
大家在使用 AWS 过程中总会遇到一些问题。在此以 Q&A 形式,总结一些常见的架构和故障排查问题,希望有所帮助。如果有中国(北京和宁夏区域)特有的问题,会特别注明。
S3 |
Q:如何提高 S3 性能?
A:S3 index 和实际数据分开存放。默认一个 bucket 所有 object 都位于同一个分区。如果 object 数量太多,而请求速率又不高时,S3 会根据 key name 自动分区。但是,如果请求速率太高,会耗尽 S3 分区的 IO,触发限制,可能会返回503 Slow Down 错误。
尽量利用 hash 或者倒序,使 S3 前缀随机化。如果读写请求过高,可以向 AWS 提交 S3 分区请求,或者采用指数退避(exponential backoff)算法,增加请求的重试等待时间。尽管如此,仍然需要遵循 S3 key name 随机化原则。可以对于某个目录下的已经随机化的 object 进行分区。
例如:S3 bucket 的 log 目录下的.log 对象前缀已经做了随机化。
S3://bucket/log/A0B1.log
S3://bucket/log/C2D3.log
S3://bucket/log/E4F5.log
在提交请求时,除了请求速率,还需要填写 pattern,注明 log/ 目录下是如何进行随机化的。后台就可以在 S3://bucket/log/ 后面进行分区。
S3 不限制带宽。但是,也不要对 S3 进行压力测试。实际的传输速率和客户端到 S3 的网络有关。如果客户端请求很多,可以使用 CDN 进行加速。
Q: 有很多小文件,如何有效上传到 S3?
A: 如果可能,尽量先压缩成大文件再上传。一方面,减少大量小文件上传时,TCP 连接建立和断开的开销。另外一方面,S3 虽然上传流量不收费,但是请求仍然收费。
Q: 需要在本地到 S3 之间每日同步文件,现有文件数量非常多(几百万),如何提高效率?
A: aws s3 sync 命令可以同步本地到 S3 的文件,只同步变化的部分。但是,sync 需要先列出 LIST S3,以进行比较。如果文件数量非常巨大,LIST 所有对象,非常花费时间,甚至可能卡住。
解决办法:只同步变化的目录。例如,按照日期目录来同步。
aws s3 sync /data/2018/03/13 s3://bucket/data/2018/03/13
如果每天变化的数据分布在不同目录,可以把这些变化记录在 Dynamodb,在同步时,只同步变化的部分。
Q: S3 是否支持断点续传?
A: 断点续传的实现,在于根据 content-length 划分成多个 range,没有传完的,可以保留,下次可以继续传输。
S3 支持 multi-part 分段传输。分三个步骤:
Initiate Multipart Upload:初始化任务。
Parts Upload:把文件分成多块,每个块都有一样的 upload ID,和不同的 part number。不同的分块分别传输,与顺序无关。
Complete Multipart Upload:所有分块完成后,把分块合并成 S3 对象。一般的程序,例如 AWS CLI,如果有部分没有完成,并且重试后超时,那么会调用 Abort Multipart Upload,所有已经上传到 S3 的部分全部删除,任务终止。
S3 没有提供直接断点续传 API,可以自己在程序加个逻辑来实现。如果在第二阶段有部分一直没有传完,就不会调用第三阶段的 Complete/Abort。这样,已经传输完成的部分会一直放在 S3,直到 Complete/Abort。
Q: 应用程序在下载S3文件时,会判断MD5以防止文件传输中被篡改,但是大文件总是出错。
A: S3 大文件传输使用 multi part 分段。对于每一段,分别计算 MD5。最后在任务完成时,把所有分段的 MD5,再进行 MD5 计算,得到 S3 Etag 值。
应用程序只对比了某一段的 MD5 值,与 S3 Etag 不一致,因此出现错误。
Q:在移动应用上传到S3的场景下,S3 Pre-singed URL和Cognito方式,有何区别?
A: 移动客户端在上传时,需要在服务器生成 Pre-signed URL,返回客户端。客户端以此临时 URL,无需 credentia l即可上传。实际上,上传时,使用的是服务器生成 URL 时的 IAM 用户权限,相当于以此 IAM 用户来上传。此方式的限制在于,pre-signed URL 不知道整个上传对象的大小,因此不能使用 S3 multi-part,对于大文件的传输效率比较低。
在 Cognito 的环境下,移动客户端上传时,先要进行自定义或者联合认证。验证通过后,与 Cognito 交换 token。之后客户端以 Cognito token 向 STS 获取临时 credentia 以访问 S3。以此方式上传,客户端可以使用正常的 API,包括multi-part。
中国区 Cognito 目前还没有用户池功能,不支持 Google, Facebook 认证。可以自行进行用户管理,比如 LDAP/AD。对于不大的文件上传,pre-signed URL 一般可以满足需求。
Q:S3最终一致性如何?
