
上一篇文章讲了神经网络的参数初试化,可以看到不同的初始化方法对我们的学习效果有很大影响。(参见:【DL笔记】神经网络参数初始化的学问)
本文继续讨论如何进一步优化我们的梯度下降算法,使得我们的学习更快,学习效果更佳。
首先,我们惯用的方法是“梯度下降法”,称为Gradient Decent,就是把所有的训练样本丢进去训练一次之后,把W和b更新一次,然后重复这个过程,具体重复多少次就看我们的“迭代次数”是多少。
【为了下面叙述的方便,我们称“把所有训练样本过一遍”为一个epoch,另外 gradient decent也就是梯度下降我们就简称为GD。】
我们传统的GD,也可以称为Batch GD,这个batch就是指一整批,就是指我们所有样本。
今天主要介绍的有如下方法,均是对传统batch gradient decent的改进:
Mini-batch GD(小批量梯度下降法)
GD with Momentum(动量法)
Adam算法(Momentum与RMSprop算法结合)
一、Mini-batch GD
mini-batch是相对于batch来说的,后者我们前面说过,是走完一个epoch才把参数更新一次,这样其实很慢。
样本数量不多还好,但是样本多了就会明显耗费大量时间,比如5百万样本,这在深度学习里面是很平常的事情,但是使用传统的方法,即batch GD,意味着我们需要把5,000,000个样本跑一遍才能更新一次W和b。
mini-batch就是为了解决这个问题的,我们可以把5百万的样本分成一块一块的,比如1000个样本一块,称为一个mini-batch,这样我们就有5000个mini-batch。我们训练的时候,跑完一个mini-batch就把W和b更新一次,这样的的话,在一个epoch中,我们就已经把参数更新了5000次了!虽然每一步没有batch GD的一步走的准,但是我5000步加起来,怎么样也比你走一步的效果好的多,因此可以加快训练速度,更快到达最值点。
这就是mini-batch GD方法。
对于不同的mini-batch的大小(size),也有不一样的效果:
size=样本数 —> Batch GD
size=1 —> Stochastic GD(随机梯度下降)
有人可能会问,那size=1的时候,也就是来一个样本就更新一次,岂不是会更快?
不是的,它会有两个问题:
震动太剧烈,误差会灰常大,可能根本无法到达最低点
每次只计算一个样本,就失去了我们前面提到的“Vectorization(矢量化)”的优势,因此计算效率反而不高
因此,我们通常取一个中间的值,这样,既利用了Vectorization来加速计算,又可以在一个epoch中多次更新,速度就可以最快。
有意思的是,据吴恩达说,mini-batch size 通常取2的指数,主要是16,32,64,128,256,512,1024这几个值,因为计算机是二进制,这样的数字计算起来效率会更高一些。
口说无凭,现在我做个实验验证一下是不是mini-batch 更好:
实验条件:
三层神经网络,learning-rate=0.0007,batch size=300,mini-batch size=64,迭代次数=40000
数据集形状如下:

数据集
猜想:
①mini-batch GD效果要比batch GD更好
②mini-batch GD的cost曲线会比batch波动更大,但是最终cost却更低
实验代码和过程就不放了,直接看我们运行的结果:
batch GD:


耗时105s,准确率只有0.76,看图明显就知道还没训练好。
再看mini-batch GD:

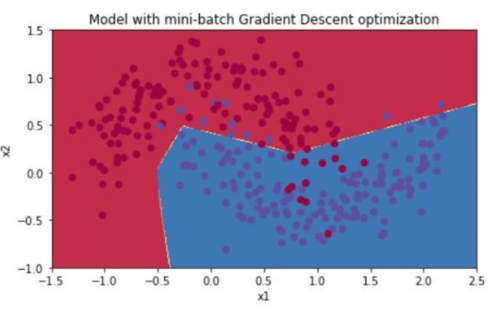
哇塞,效果不错!准确率提高到了91.7%,而且从cost曲线上看,确实如我所料有很大的波动,但是最终的cost显著低于batch GD,因此学习的模型就更好。
出乎我意料的是,时间居然缩短了一半以上!一开始我估计时间应该差不多,因为我们迭代的40000次相当于40000个epoch,我前面只是说一个epoch中mini-batch更新的次数更多,没想到居然也更快(因为我觉得一个epoch中的操作变多了,可能会变慢一点)。
想了想,觉得应该是这样:因为mini-batch在一个epoch中走的步子多,因此可以迅速地找到“最佳下坡路”,找到了之后,就跟坐滑滑梯一样,越溜越快,因此比batch GD更快。
二、Momentum 动量法
上面的mini-batch GD给了我们一些惊喜了,但是似乎还可以更好,毕竟还有不少点都分类错误。
主要的原因就是因为,使用mini-batch之后,稳定性降低了,在梯度下降的时候会有较为剧烈的振动,这样可能导致在最低点附近瞎晃悠,因此效果会受影响。
动量法就是解决mini-batch的这个问题的,它让梯度下降不那么抖动。
看看Momentum的参数更新过程:
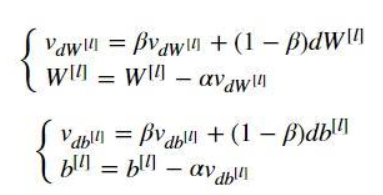
如果你熟悉神经网络梯度下降的过程,就知道,我们一般的梯度下降的更新过程(以W为例)是:W = W -αdW。
动量法相当于多了一个V_dW,它考虑了前面若干个dW,(实际上,V_dW约等于前1/(1-β)个dW的平均值,数学上称为“指数加权平均”)这样,dW的方向就会受到前面若干个dW的冲击,于是整体就变得更平缓。
可能画个示意图才能更好地说明吧:

mini-batch是上下起伏不定的箭头,但是把若干个的方向平均一下,就变得平缓多了,相当于抵消掉了很多的方向相反的误差。
我们也在做实验验证一下,实验条件跟上面一样,我们在mini-batch size=64的基础上,使用Momentum方法来更新参数,得到的效果如下:

这个超参数β调了我半天,最开始0.9,然后0.95,再0.99,再0.999,终于有了上面的这么一点点的提升,准确率到了92%。可见momentum有一些效果,但是此处还不太明显。
三、Adam算法
这个方法,对momentum再进一步改进,结合了RMSprop算法(是另一种减小梯度下降振动的方法),更新过程如下:

不仅有了我们刚刚的V_dW, 还有一个S_dW(就把它理解为跟V_dW的原理类似就行了),然后,再对这两个玩意儿都进行了一个修正(corrected),最后参数更新是综合了这二者,结果效果就出奇的好:

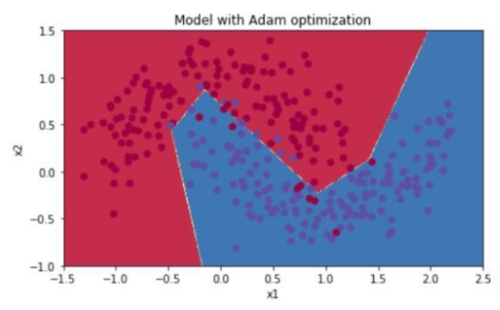
准确率有了明显提升,达到94%,拟合的形状明显是那么一回事了。
对于Momentum的效果不那么明显的现在,吴恩达的解释是在learning-rate太小以及数据集比较简单的情况下,momentum发挥不了太大的作用,因此本实验中我们看不出惊人的效果。但在其他场景下也许就有很好的改善了。
当然,既然有了Adam算法,我们自然会使用Adam这个最佳实践了。
总结一下:
Mini-batch GD比传统GD效果更好,训练更快
Momentum动量法可以减小Mini-batch带来的振动
梯度下降的最佳优化方法是Adam算法
Adam算法中的超参数β1和β2以及learning-rate也会显著影响模型,因此需要我们反复调试
作者:Stack_empty
链接:https://www.jianshu.com/p/ea708a06f87c





