
本文主要基于论文
Vinyals O, Toshev A, Bengio S, et al. Show and tell: A neural image caption generator[C]// Computer Vision and Pattern Recognition. IEEE, 2015:3156-3164.
温馨提示:要看懂本文,必须先熟悉CNN、RNN和单词嵌入模型等知识。
简单来说,就是输入一张图片,让机器给出图片信息的描述。
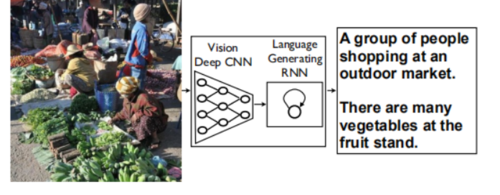
由于卷积神经网络在图片识别上表现很好,循环神经网络在自然语言处理领域表现突出,所以我们将两者结合起来,得到一个能用自然语言描述图片内容的模型。
模型
统计机器翻译的最新进展表明,给定一个强大的序列模型,通过以“端到端”的形式(包含训练和推断过程)给出输入句子的情况下,直接最大化正确翻译的概率,可以实现最先进的结果。这些模型利用递归神经网络将可变长度的输入,编码为固定维度向量,并使用该表示将其“解码”为期望的输出句子。同理,我们输入一张图片(而不是句子),采用同样的原则,输出图片的描述,这就是我们的目的。
因此,我们建议通过使用以下公式,直接最大化给定图像的正确描述的概率:
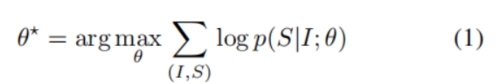
其中θ是模型的参数,I代表一张图片,S是对该图片正确的描述,然后对概率p取对数。因为,S可以代表任意一个句子,长度不定。所以,经常使用链规则来模拟S0......SN的联合分布,其中N是这个特定例子的长度:
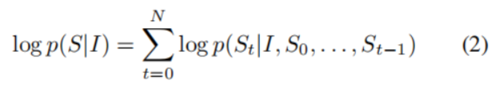
在概率论中,链规则(也称为通用乘积规则)允许仅使用条件概率来计算一组随机变量的联合分布的任何成员。该规则在贝叶斯网络的研究中是有用的,贝叶斯网络根据条件概率描述概率分布。
考虑随机变量的索引集合A1......AN, 为了找到联合分布的值,我们可以应用条件概率的定义来获得:

在上式中,为方便起见,我们放弃了对θ的依赖。在训练阶段,(S, I)是成对出现的,我们在整个训练集上使用随机梯度下降,来使(2)式中的对数概率之和最优化。
很自然的,我们使用循环神经网络(RNN)对p(St | I, S0......St-1)进行建模,其中我们在t-1(包括t-1)之前的可变数量的单词,是由固定长度的隐藏状态或“记忆”ht表示的。这个记忆单元在看到一个新的输入xt之后,通过一个非线性函 f 数来更新:
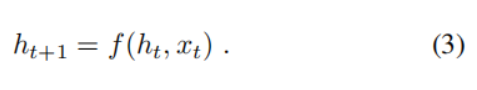
为了使上述RNN更具体,需要做出两个关键的设计:函数 f 的形式到底是什么?以及图片和词汇是如何作为xt输入的?对于 f,我们使用长短期记忆(LSTM)网络,其在序列任务(例如翻译)上表现出很先进的性能,该模型将在下一节中介绍。
对于图像的表示,我们使用卷积神经网络(CNN)。它已被广泛用于图像处理任务,并且目前是用于物体识别和检测的最先进技术。我们对CNN使用了一种新颖的批量标准化方法,此外,它们已被证明可以通过转移学习来推广到其他任务,例如场景分类。单词用嵌入模型表示。
基于LSTM的句子生成器
上式(3)中 f 的选择取决于其处理消失和爆炸梯度的能力,这是设计和训练RNN的最常见挑战。为了应对这一挑战,人们引入了一种特殊形式的循环网络,称为LSTM,并成功应用于翻译和序列生成。
LSTM模型的核心是一个存储器单元c,如果观察到有什么输入,它就编码知识(参见下图)。
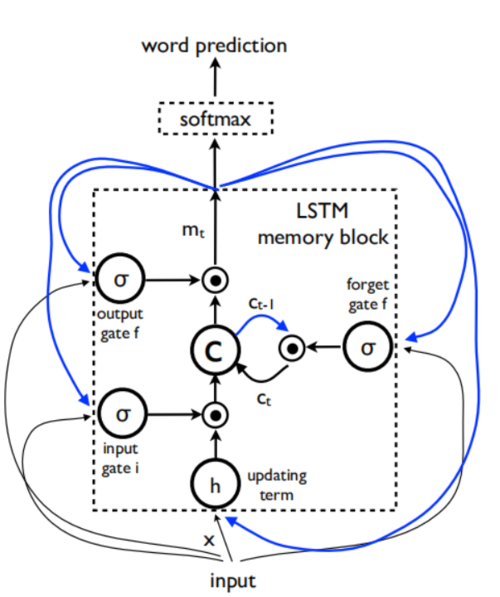