A: 对于新创建的 S3 object,采用 read-after-write 一致性,上传完成后立刻可以访问。
对于覆盖或者 HEAD/GET 操作过的 object,采用最终一致性。如果覆盖后立刻访问,可能会是新内容,也可能是之前的内容,但是最终会是新的内容。
Q: 我帐号下 S3 的 ELB 访问日志,bucket 策略已经授权别的帐号可以方案,为什么别的帐号还是不能访问?
A: ELB 访问日志是 AWS 系统帐号经过授权,向您的帐号下 S3 上传的对象。日志文件的所有者是 AWS 帐号,在上传时把您的帐号添加到 Object ACL,因此您可以访问。但是,文件所有者并非您的帐号,别的帐号没有添加到 Object ACL,即使 bucket policy 允许别的帐号访问,仍然不能访问。
解决方法:在 object ACL 加入别的帐号的 canonical id,ID 可以通过 AWS CLI 命令行获得:
Json
aws s3api list-buckets{
"Owner": {
"ID": "633eb40d3277ec23db4bc5a394dc363f48e41c85358c5618f0de3df382855242"},
注意:对于上传到别的帐号 bucket 的 object,如果没有授权 object ACL 给 bucket 所有者,bucket 所有者也不能下载或者修改 ACL,只能删除。
Q:设置生命周期为何不生效?
A: S3 生命周期设置后,于 UTC 时间第二天的0点开始工作。所有对象,按照创建时间,或者变成 non-current version 的时间,如果满足条件,就会被转移到 Glacier/Standard IA 类型,或者删除。在对象太多的情况下,此工作可能需要更长时间。
如果一直不生效,可以检查生命周期规则是否带了空格,或者通过 s3api head-object 查看是否在进行转换。
如果是转换成 Standard IA 类型, S3 对象大小需要在 128KB 以下。
Q: 浏览器访问 S3 对象 URL 链接,出现 401 Unauthorized 错误。(中国)
A: 请进行 ICP 备案,打开帐号的 80/443/8080 端口。
Q: 通过浏览在 AWS 控制台下载 S3 对象,出现 Unexpected IP 错误。(中国)
A: 控制台下载 S3 对象,会生成一个特殊的 pre-signed URL,带有 x-amz-expect-ip 参数,限制了能使用此 URL 的 IP。返回客户端以此 URL 上传时,如果 IP 发生变化(包括公司出口 IP 变化,使用代理,等等),就会出现 Unexpected IP 错误。
Q: 如何同步 Global 海外到中国 S3?(中国)
A: AWS Global 和中国使用不同的帐号,不能直接通过 S3 Cross-region replication 进行同步。
如果要自动同步,可以考虑 S3 Notification + Lambda 方式。当 S3 对象有变化时,通知触发 Lambda,自动调用函数,复制对象。需要注意,此方法受到中国到海外Internet 网络状况影响,对于大文件支持不够好。
另外一个方法,S3 Notification + SQS。S3 通知发送到 SQS 消息队列,EC2 运行程序,定期从 SQS 获取消息。如果有更新,海外 EC2 下载海外S3对象,复制到中国区 EC2,再从中国区 EC2 上传到中国 S3。此方式虽然比较复杂,但是可以充分利用 AWS 跨区域 EC2 的优化网络,并且可以使用 S3 multi-part 特性,更适合大文件的传输。
EC2 |
Q: EC2 实例状态检查失败,停止一直卡住。
A: EC2 实例状态,如果是 0/2,说明底层硬件出现故障。可以停止 (stop) 实例,然后启动 (start),虚拟机迁移到别的物理主机。如果停止操作时一直卡住,可以再次强制停止。如果仍然不行,请开启技术支持案例。对于 C3, C4, C5, M3, M4, M5, R3, R4, T2, or X1 类型实例,建议开启 EC2 自动恢复功能。当底层硬件出现故障时,可以自行恢复。
请注意:实例存储 (instance store) 的数据会丢失。重要数据尽量使用 EBS,并且进行快照备份。
如果状态检查是1/2,说明底层硬件正常,但是操作系统出现故障,需要结合日志信息自行排查。
Q: EC2 实例带宽是多少?
