb = listb.get(j); 59 String keyValue = stra[0] + " " + stra[1] + " " + stra[2] + " " + stra[3] + " " + strb[1]; 60 context.write(new Text(keyValue), NullWritable.get()); 61 } 62 } 63 } 64 } 65 } 66 67 @Override 68 public int run(String[] args) throws Exception { 69 Configuration conf = getConf(); 70 GenericOptionsParser optionparser = new GenericOptionsParser(conf, args); 71 conf = optionparser.getConfiguration(); 72 Job job = Job.getInstance(conf, "Reduce side join"); 73 job.setJarByClass(ReduceJoin.class); 74 //1.1 设置输入目录和设置输入数据格式化的类 75 //FileInputFormat.setInputPaths(job,new Path(args[0])); 76 FileInputFormat.addInputPaths(job, conf.get("input_data")); 77 78 job.setInputFormatClass(TextInputFormat.class); 79 80 //1.2 设置自定义Mapper类和设置map函数输出数据的key和value的类型 81 job.setMapperClass(JoinMapper.class); 82 job.setMapOutputKeyClass(Text.class); 83 job.setMapOutputValueClass(Text.class); 84 85 //1.3 设置reduce数量 86 job.setNumReduceTasks(1); 87 //设置实现了reduce函数的类 88 job.setReducerClass(JoinReducer.class); 89 90 //设置reduce函数的key值 91 job.setOutputKeyClass(Text.class); 92 //设置reduce函数的value值 93 job.setOutputValueClass(NullWritable.class); 94 95 // 判断输出路径是否存在,如果存在,则删除 96 Path output_dir = new Path(conf.get("output_dir")); 97 FileSystem hdfs = output_dir.getFileSystem(conf); 98 if (hdfs.isDirectory(output_dir)) { 99 hdfs.delete(output_dir, true);100 }101 102 FileOutputFormat.setOutputPath(job, output_dir);103 104 return job.waitForCompletion(true) ? 0 : 1;105 }106 107 public static void main(String[] args)throws Exception{108 int exitCode = ToolRunner.run(new ReduceJoin(), args);109 System.exit(exitCode);110 }111 }
执行MapReduce的shell脚本如下:
1 /usr/local/src/hadoop-2.6.1/bin/hadoop jar ReduceJoin.jar \2 -Dinput_data=hdfs://hadoop-master:8020/data/dept.txt,hdfs://hadoop-master:8020/data/employee.txt \3 -Doutput_dir=hdfs://hadoop-master:8020/reducejoin_output
总结:
1、Map side join的运行速度比Reduce side join快,因为Reduce side join在shuffle阶段会消耗大量的资源。Map side join由于把小表放在内存中,所以执行效率很高。
2、当有一张表的数据很小时,小到可以加载到内存中,那么建议使用Map side join。





