
1.什么是注解
注解是java1.5引入的新特性,它是嵌入代码中的元数据信息,元数据是解释数据的数据。通俗的说,注解是解释代码的代码。这个定义强调了三点,
1.注解是代码
这意味着注解可以被程序读取并解析。它可以被编译器编译成class文件,也可以被JVM加载进内存在运行时进行解析。JDK中的"@Override"就是注解。它不仅解释了这是个重写方法,还能在被错误使用(被注解的方法没有重写父类方法)时让编译器给出错误提示。Spring中的“Controller”就是注解,它可以在运行时被JVM读取到并为被其修饰的类创建实例。2.注解起到的是描述和解释作用。这点和注释有点像。但注释面向的对象主要是开发者,且只能在源码阶段存在;注解面向的对象主要是程序,且可以再编译期和运行期存在。
3.注解需要关联特定的代码,如果不存在需要解释的代码,那么注解就毫无意义了。
2. 注解的结构以及如何在运行时读取注解
2.1 注解的组成
下面是一个自定义注解的例子:
@Retention(RetentionPolicy.RUNTIME)@Target(value = {ElementType.TYPE})public @interface ClassAnnotation { String name() default ""; boolean singleton() default false;
}注解由声明,属性,元注解三部分构成。
1.注解声明
由@interface声明ClassAnnotation为注解类型,注意比interface多了个@符号。2.注解的属性
上面定义了两个属性:String类型的name属性,默认值为空字符串;boolean类型的singleton属性,默认值为false.注意虽然后面带了括号,但并不是方法。如果注解内部只定义了一个属性,该属性名通常为value,且在使用的时候可以省略value=,直接写值。
注解的属性类型支持的类型有:所有基本类型,String,Class,enum,Anotation以及上述类型的数组类型。3.元注解
元注解是注解的注解。有点绕,只要知道它是注解,并且使用在注解上,可以对注解进行解释就行。上面使用了两个元注解@Retention和@Target。这是最常使用的元注解。关于它们有后面会进行详细说明。
2.2 注解的类层级结构
任何注解类型都默认继承自java.lang.annotation包下的Annotation接口,表明这是一个注解类型,这是编译器自动帮我们完成的。但是手动继承Annotation没有这个效果,即不会把它当成注解类型。甚至Annotation接口本身也并不意味着它是注解类型。很奇怪也很绕,然而很遗憾规则就是这么定义的。可以简单的理解为:我们可以也只可以通过@interface的方式来定义注解类型,这个注解类型默认会实现Annotation接口。来看看Annotation接口的结构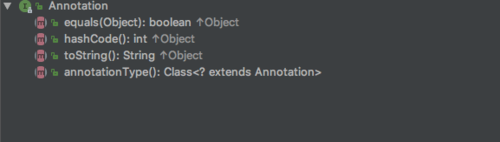
根据面向接口编程原则,在编写代码时可以用Annotation接口引用不同的注解类型,在运行时才通过接口的annotationType()方法获得具体的注解信息。
2.3 如何在运行时获得注解信息
注解通过设置可以一直保留到运行期,此时VM通过反射的方式读取注解信息。由上面的介绍可知,注解是解释代码的代码,它必须存在于特定的代码元素之上,可以是类,可以是方法,可以是字段等等。
为了更好的在运行时解析这些代码元素上的注解,java在反射包下为它们提供了一个抽象,如下图所示
里面定义了一些获取该元素上注解信息的方法。
而Class,Field,Method,Constructor等可以在运行时被反射获取的元素都实现了AnnotationElement接口,如下图所示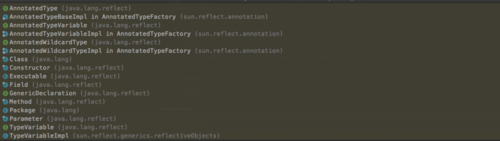
因此当我们在获得了包含注解的Clazz,Method,Field等对象后,可以直接通过AnnotationElement接口中的方法获得其上的注解信息。
3.几种元注解介绍
3.1 @Retention
@Documented@Retention(RetentionPolicy.RUNTIME)@Target(ElementType.ANNOTATION_TYPE)public @interface Retention { /**
* Returns the retention policy.
* @return the retention policy
*/
RetentionPolicy value();
}用来表示被其修饰的注解的生命周期,即该注解的信息会在什么级别被保留。Retention只有一个属性value,类型为RetentionPolicy,这是一个枚举值,可以由以下取值
SOURCE
源码有效:表示该注解(被@Retention注解的注解)仅在源码阶段存在,编译阶段就会被编译器丢弃。CLASS
编译期有效:注解信息会被编译进class文件中,但是不会被JVM加载。当注解未定义Retention值时,这是默认的级别。RUNTIME
运行期有效:注解信息会被编译进class文件中,且会被JVM加载并可在运行期被JVM以反射的方式读取。
3.2 @Target
@Documented@Retention(RetentionPolicy.RUNTIME)@Target(ElementType.ANNOTATION_TYPE)public @interface Target { /**
* Returns an array of the kinds of elements an annotation type
* can be applied to.