A: EC2 实例根据类型不同,网络性能分低、中、高等。由于客户端到 AWS 网络状况不同,需要测试来获得实际数值,例如 iperf 工具。有些类型,例如 C4,可以达到 10Gb 的网络带宽,这是对于 EC2 实例内部之间而言,到 Internet 的网络性能,仍然需要实际测试。
有些类型支持增强型联网,可以提高网络性能。此功能可能需要在操作系统安装驱动并启用模块。
Q: 访问位于 EC2 的网站,速度很慢。
A: 访问速度,在整个过程中的服务器、网络、客户端都会受到影响。
服务器层面,CPU / 内存 / IO 资源的使用情况,操作系统的内核参数,应用程序的优化,都会影响整个用户体验。通过 Cloudwatch 监控 CPU / IO/ 网络情况,在操作系统上查看内存和进程,检查操作系统和应用日志,必要时用 strace 等工具追踪调用。
网络层面,从客户端到服务器,中间要经过多个路由器,运营商可能会出现一些网络拥塞或者路由问题。以双向 traceroute/mtr 工具,检查哪些网络路由可能存在问题。请确认网络问题是否具有普遍性,检查其他地区用户是否也存在同样问题。如果是运营商网络拥塞,或者客户端接入了一些复杂网络,这已经超出了 AWS 所能解决的范围。
客户端层面,自身的 CPU / 内存等资源情况需要检查。对于请求本身,一般来说,带数据库复杂查询的动态 HTTP 请求,或者需要下载很多图片 / 视频 / css / js 的页面,要比简单的 HTML 页面要快。可以换一个别的客户端,以同样的请求,再进行测试。
Q: EC2 被停止或终止了,但不是自己操作的。
A: AWS 不会关闭用户 EC2 实例,哪怕是底层硬件故障。请检查是否有 Autoscaling / Cloudformation 等其他服务触发了操作。打开 Cloudtrail 可以看到 API 调用记录。
Q: EC2 是否支持广播?
A: EC2 不支持广播和组播,只支持单播。一些应用中,例如 LVS keepalived,需要特别设置为单播模式。
Q: EC2 设置安全组,允许另外一个安全组访问,但是不通。
A: 安全组里允许另外一个安全组访问,在连接时,需要使用私有 IP。如果使用公有 IP,安全组里要设置为公有 IP CIDR。
另外,EC2 内部访问尽量使用私有 IP,这样可以减少网络传输成本。
Q: 创建 CentOS 实例,根盘使用 10GB EBS,但是 df 命令只能看到 8GB。
A: 默认 CentOS 根盘分区表是 8GB,需要自行更改分区表,并扩展文件系统。
Q: 创建实例时,挂了 3TB 的根盘,启动后实例马上被终止了。
A: Windows 使用 MBR 分区,最大支持 2TB 根盘。 Linux MBR 也受到同样限制。
解决办法:根盘使用小于 2TB 的 EBS,数据放在单独添加的 EBS。Linux 也可以使用 GPT 分区,不受 2TB 限制。
Q: CentOS 配置多网卡不生效。
A: CentOS 等非 Amazon Linux 系统,缺少某些网络安装包,需要自己配置策略路由。这样,从哪个网卡接收到的包,还从这个网卡发送回去。
Q: 创建 C4 类型 CentOS 实例,出现 1/2 检查状态,不能登录。
A: C3/C4 等类型实例,默认启用增强网络。一些非 Amazon Linux,可能没有 ixgbev f增强网络驱动,实例不能正常启动。
解决办法:安装 ixgbevf 增强网络驱动。
Q: 如何在中国区使用 CentOS?(中国)
A: 中国区暂时没有官方 CentOS。可以自己以 VM Import 方式从本地虚拟机镜像导入,或者,从 AWS 海外区域通过dd 镜像文件导入中国区 AMI。
由于安全原因,不推荐使用非官方的社区 Centos。
EBS |
Q: 为什么 EBS 没有达到预期的 IOPS,却被限制了?
A: EBS 除了IOPS,还有最大吞吐量限制 (GP2 160MB/s, IO1 500MB/s)。这个与 IO 大小有关。请检查 Cloudwatch 的吞吐量指标是否达到上限。
另外,对于连续的小 IO,会合并成单个 IO。
Q: 创建了 EBS,在 attach 实例时,找不到需要的实例。
A: EBS 要与 EC2 实例位于同一个可用区 (Availability zone),才能 attach 到实例。
Q: 如何为 EBS 自动创建快照?
A: 方法1:创建定时任务,定期执行 AWS CLI 命令进行快照。
方法2:使用 Cloudwatch Events + Lambda,无服务器方式自动运行。
ELB |
Q: 访问 ELB,有的请求正常,有的超时。
A: 公开的 ELB 要位于 VPC 里的公有子网,即有 IGW,可以从 Internet 访问。如果 ELB 所在的子网,包括了私有子网,这样 ELB 会在私有子网里创建节点。当从 Internet 访问时,DNS 解析到私有子网的节点,这部分请求就不可达。
Q: 后端服务器日志发现所有的请求源 IP 都是 ELB,如何获取客户端真正的 IP?