LSTM:存储器块包含由三个门控制的单元c。在蓝色标示中我们显示了循环连接 - 时间t-1的输出m在时间t通过三个门反馈到存储器;
单元的行为由“门”控制 - 这些层(门)是乘法运算的,因此如果门为1,则可以保持门控层的值,如果门为0则可以保持0。特别地,使用三个门,用来控制是否忘记当前单元值(忘记门f),是否应该读取其输入(输入门i)以及是否输出新单元值(输出门o)。门和单元的更新和输出的定义如下:
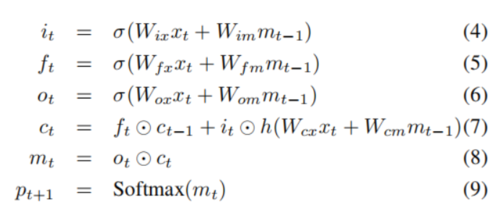
其中(圆圈中间一点)表示和门值的乘积,并且各种W矩阵是训练的参数。这样的乘法门使得可以稳健地训练LSTM,因为这些门很好地处理梯度爆炸和消失的问题。非线性处理函数是S形σ(·)和双曲正切h(·)。最后一个等式mt是用于输入到Softmax函数的,它将在所有单词上产生概率分布pt。
训练模型
我们训练一个LSTM模型,当它看到图片和由p(St | I, S0......St-1)预定义的所有单词之后,预测句子中的每个单词。为此,以展开形式考虑LSTM是有益的 - 为图像和每个句子中的词创建LSTM存储器的副本,使得所有LSTM共享相同的参数。LSTM在t - 1时刻的输出mt-1, 在时间 t 输入到LSTM(参见下图3)。
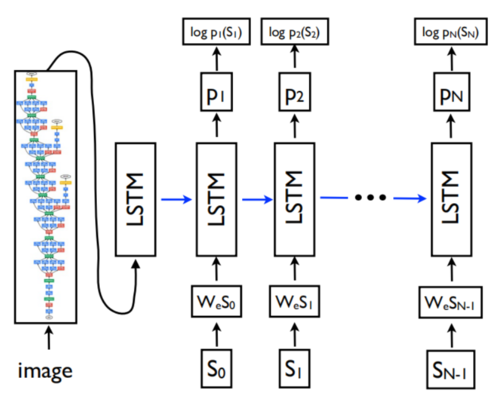
图3,LSTM模型与CNN图像嵌入器和词嵌入相结合。
所有重复连接都转换为展开版本中的前馈连接。说的更详细点,如果用 I 表示输入的图片,用S = (S0,......,SN)表示对图片的真实描述,则展开过程如下:
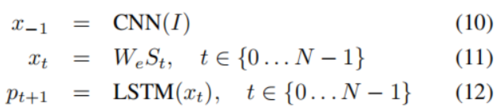
其中我们将每个单词表示为one-hot矢量St,St来自于一个足够描述图片的字典,其维数等于字典的大小。注意,我们用S0表示一个特殊的起始单词,用SN表示一个特殊结束的单词,它表示句子的开头和结尾。特别是LSTM通过发出停止字,通知已生成完整的句子。图像和单词都映射到同一个空间,图像通过使用视觉CNN,单词通过使用单词嵌入We。图像 I 仅仅在 t = -1 时输入一次,告诉LSTM图像的内容。凭我们的经验,如果每一步都将图像作为额外的输入,效果是比较差的,因为网络会利用图像中的噪声,更容易产生过拟合。
我们的损失是每个步骤中正确单词的负对数概率的总和,如下:
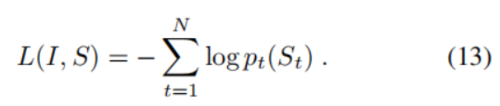
补充
BLEU
BLEU的全名为:bilingual evaluation understudy,即:双语互译质量评估辅助工具。它是用来评估机器翻译质量的工具。
BLEU算法实际上在做的事:判断两个句子的相似程度。我想知道一个句子翻译前后的表示是否意思一致,显然没法直接比较,那我就拿这个句子的标准人工翻译与我的机器翻译的结果作比较,如果它们是很相似的,说明我的翻译很成功。因此,BLUE去做判断:一句机器翻译的话与其相对应的几个参考翻译作比较,算出一个综合分数。这个分数越高说明机器翻译得越好。(注:BLEU算法是句子之间的比较,不是词组,也不是段落)
BLEU实质是对两个句子的共现词频率计算,但计算过程中使用好些技巧,追求计算的数值可以衡量这两句话的一致程度。 BLEU容易陷入常用词和短译句的陷阱中,而给出较高的评分值。
参考资料:
https://blog.csdn.net/qq_31584157/article/details/77709454
作者:话巴
链接:https://www.jianshu.com/p/ee222ac960e6