* @return an array of the kinds of elements an annotation type
* can be applied to
*/
ElementType[] value();
}用来表示被其修饰的注解可以用在什么地方。该注解只有一个属性值value,类型为ElementType数组,这意味着通常注解可以被用在多个不同的地方。来看看ElementType都有哪些值,分别代表什么意思。
TYPE
表示类,接口(包括注解类型),枚举类型FIELD
表示类成员METHOD
表示方法PARAMETER
表示方法参数CONSTRUCTOR
表示构造方法LOCAL_VARIABLE
表示局部变量ANNOTATION_TYPE
表示注解类型PACKAGE
表示包TYPE_PARAMETER
1.8新加,表示类型参数TYPE_USE
1.8新加,表示类型使用
可以看到ElementType枚举值相当多,几乎囊括了所有元素类型。这也意味着注解几乎可以用在所有地方。但最常见得还是用在类,成员变量和成员方法上。
3.3 @Documented
这是一个标记注解。用来表示被其修饰的注解在被使用时会被Javadoc工具文档化。
3.4 @Inherited
这也是一个标记注解。表示被其修饰的注解可被继承。通俗的解释:若注解A被元注解@Inherited修饰,则当注解A被用在父类上时,其子类也会自动继承这个注解A。来看下面这个演示的例子。
创建一个被@Inherited描述的自定义注解@InheritedAnnotation
@Retention(RetentionPolicy.RUNTIME)@Target(ElementType.TYPE)@Inheritedpublic @interface InheritedAnnotation {
}创建父类,并在类上标注@InheritedAnnotation注解
@InheritedAnnotationpublic class SuperClass {}子类继承父类并测试
class TestClass extends SuperClass{
public static void main(String[] args) { Annotation[] annotations = TestClass.class.getAnnotations(); for(Annotation annotation:annotations){ System.out.println(annotation);
}
}
}测试结果

可以看到子类虽然没有被@InheritedAnnotation注解,但是其继承的父类上有该注解,故而@InheritedAnnotation注解也作用在了子类上。
原理如下:当JVM要查询的注解是一个被@Inherited描述的注解,会不断递归的检查父类中是否存在该注解,如果存在,则会认为该类也被该注解修饰。
3.5 @Repeatable
@Documented@Retention(RetentionPolicy.RUNTIME)@Target(ElementType.ANNOTATION_TYPE)public @interface Repeatable { /**
* Indicates the <em>containing annotation type</em> for the
* repeatable annotation type.
* @return the containing annotation type
*/
Class<? extends Annotation> value();
}这是java8种引入的一个新的元注解,被其修饰的注解将能够被在同一个地方重复使用,这在原来是办不到的。注意每一个可重复使用的注解都必须有一个容纳这些可重复使用注解的容器注解。这个容器注解就是Repeatable的value属性值。
来看一个简单的例子
自定义可重复注解
@Retention(RetentionPolicy.RUNTIME)@Target(ElementType.TYPE)@Repeatable(RepeatableAnnotations.class)public @interface RepeatableAnnotation {
String name() default "";
}自定义可重复注解的容器注解
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)public @interface RepeatableAnnotations {
RepeatableAnnotation[] value();
}Repeatable(RepeatableAnnotations.class) 指定了@RepeatableAnnotation为可重复使用的注解,同时指定了该注解的容器注解为@RepeatableAnnotations。那我们该如何在运行时获得这些重复注解的信息?
运行时获取注解
@RepeatableAnnotation("first")
@RepeatableAnnotation("second")public class AnnotationTest { public static void main(String[] args) throws ClassNotFoundException, NoSuchFieldException { Class<?> clazz = Class.forName("com.takumiCX.AnnotationTest"); //当元素上有重复注解时,使用该方法会返回null
RepeatableAnnotation annotation1 = clazz.getAnnotation(RepeatableAnnotation.class); System.out.println(annotation1); //使用该方法获取元素上的重复注解
RepeatableAnnotation[] annotations = clazz.getAnnotationsByType(RepeatableAnnotation.class); for(Annotation annotation:annotations){ System.out.println(annotation);
}
}
}注意多个重复注解会被自动存放到与之关联的容器注解里。所以我们这里要获得所有@RepeatableAnnotation注解,不能使用getAnnotation方法,而应该使用getAnnotationByType方法。最后的结果如下
4.使用反射和注解完成简单的ORM功能
4.1 ORM原理简介
ORM是对象关系映射的意思。他建立起了以下映射关系:
类对应于表
对象对应于表中的记录
对象的属性对应于表的字段
有了这种映射关系,我们在编写代码时就可以通过操作对象来映射对数据库表的操作,比如添加记录,更新记录,删除记录等等。常见的Mybatis,Hibernate就是ORM框架。而实现ORM功能最常用的手段就是注解+反射。由注解维护这种映射关系,然后运行期通过反射技术解析注解,完成对应关系的转换,从而形成一句完整的sql去执行。
下面以建表为例,实现简单的ORM功能。
4.2 ORM实战
自定义表注解,完成类和表的映射。
/**
* 自定义表注解,完成类和表的映射
*/@Retention(RetentionPolicy.RUNTIME) //因为要使用到反射,故注解信息必须保留到运行时@Target(ElementType.TYPE)//只能用在类上public @interface MyTable { //表名
String value();
}自定义字段注解
/**
* 自定义字段注解,完成类属性和表字段的映射