A: HTTP 监听方式时,后端服务器启用 X-Forwarded-For 特性。
TCP 监听方式,ELB 要开启 forward protocol,加入特定 header。
Q: ELB/ALB 采用什么算法转发请求到后端实例?
A: ELB TCP 监听端口使用轮询算法,HTTP 监听端口使用未完成最少请求算法。
ALB 使用轮询算法。
如果只有1个健康的后端实例,所有请求都会被转到此实例。如果没有任何健康的后端实例,请求会被转发到所有已注册但是不健康的实例。
Q: ELB 不是由客户控制,出现服务器错误如何排查?
A: 客户端请求返回 5XX 错误,可以根据 HTTP 代码,结合 Cloudwatch HTTP 5XX、ELB 5XX、Backend Connection Errors 等监控指标,初步判断是 ELB 还是后端服务器问题。
如果是 504 网关超时,还要打开 ELB 访问日志,在客户端和后端服务器进行抓包分析。一般来说,如果后端 web 服务器启用 keep-alive,超时时间要大于 ELB 空闲超时。
Q:NLB 如何选择子网?
A: NLB 要位于公有子网。后端目标实例,可以位于公有子网,也可以位于私有子网。注意:如果后端实例位于私有子网,需要设置 NAT,让数据包能有回到客户端的路由。这一点与 ELB/ALB 不同。
Q: 应用程序访问 ELB,有时候会出现 Unknown host 无法解析的错误。
A: ELB 会根据流量自动扩展或者缩减,IP 发生变化。DNS 服务器需要及时更新变化。ELB DNS TTL 是60秒,ELB IP 变化后,会在60秒之内更新 DNS 记录。但是由于客户端有缓存,如果一直不更新,就会出现无法解析的问题。
默认 Java DNS TTL 是永久生效,重启 Java 可以临时解决问题。建议修改 Java DNS TTL 为60秒。
Q: ELB 预热或者固定 IP 申请时,如何估算 ELB 的请求/响应平均流量?
A: 举例:一个200KB 的网页通常不太可能是在一次请求/响应中将200KB 的流量全部流过 ELB。更可能的分布是:20KB 是 HTML,30KB 是 Javascript/CSS,150KB 是10个15KB 图片,总共12个请求。这样一个经过 ELB 的请求/响应平均流量不是200KB 而是17KB (200/12=16.67)。如果您将静态内容和下载内容优化在了 S3 或者 CDN 中,这个 ELB 的请求/响应平均流量会更加小。
Glacier |
Q: 归档到 Glacier 的文件,如何根据文件名取回?
A: Glacier 的归档对象都有archive id,以此取回数据。但是 archive id 是一串字符,并非文件名。可以使用数据库(例如 DynamoDB)记录文件名和 archive id 的对应关系。或者,在归档对象的描述中,写入文件名。在归档文件很多的情况下,建议使用数据库方式,提高效率。
Storage Gateway |
Q: 是否支持高可用性架构?
A: 无论使用哪种类型的网关,都是需要在本地或者 EC2 安装网关虚拟机,作为本地和 AWS 之间的存储网关。此网关只有一个,虚拟机本身不支持高可用架构。
Q: 使用文件共享类型网关,传输速度很差。
A: 影响性能的因素有:网络、S3、存储网关、客户端。
NFS 客户端挂接存储后,所有读请求是要先到网关。如果网关缓存有数据,则直接返回客户端。
写请求也是要先到达网关,先写入网关的本地存储磁盘,然后再异步复制到 S3。
S3不会限制传输带宽。一般来说,本地网络到 Internet 的出口带宽,只会影响到网关向 S3 复制数据。
对于客户端来说,传输速度是对于客户端到本地存储网关而言。客户端的设置,以及本地网关的性能,是最大的决定性因素。
Windows 2008 支持 NFSv3,Windows 2012/2016 支持 NFSv4。V4 cache 比 V3 大了很多,对于 NFS 来说,性能影响很大。
网关服务器要有足够的 CPU 处理能力和内存。Upload buffer 最小150GB,Cache 建议是 upload buffer 的1.1倍。存储网关的物理机上,在创建虚拟机磁盘文件时,系统和 cache/upload buffer 所在的物理磁盘要分开,并且尽量使用 SSD。
IAM |
Q: 如何让登录 AWS 控制台的 IAM 用户只能启动或停止某些 EC2 实例?
