
理论知识回顾
DOM(文档对象模型)是针对HTML和XML文档的一个API(应用程序编程接口)。DOM描绘了一个层次化的节点树,允许开发人员添加、移除和修改页面的某一部分。DOM脱胎于Netscape及微软公司创始的DHTML(动态HTML),但现在它已经成为表现和操作页面标记的真正的跨平台、语言中立的方式。
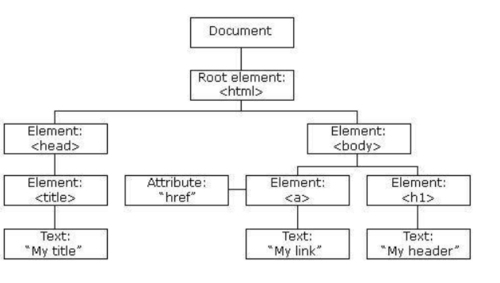
DOM可以将任何HTML或XML文档描绘成一个由多层节点构成的结构。节点分为几种不同的类型,每种类型分别表示文档中不同的信息及(或)标记。每个节点都拥有各自的特点、数据和方法,另外也与其他节点存在某种关系。节点之间的关系构成了层次,而所有页面标记则表现为一个以特定节点为根节点的树形结构
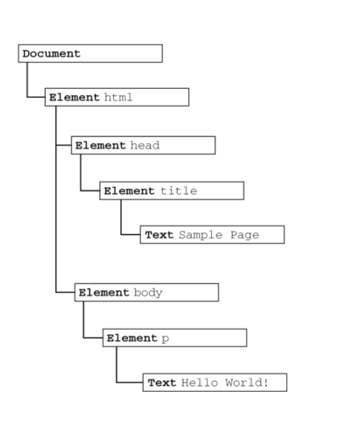
<html> <head> <title>Sample Page</title> </head> <body> <p>Hello World!</p> </body></html>
文档节点是每个文档的根节点。在这个例子中,文档节点只有一个子节点,即<html>元素,我们称之为文档元素。文档元素是文档的最外层元素,文档中的其他所有元素都包含在文档元素中。每个文档只能有一个文档元素。在HTML页面中,文档元素始终都是<html>元素。在XML中,没有预定义的元素,因此任何元素都可能成为文档元素。
每一段标记都可以通过树中的一个节点来表示:HTML元素通过元素节点表示,特性(attribute)通过特性节点表示,文档类型通过文档类型节点表示,而注释则通过注释节点表示。总共有12种节点类型,这些类型都继承自一个基类型。
常见节点类型
Node类型
DOM1级定义了一个Node接口,该接口将由DOM中的所有节点类型实现。每个节点都有一个nodeType属性,用于表明节点的类型。节点类型由在Node类型中定义的下列12个数值常量来表示。
// 确定节点类型if (someNode.nodeType == Node.ELEMENT_NODE){ //在IE中无效
alert("Node is an element.");
}这个例子比较了someNode.nodeType与Node.ELEMENT_NODE常量。如果二者相等,则意味着someNode确实是一个元素。然而,由于IE没有公开Node类型的构造函数,因此上面的代码在IE中会导致错误。为了确保跨浏览器兼容,最好还是将nodeType属性与数字值进行比较,如下所示
if (someNode.nodeType == 1){ //适用于所有浏览器
alert("Node is an element.");
}节点关系
文档中所有的节点之间都存在这样或那样的关系。节点间的各种关系可以用传统的家族关系来描述,相当于把文档树比喻成家谱。在HTML中,可以将<body>元素看成是<html>元素的子元素;相应地,也就可以将<html>元素看成是<body>元素的父元素。而<head>元素,则可以看成是<body>元素的同胞元素,因为它们都是同一个父元素<html>的直接子元素。
每个节点都有一个childNodes属性,其中保存着一个NodeList对象。NodeList是一种类数组对象,用于保存一组有序的节点,可以通过位置来访问这些节点。请注意,虽然可以通过方括号语法来访问NodeList的值,而且这个对象也有length属性,但它并不是Array的实例。NodeList对象的独特之处在于,它实际上是基于DOM结构动态执行查询的结果,因此DOM结构的变化能够自动反映在NodeList对象中。我们常说,NodeList是有生命、有呼吸的对象,而不是在我们第一次访问它们的某个瞬间拍摄下来的一张快照。
Document类型
JavaScript通过Document类型表示文档。在浏览器中,document对象是HTMLDocument(继承自Document类型)的一个实例,表示整个HTML页面。而且,document对象是window对象的一个属性,因此可以将其作为全局对象来访问。Element类型
Element类型就要算是Web编程中最常用的类型了。Element类型用于表现XML或HTML元素,提供了对元素标签名、子节点及特性的访问。Text类型
文本节点由Text类型表示,包含的是可以照字面解释的纯文本内容。纯文本中可以包含转义后的HTML字符,但不能包含HTML代码。
使用示例
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> <link rel="stylesheet" href="001.css"></head><body> <h1>what to buy</h1> <p title="a gentle reminder">don't forget to buy this stuff.</p> <ul id="purchases"> <li>a tin of beans</li> <li class="sale">cheese</li> <li class="sale important">Milk</li> </ul> <div id="testDiv"> <p id="remove">我是要被删除的节点</p> </div> <a ="remove()">删除节点</a> <script src="001.js"></script></body></html>