*/@Retention(RetentionPolicy.RUNTIME)//要反射,故注解信息需要保留到运行期@Target(ElementType.FIELD)//只能用在类属性上public @interface MyColumn { //字段名
String value(); //字段类型,默认为字符串类型
String type() default "VARCHAR(30)";//字段类型,默认为VARCHAR类型
//类型为注解类型的字段约束,默认的约束为:非主键,非唯一字段,不能为null
Constraints constraint() default @Constraints;
}自定义字段约束注解
/**
* 约束注解:主键,是否为空,是否唯一等信息。
*/@Retention(RetentionPolicy.RUNTIME)//运行期@Target(ElementType.FIELD)//只能在类属性上使用public @interface Constraints { //字段是否为主键约束
boolean primaryKey() default false; //字段是否允许为null
boolean nullable() default false; //字段是否唯一
boolean unique() default false;
}带注解的实体类
/**
* 带注解的实体类,建立了对象和表的映射关系,可以再运行时被解析
*/@MyTable("t_user")
public class User { //主键,对应表字段id,类型为VARCHAR
@MyColumn(value = "id", constraint = @Constraints(primaryKey = true)) private String id; //对应表字段name,类型为类型为VARCHAR
@MyColumn(value = "name") private String name; //对应表字段age,类型为INT,且可为null
@MyColumn(value = "age", type = "INT", constraint = @Constraints(nullable = true)) private int age; //对应表字段phone_number,类型为VARCHAR,且有唯一约束
@MyColumn(value = "phone_number", constraint = @Constraints(unique = true)) private String phoneNumber;
}运行时注解解析器
/**
* 运行时注解解析器
*/public class TableGenerator { /**
* 运行时解析注解生成对应的建表语句
*
* @param clazz 与表对应的实体的Class对象
* @return
*/
public static String genSQL(Class clazz) { String table;//表名
List<String> columnSegments = new ArrayList<>(); //获取表注解
MyTable myTable = (MyTable) clazz.getAnnotation(MyTable.class); if (myTable == null) { throw new IllegalArgumentException("表注解不能为空!");
} //获取表名
table = myTable.value(); //获取所有字段
Field[] fields = clazz.getDeclaredFields(); for (Field field : fields) {
MyColumn column = field.getAnnotation(MyColumn.class); if (column == null) { continue;//为null说明该字段不为映射字段,也就是没有加上字段注解
}
StringBuilder columnSegement = new StringBuilder();//字段分片,eg:"id varchar(50) primary key"
String columnType = column.type().toUpperCase();//字段类型
String columnName = column.value().toUpperCase();//字段名
columnSegement.append(columnName).append(" ").append(columnType).append(" ");
Constraints constraint = column.constraint(); boolean primaryKey = constraint.primaryKey(); boolean nullable = constraint.nullable(); boolean unique = constraint.unique(); if (primaryKey) { //主键唯一且不为空
columnSegement.append("PRIMARY KEY ");
} else if (!nullable) { //字段不为null
columnSegement.append("NOT NULL ");
} if (unique) { //有唯一键
columnSegement.append("UNIQUE ");
}
columnSegments.add(columnSegement.toString());
} if (columnSegments.size() < 1) { //没有映射任何表字段,抛出异常
throw new IllegalArgumentException("没有映射任何表字段!");
}
StringJoiner joiner = new StringJoiner(",", "(", ")"); for (String segement : columnSegments) {
joiner.add(segement);
} //生成SQL语句
return String.format("CREATE TABLE %s", table) + joiner.toString();
}
}通过该解析器的genSQL方法在运行时生成建表SQL,通过传入的Class参数在运行时解析类和属性上的注解,分别得到表名,字段名,字段类型,约束条件等信息,然后拼装成SQL。由于只是为了做演示,对SQL语法的支持比较弱,只允许字段为int和varchar类型。且解析语法时也没有考虑一些边界情况。但是通过这段代码演示可以知道ORM框架在解析注解时的大概工作和流程是怎么样的。
测试
public class TableGeneratorTest { public static void main(String[] args) {
String sql = TableGenerator.genSQL(User.class);
System.out.println(sql);
}
}最后得到的建表语句如下
CREATE TABLE t_user(ID VARCHAR(30) PRIMARY KEY ,NAME VARCHAR(30) NOT NULL ,AGE INT ,PHONE_NUMBER VARCHAR(30) NOT NULL UNIQUE )
最后我们验证下生成的建表SQL语法是否有问题,在mysql客户端上执行该sql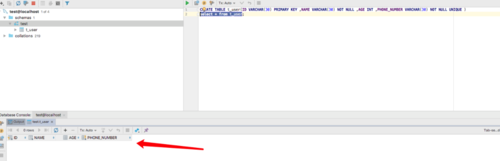
如上图所示,执行成功,说明我们的建表语句是正确的。
原文出处:http://www.cnblogs.com/takumicx/p/9356963.html