A: IAM 用户登录到 AWS 控制台,要么列出所 有EC2 实例,要么什么都不能列出。因为,DescribeInstances 权限不支持资源级别,不能单独对于某些资源(EC2 实例、VPC 等)做权限控制。对于不支持资源级别的权限,在策略的 Resource 部分,只能用*来代表所有资源。
StartInstances/StopInstances 支持资源级别权限,可以定义实例 ID,或者通过其他条件来控制。
以下 IAM 策略,允许列出所有 EC2 实例和状态,并且只能对于标签 Group=test 的实例进行 start/stop 操作。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:StartInstances",
"ec2:StopInstances"
],
"Resource": "arn:aws-cn:ec2:cn-north-1:794767850066:instance/*",
"Condition": {
"StringEquals": {
"ec2:ResourceTag/Group": "test"
}
}
},
{
"Effect": "Allow",
"Action": [
"ec2:DescribeInstances",
"ec2:DescribeInstanceStatus",
"cloudwatch:Describe*",
"cloudwatch:Get*",
"cloudwatch:List*"
],
"Resource": "*"
}
]
}
除了标签,还可以直接定义实例 ID,或者其他符合的条件,来进行 stop/start 权限控制。
参考:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ec2-supported-iam-actions-resources.html
RDS |
Q: 分别在物理机和 AWS RDS 进行测试,为什么类似的机型,同样的测试方式,结果却显著不同?
A: 测试对比的一个前提是,环境一致。除了服务器处理能力,测试方法外,存储性能,以及数据库本身的参数,都会影响结果。
RDS 如果是从快照恢复,EBS 存储会有一个预热过程,需要先对 EBS 里的数据块进行读取,才能达到最佳性能。测试建议使用新建 RDS,而不是从快照恢复,这样使用全新的 EBS,不会有预热问题。
EBS 的 IOPS 也会有影响。可以通过 Cloudwatch 监控,确保 EBS IOPS 或者吞吐量,没有达到上限。
数据库参数对性能影响极大,例如 innodb_flush_log_at_trx_commit。确保测试比较时,数据库参数一致。
Q: 访问不同 AZ 可用区的应用,连接 RDS,延迟差异明显。
A: 为了实现高可用性,把应用部署到不同 AZ 的 EC2。RDS 位于某个 AZ。当从 EC2 访问不同 AZ 的 RDS 时,有微小的网络延迟。如果应用程序在 EC2 和 RDS 之间有多次交互,那么会把微小的网络延迟放大。
对于网络延迟要求很高的业务,可以优化应用,避免在一次交易中进行多次数据库访问。如果应用不能调整,尽量把应用服务器放在与 RDS 同一 AZ,但是这样会有高可用的隐患,需要在性能和可用性之间做出权衡。
Q: RDS 很多命令执行出现权限错误。
A: RDS 是托管服务,有很多机制来保证数据库的高可用。涉及到操作系统或者数据库底层的方面(例如系统表),一般不能修改。常见的数据库操作,可以通过一些定义好的存储过程来进行。
例如,杀掉 mysql 进程:
CALL mysql.rds_kill(processID);
其他的一些操作,例如修改数据库参数,可以通过参数组里的参数来修改。
参考:https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Appendix.MySQL.CommonDBATasks.html
Q: RDS Mysql 主从复制,能否选择表?
A: RDS 和外部 Mysql 之间的主从复制,可以通过外部 Mysql 的 /etc/my.cnf,replicate-ignore-db 或 replicate-do-db 来选择表。
RDS 内部的复制,目前还不支持选择表。
Q: RDS 显示磁盘容量耗尽,但是似乎并没有那么多的数据。
A: 除了数据库表的数据,还有索引、日志、临时空间,都会占用存储。Mysql 日志会占据最高 20% 或者 10GB 的存储空间。一些复杂查询可能会使用大量的临时存储。可以设置 Mysql binlog 保留时间,以及是否开启 general log。
Q: RDS MysQL 数据库重启,提示 Out of memory
A: 内存耗尽,和数据库参数有关。max_connections 定义了最大连接=内存字节 /12582880。如果修改了此参数,突破限制,可能会造成内存耗尽。监控机制发现问题,自动重启数据库。
Q: RDS Mysql 主从复制延迟一直在增加。
A: 主库和从库实例类型要一致,否则容易因为处理能力有差异,在数据量大时,产生滞后。
分别检查主从库的 EBS IOPS 和吞吐量,是否达到上限。
检查从库是否有锁操作。
查看 slave 状态,show slave status \G; 检查是否复制过程中有错误产生而产生停滞。如果有,跳过错误重试。
Mysql 5.7 允许并行复制,以提高同步效率。数据量大时可以打开此功能。
slave_parallel_type=LOGICAL_CLOCK
slave_parallel_workers>1
Q: RDS 设置为公开访问。如何从同一个 VPC 内的 EC2 访问 RDS,不走外网?