// 根据id获取元素var html = document.getElementById("purchases");// 根据元素类型获取元素 接受一个参数,标签名(div,p..) 返回数组var li = document.getElementsByTagName("li");// 通过class类名访问元素 返回一个具有相同类名的元素数组var className = document.getElementsByClassName("sale");/**
* 使用getElementsByClassName这个方法还可以查找那些带有多个类名的元素,只要在
* 字符串参数中用空格分隔类名即可
*/var classA = document.getElementsByClassName("sale important");/**
* 想知道id为purchases的元素中有多少个包含sale类的元素
*
*/var shopping = document.getElementById("purchases");var sales = shopping.getElementsByClassName("sale");/**
* 总结:
* 1、一份文档就是一颗节点数
* 2、节点分为不同的类型:元素节点(<body>、<p>)、属性节点(几乎所有元素都有一个title属性)和文本节点等。
* 3、每个节点都是一个对象
*
*/// 获取和设置属性/** getAttribute是一个函数,它只有一个参数(查询的属性名字)
*
* getAttribute不属于document对象,所以只能通过元素节点调用
*
*/var paras = document.getElementsByTagName("p");var title = paras[0].getAttribute("title");/**
* setAttribute
* 允许我们对属性节点作出修改,与getAttribute一样,只能用于元素节点
* object.setAttribute(arrtribute,value)
*/shopping.setAttribute("title", "hello word");var title1 = shopping.getAttribute("title");/**
* childNodes
* 用来获取任何一个元素的子元素,它是一个包含这个元素全部子元素的数组
* element.childNodes
*
* 无论何时何地,只要需要访问childNodes数组的第一个元素,都可以写成firstChild
* firstChild
* lastChild
*//**
* nodeType 属性共有12种可取的值。
* node.nodeType
*
* 元素节点的nodeType是1
* 属性节点的nodeType是2
* 文本节点的nodeType是3
*
*//**
* nodeValue
* 改变文本节点的值
* node.nodeValue
*//**
* createElement 创建元素节点
* document.createElement(nodeName)
*
* 创建一个p元素
* document.createElement("p")
*/var para = document.createElement("p");/**
* appendChild
* 插入文档节点
* parent.appendChild(child);
*/var testDiv = document.getElementById("testDiv");
testDiv.appendChild(para)/**
* createTextNode 创建文本节点
* document.createTextNode(text);
*/var txt = document.createTextNode("hello word");
para.appendChild(txt);/**
* removeChild 删除节点
*
* node.removeChild(node)
*
* 返回值 被删除的节点
*
*/function remove() { var remove = document.getElementById("remove");
testDiv.removeChild(remove);
}/**
* querySelector()方法
* querySelector()方法接收一个CSS选择符,返回与该模式匹配的第一个元素,如果没有找到匹配的元素,返回null。
*/console.log(document.querySelector(".sale"))
console.log(document.querySelector("#testDiv"))
console.log(document.querySelector("#sale")) // null/**
* querySelectorAll()方法接收的参数与querySelector()方法一样,
* 都是一个CSS选择符,但返回的是所有匹配的元素而不仅仅是一个元素。这个方法返回的是一个NodeList的实例。
*/console.log(document.querySelectorAll(".sale"));GitHub:JavaScript-Demo
参考:
JavaScript高级程序设计
JavaScript.DOM编程艺术(第2版)
作者:周希孟
链接:https://www.jianshu.com/p/909060471d3c




