
在 Elasticsearch 中处理字符串类型的数据时,如果我们想把整个字符串作为一个完整的 term 存储,我们通常会将其类型 type 设定为 keyword。但有时这种设定又会给我们带来麻烦,比如同一个数据再写入时由于没有做好清洗,导致大小写不一致,比如 apple、Apple两个实际都是 apple,但当我们去搜索 apple时却无法返回 Apple的文档。要解决这个问题,就需要 Normalizer出场了。废话不多说,直接上手看!
1. 上手
我们先来重现一下开篇的问题
PUT test_normalizer{
"mappings": {
"doc":{
"properties": {
"type":{
"type":"keyword"
}
}
}
}}PUT test_normalizer/doc/1{
"type":"apple"}PUT test_normalizer/doc/2{
"type":"Apple"}# 查询一 GET test_normalizer/_search{
"query": {
"match":{
"type":"apple"
}
}}# 查询二GET test_normalizer/_search{
"query": {
"match":{
"type":"aPple"
}
}}大家执行后会发现 查询一返回了文档1,而 查询二没有文档返回,原因如下图所示:
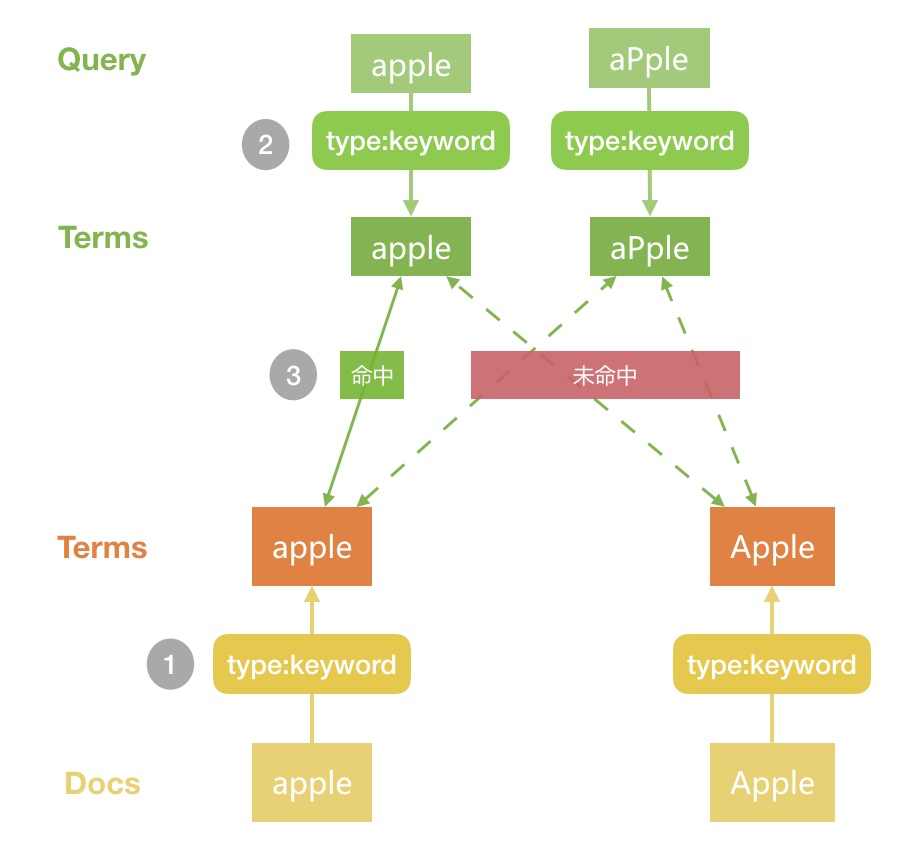
Docs写入Elasticsearch时由于type是keyword,分词结果为原始字符串查询 Query 时分词默认是采用和字段写时相同的配置,因此这里也是
keyword,因此分词结果也是原始字符两边的分词进行匹对,便得出了我们上面的结果
2. Normalizer
normalizer是 keyword的一个属性,可以对 keyword生成的单一 Term再做进一步的处理,比如 lowercase,即做小写变换。使用方法和自定义分词器有些类似,需要自定义,如下所示:
DELETE test_normalizer# 自定义 normalizer
PUT test_normalizer{
"settings": {
"analysis": {