A: RDS 域名在创建 RDS 时生成。应用程序需要访问 RDS 域名。如果 EC2 和 RDS 位于同一个 VPC,DNS 解析出内网 IP,通过私有网络连接。
Q: 为何 RDS MySQL 不能通过时间点恢复数据?
A: RDS MySQL 要启用 binlog,通过快照 +binlog 的方式,恢复到之前的某个时间点。
如果没有启用自动快照功能,binlog 不会保存,也就不能通过时间点恢复。
另外,只有 innoDB 表才能使用此功能。MyISAM 不基于事务,重启或者数据库故障时可能会丢失数据。如果没有特别要求,建议使用 innoDB 存储引擎。
Q: 如何进行数据库迁移?
A: Mysql: 采用全量 Mysqldump+ 增量 replication 方式。但是,在 mysqldump 导出数据并复制到目标数据库这段时间内,主库要设置为只读,避免新的数据写入。
Oracle:Dataguard 或者 GoldenGate。但是需要特定的 Oracle 企业版本,或者单独购买许可。
AWS DMS 服务:在线数据库同步。主库无需设置只读,同步过程中通过中转节点读取日志变化,并在同步到目标数据库时重放这些变化。即使数据库位于私有子网,DMS 也可以访问数据库,并设置为源或者目标。DMS支持不同数据库迁移,包括 RDS 支持的数据库,以及 Redshift。
AWS DMT 工具:中国还没有上线 DMS 服务,可以申请 DMT AMI,创建 EC2 实例,带有 DMT 图形化迁移工具。
DynamoDB |
Q: DynamoDB 预配置很多读写容量,但是没用多少,就出现受限错误。
A: DynamoDB 预配置读写容量按照整个表来统计。DynamoDB 有分区,每个分区的资源是有限的。当预配置读写容量,或者数据量超过一定程度时,DynamoDB 会自动分区。根据主键 partition key 哈希值,确定每个 item 的所在分区。如果某些特定的 item 读写量巨大,落在某个分区,耗尽此分区的 IO 资源,就会出现受限。
举例,为某个表设置了10000读容量和4000写容量,可能需要总共8个分区。根据预设值的容量计算,每个分区的读容量上限为1250。某些热点数据读取过于频繁,达到1250会出现错误。
还有一种可能,之前设置了大读写容量,自动进行分区。后来减少读写容量,但是分区不会减少,这样分配给每个分区的读写容量更少,更容易出现热点分区数据受限的问题。
解决办法:
增加读写容量。
避免过度的热点数据访问。
DynamoDB 之前加入 Elasticache 缓存,或者 DynamoDB DAX 缓存功能,来减少读写压力。
Q: DynamoDB 中国区如何备份?
A: DynamoDB 在海外区域已经有备份恢复功能,但是中国区目前还没有。可以使用 DynamoDB 自带的导出 csv 功能,或者第三方工具,把数据导出成文件。
ElastiCache |
Q: 如何监控 Elasticache Redis 性能指标?
A: Cloudwatch 有以下指标需要关注:
CPUUtilization:CPU利用率。对于Redis这种缓存服务来说,一般CPU利用率不高。
SwapUsage:交换分区。内存不足时会使用。但是,如果只是偶尔出现少量的 swap 使用,也有可能是操作系统某些动作所产生。如果其他指标,例如BytesUsedForCache, Evictions 正常,可以不必过于关注。
Evictions:由于超过最大内存限制,而被驱逐出的key数量。这是重要指标。检查 BytesUsedForCache 指标,如果几乎用满了分配的内存,说明内存不足。
BytesUsedForCache:分配给 Redis 的内存。注意,有部分内存是保留给备份或者复制等操作所使用。有可能看到的情况是,选择了16GB内存的 Redis 实例类型,最多只能使用12GB。新创建的 Redis,默认保留25%内存。请检查 reserved-memory 和 reserved-memory-percent 这两个参数。
CurrConnections:当前客户端连接数。如果与之前相比,出现异常,请检查应用程序。Redis是单线程,客户端一般是通过连接池来管理,提高效率。
FreeableMemory:操作系统层面的可用内存。Linux 的一个机制是,尽量使用 buffer/cache,很多内存用于缓存,可用内存一般很少。如果可用内存很少,而其他 Redis 指标正常,不必担心。
Q: Elasticache Redis 如何做持久化?
A: AOF (Append Only Files ) 把数据放在本地磁盘,此功能2.8以及之前的版本默认不开启,3.2以上版本进禁止修改。建议使用复制组,而不是 AOF。本地磁盘位于实例存储 (instance store),用于存储临时数据。如果出现底层硬件故障,本地磁盘的数据,包括 AOF,也会丢失。而复制组位于多可用区,数据自动复制到只读副本,可以自动实现故障转移。
Q: Elasticache Redis 复制组如果出现故障,应用是否需要调整?
A:如果只读副本出现故障,那么会自动启动新的只读副本以替代故障节点。应用程序需要修改只读请求,到新的只读副本。到主节点的读写请求无需修改。
如果主节点出现故障,那么会自动提升某个只读副本为新的主节点,DNS 会指向新的 IP。对于应用程序来说,读写请求还是指向主节点 DNS,无需修改。而只读请求要修改,包括新的只读副本。
Q: 如何设置Redis用户名密码登录?
A: Elasticache Redis 不支持用户名密码登录。可以通过安全组和网络 ACL,只允许信任的 IP 访问。
Q: 如何设置 Redis 允许从外网访问?
A: Elasticache Redis 设计成内部访问,DNS 解析出来的 IP 都是 VPC 内的私有地址。从外网访问,网络延迟会影响性能,并且也不安全。
如果一定要从外网访问,可以在 VPC 内把一个 EC2 实例做成 NAT,添加 iptables 规则,从外网访问 EC2 某个端口(例如6379),通过 NAT 端口映射到内网 Redis 端口。请注意,这些外网流量不加密,谨慎选择此方式。
Q: Elasticache Redis 有集群和非集群模式,如何选择?
A: 两种模式都支持主从方式实现高可用性。集群模式中,每个分片中都有一个复制组,包括一个主节点和多个只读副本。
两种模式的不同在于扩展性。
非集群模式中,主节点只有一个,如果内存不足,只能通过升级节点类型的方式。只读副本最大5个。
集群模式提供了分区功能。如果主节点写请求压力大,使用集群模式进行分区,最大15个,把数据写入到多个节点,实现更好的扩展。对于读请求,集群模式可以有最多15*5=75个只读副本。
Redshift |
Q: 将 S3 中的大量 Gzip CSV 导入 Redshift,如何提高并发 COPY 性能?
A: Redshift COPY 性能受以下因素影响:
并行传输。将数据拆分成多个文件,同一个 COPY 命令可以把多个文件并行写入到同一个表。请注意,此特性不适用于多个 COPY 命令写入同一个表,需要等待前一个 COPY 完成才能继续。
表压缩。默认情况下, COPY 空表自动压缩。压缩消耗资源,会牺牲一部分 COPY 性能,以换取更小的存储空间。需要在性能和存储之间做出权衡。COMPUPDATE OFF(或 FALSE),将禁用自动压缩。
表分析。默认情况下,COPY 命令会在将数据加载到空表后执行分析。分析就是运行 ANALYZE 命令,以构建和选择最佳计划的统计元数据,也需要消耗资源。在导入过程中,COPY 命令加入 STATUPDATE OFF(或 FALSE),不会更新统计数据。
排序键。如果表定义了排序键 (sort key),可以在 COPY 导入数据的时候更有效率,并且提高查询效率。
分配。Redshift 导入数据时,会把每一行数据按照 distribution style 存储到不同的计算节点。这对于之后的查询性能也很重要。
文件压缩。多个csv gzip 文件直接放在 S3,在导入 redshift 的时候,需要解压,会影响性能。如果都是小的压缩文件,请解压后再上传到 S3,然后再 copy 到 redshift。
Q: Redshift 为多个表创建联合视图,表已经创建了SORT KEY,但是查询性能很低。
A: Redshift sort key 默认为 COMPOUND。如果查询条件中使用了这个 sort key 所包含的所有列,那么查询效率将会很高。相反的,如果查询条件中,并没有包括 sort key,或者只包含 COMPOUND SORT KEY 某一部分,查询效率将会下降。
查询视图需要遍历所有数据,视图会创建临时表,并扫描此临时表。即使源表设置了sort key,视图也不会使用,从而降低查询效率。
解决方案:
修改 sort key 为最需要排序的列,并且在查询中使用 sort key 的所有列,而不要只指定 sort key 的部分列。如果只需要其中一些列作为优化排序,在创建表时,使用 INTERLEAVED SORT KEY语句。
只创建一个表,每天的数据通过 COPY 命令导入 Redshift 这个表。单个表的查询,可以直接使用 SORT KEY 优化。
如果有别的表需要 JOIN 操作,设置正确的 DISTKEY,避免不必要的节点之间数据传输。
如果表排序已经很乱,或者有一些空间标记为删除,但是没有回收,请运行 vacuum 命令以回收空间,并执行排序。
Q: Redshift 无法并行跑大 Query,出现 out of memory。
A: 以下是 Redshift 的一些统计信息。
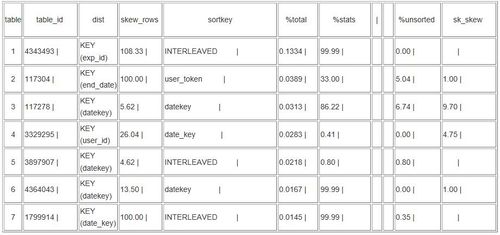
skew_rows 表示不同切片中,最多行数与最少行数的比率。这些表倾斜严重,说明分配不当,消耗更多内存,严重时耗尽内存资源。并且,一些表使用了 date 类型的字段作为 dist key,但是 date 类型并不适合。
这些问题会消耗大量内存。
解决方案:
重建倾斜严重的表,选择适当的 DIST KEY,要与其他表最为关联的列。
Q: Redshift 是否可以在线扩容?