"normalizer": {
"lowercase": {
"type": "custom",
"filter": [
"lowercase"
]
}
}
}
},
"mappings": {
"doc": {
"properties": {
"type": {
"type": "keyword"
},
"type_normalizer": {
"type": "keyword",
"normalizer": "lowercase"
}
}
}
}}PUT test_normalizer/doc/1{
"type": "apple",
"type_normalizer": "apple"}PUT test_normalizer/doc/2{
"type": "Apple",
"type_normalizer": "Apple"}# 查询三GET test_normalizer/_search{
"query": {
"term":{
"type":"aPple"
}
}}# 查询四GET test_normalizer/_search{
"query": {
"term":{
"type_normalizer":"aPple"
}
}}我们第一步是自定义了名为 lowercase的 normalizer,其中filter 类似自定义分词器中的 filter ,但是可用的种类很少,详情大家可以查看官方文档。然后通过 normalizer属性设定到字段type_normalizer中,然后插入相同的2条文档。执行发现,查询三无结果返回,查询四返回2条文档。
问题解决了!我们来看下是如何解决的
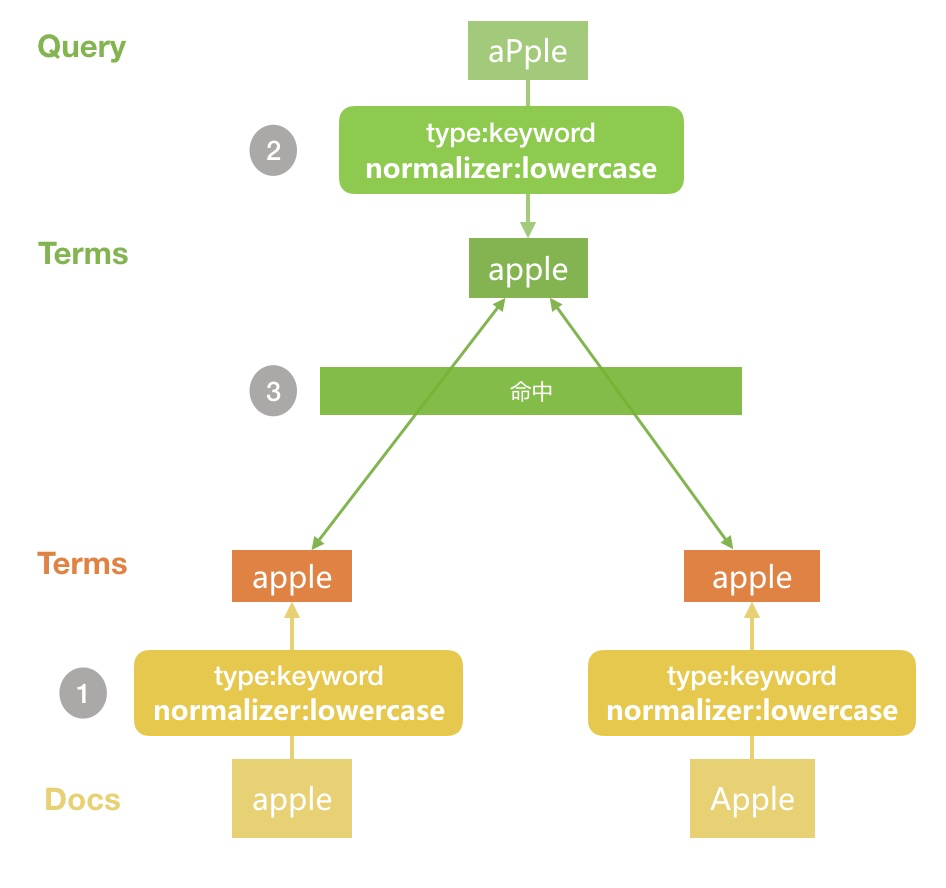
文档写入时由于加入了
normalizer,所有的term都会被做小写处理查询时搜索词同样采用有
normalizer的配置,因此处理后的term也是小写的两边分词匹对,就得到了我们上面的结果
3. 总结
本文通过一个实例来给大家讲解了 Normalizer的实际使用场景,希望对大家有所帮助!
欢迎关注课程《Elastic Stack从入门到实践》








热门评论
-

慕盖茨30697402018-08-29 1
查看全部评论如何将大数据量写入es?