A: Redshift 可以修改节点数量,实现在线扩容。修改过程是,新建一个 Redshift 集群,把数据复制过去。如果数据量很大,修改可能需要很长时间。也可以考虑把原有集群创建快照,从快照恢复新的集群,再进行改名操作。这样可能会节省时间。
API Gateway |
Q: 为什么访问 API Gateway,出现 403 Forbidden 错误?(中国)
A: 由于中国政策原因,在中国使用 API Gateway,需要提交申请,把帐号加入白名单。
SNS |
Q: SNS 是否支持移动消息推送?(中国)
A: 中国区目前不支持移动消息推送功能,以及 SMS 手机短信功能。SNS 可以发送消息到 Lambda 或者 SQS 消息队列,您可以自己开发程序,进行移动消息推送。
EMR |
Q: EMR 数据如何选择,存放于 HDFS 还是 S3?
A: HDFS 运行于 EC2,与 S3 都位于 AWS 内部网络。访问 S3 并不比 HDFS 有明显的网络延迟差异。
相对于 HDFS,数据存放于 S3,有更多好处:
S3 具有11个9的持久性,基本不会丢失数据。
S3 具有无限容量,而 HDFS 要受到本地存储容量限制,以后扩展性受限。
如果数据要迁移到新集群,位于 S3 的数据会一直存在,而 HDFS 则需要进行数据迁移。
Q: EMR 资源不足,如何扩容?
A: EMR 可以更改节点数量。如果数据量大,时间会很长,甚至几天。修改一旦开始,就不能停止。如果有大量数据都存放在 S3,那么可以重建 EMR,甚至使用自定义 AMI,数据也不会丢失。
Q: EMR 出现磁盘容量不足。
A: EMR 上的应用,在可能的情况下,尽量使用 S3 替代 HDFS,不用占用本地存储。
/mnt /mnt1 这些本地目录一般用于存储临时数据和日志。有时候临时数据没有清理,会出现这些目录占满磁盘。需要经常清理,或者运行自定义 Cloudwatch 磁盘使用率监控脚本,当磁盘不足时,自动发送通知。
Q: 如何把 S3 多个小文件合并成大文件?
A: s3distcp 运行MR任务,把 S3 或者 HDFS 的多个文件合并。例如:
s3-dist-cp --src s3://support-billing/ --dest s3://pingaws-support/billing/ --groupBy='.*(794767850066*?).*'
Amazon Web Services ( AWS )技术峰会 2018 中国站(上海)已经于 6 月 29 日圆满落幕,感谢您对 AWS 的关注和支持。精彩仍在继续,所建皆为不凡,AWS 技术峰会 2018 中国的第二站即将启航。AWS 技术峰会 2018 北京站,将在2018 年 8 月 9 日登陆北京国家会议中心!
想和我们一起#所建不凡#?快来注册#AWS技术峰会2018,前20名注册的小伙伴将可获得 $50亚马逊优惠券,抓住机会,赶快注册吧!https://awssummit.cn?tc=1s016B2uQi







热门评论
-

慕码人84219752019-05-27 0
查看全部评论您好,看了您整理的AWS常见问题,很详细,想问下,这些常见问题如何从AWS官方网站整理的,是如下https://aws.amazon.com/cn/ec2/faqs/?nc1=h_ls类似的链接吗,谢谢!