
写在前面的话:我们前面学习了正则,但是正则是个很繁琐的东西,一旦写错,就要匹配失败,我们还要不断的调试,对于一个网页来说都是具有一定的层次性,有的有id,class名,我们可不可以通过这些来获取我们想要的属性或者文本?下面可以看看怎么来获取。
1,XPath的使用
在使用前,需要安装lxml库。
安装代码:pip3 install lxml
1.1XPath的常用规则:
/ 表示选取直接子节点
// 表示选取所有子孙节点
. 选取当前节点
.. 选取当前结点的父节点
@ 选取属性
看完这些?你是不是还是一脸懵逼?下面我们来实际运用一下。
1.2实例引用
如图:
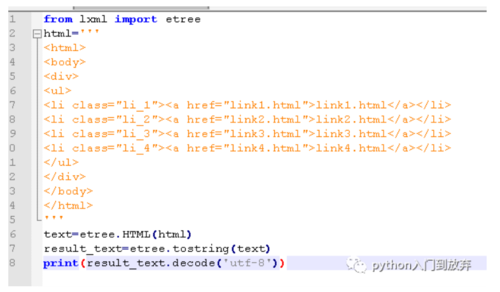
导入etree模块
etree.HTML()是构造一个XPath对象
etree.tostring()是对代码进行修正,如果有缺失的部分,会自动修复
方法比较简单,就不截取效果图了。
如果我们相对本地的文件进行解析怎么办?我们可以这样写

etree.parse()第一个参数为html的路径,第二(etree.HTMLParser())和上面etree.HTML()的性质是一样的,为了方便,接下里我使用对本地文件进行解析。
html文本如下:
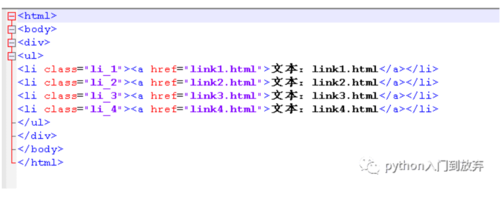
1.3获取所有的节点

结果:

开头用//表示选取所有符合的节点,*表示获取所有的节点,
上面两句话一看这不是一个意思吗?会不懂!
我们可以分为两步理解:
第一步//是选取所有符合要求的节点,没有指明是什么要求!,不知道你要获取什么.
第二步*表示所有节点,所以才会获取所有节点。这样理解起来应该会很容易了吧。
注意:返回的是一个列表
1.4获取指定的节点
还是上面的html文本,如果我们想获取li节点怎么办?
只需要将result_text=html.xpath('//*')修改成result_text=html.xpath('//li')
如果想获取a节点,就修改成//a,也可以写成//li//a,或者//ul//a获取//li/a
都是可以获取到但是如果//ul/a是获取不到的因为/表示的是直接子节点
注意:返回的都是节点,并不是文本信息。
即:

这种形式。
1.4属性匹配
如果我们想要a标签的href属性,我们可以修改成//a/@href
返回结果:
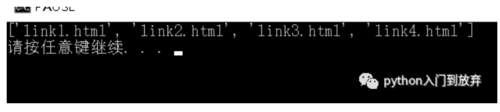
返回的也是一个列表
如果我们想要匹配class为li_1的li,可以修改成//li[@class="li_1"]即可
1.5父节点匹配
我们来获取link2.html的a节点的父节点的class属性,我们是需要修改成//a[@href="link2.html"]/../@class,这里的..表示寻找父节点,返回的依然是一个列表。
1.6获取文本
我们来获取class为li_3的li下a的文本,可以写成//li[@class="li_3"]/a/text()即可
1.7contains()函数
比如其中有一个li为:<li class="li li_last" id="caidan"></li>
此时:li具有两个class名,我们如果这样写//li[@class="li"]是获取不到节点的
那么我们可以这样写获取到节点//li[contains(@class,"li")]。
1.8多属性获取
<li class="li li_last" id="caidan"></li>,同样是这个li我们需要获取class名为li同时id为caidan的li,可以这样写//li[contains(@class,"li") and @id="caidan"]
获取class名为li或者id为caidan的li就用or。
1.9,last(),position()函数
上面的html有很多li,如果我只想获取第一个可以这样:
//li[1],同理第二个改成2就可以了,如果想获取最后一个://li[last()]
如果想获取前两个://li[position()<3]
2,Beautiful Soup的使用
同样的在使用前我们也要安装Beautiful Soup
没有安装的请自行安装。
首先导入模块:from bs4 import BeautifulSoup
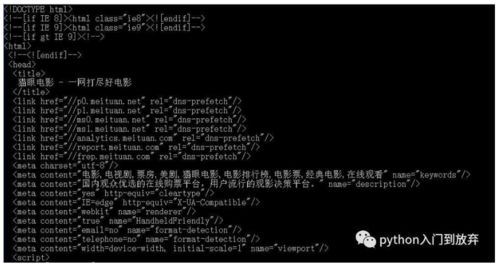
这次我们直接用一个网站来试试,我选择的是猫眼网,
你可以选择其他网站哦。
获取网页部分,上节有教,链接:python第二大神器requests
如图:
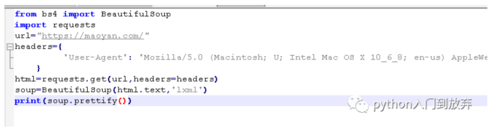
2.1初始化
BeautifulSoup()第一个参数为获取的网页内容,第二个参数为lxml,为什么是lxml?因为Beautiful Soup在解析时依赖解析器,python自带的解析器,容错能力差,比较慢,所以我们使用第三方解析器lxml,
prettify()是将获取的内容以缩进的方式输出,看起来很舒服
如图:
看起来舒服多了。
2.2获取值
我们来获取一下title信息,我们是需要这样。
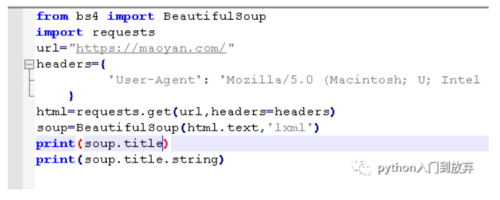
结果:

我们可以看到title获取的是title节点的所有信息,而加个string就变成了title里的文本内容,这样是不是也是很简单?
2.21获取属性值
比如,我们想要获取img的src属性,我们只需要,soup.img['src']就可以获取到,soup.img.arrts['src']也可以获取到。
如果想获取到所有的属性就这样写:soup.img.arrts即可
如图所示:

注意:所有的属性返回的形式是以字典的形式返回。
2.3获取直接子节点和子孙节点,父节点,祖先节点,兄弟节点
获取直接子节点:contents,例如我想获取p标签的直接子节点:soup.p.contents即可
获取子孙节点:descendants,例如我想获取p标签的子孙节点:soup.p.descendants即可
获取父节点:parent属性,例如我想获取p标签的父节点:soup.p.parent即可
获取祖先节点:parents属性,例如我想获取p标签的祖先节点:soup.p.parents即可
获取兄弟节点:next_sibling,previous_sibling,next_siblings,previous_siblings分别为下一个兄弟节点,上一个兄弟节点,上面所有的兄弟节点,下面所有的兄弟节点。
2.4获取文本属性
string为获取文本
attrs为获取属性
2.5方法选择器
find_all()返回的一个列表,匹配所有符合要求的元素
如果我们想要获取ul可以这样写:soup.find_all(name='ul')
如果我们想要获取id为id1属性可以这样写:soup.find_all(arrts[id='id1'])
如果我们想要获取class为class1属性可以这样写:soup.find_all(arrts[class_='class1'])
因为class有特殊意义,所以我们获取class的时候价格_即可
如果我们想要获取文本值可以这样写:soup.find_all(text=re.compile(''))
匹配text需要用到正则,匹配你想要的text值
find()只返回一个值,匹配到符合要求的第一个值。
用法和上面的方法一样
注意:以上说有的属性,方法都是通过我实例的soup来调用,soup是我的命名,你可以修改它,同时你调用就要用你的命名了
2.6css选择器
我们如果用css选择器需要调用select()方法
比如想获取class名为class1的节点,我们可以这样写:soup.select('.class1')即可,和css的表达方式是一样的,但是他的css选择器功能不够强大,下面我们介绍一个针对css的解析库。
3,pyquery的使用
首先要安装pyquery
没有安装的请自行安装。
导入模块:from pyquery import PyQuery
首先和上面的一样,同样需要初始化,获取对象
如下:
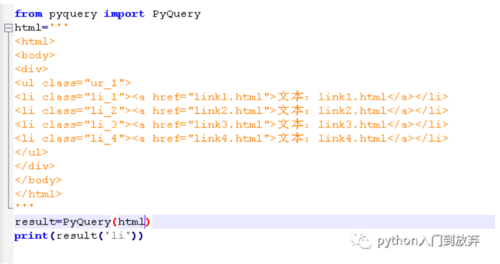
结果:
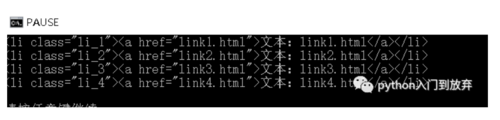
这样就获取到了所有的li
此外:初始化对象时,可以填写文本(上面就是),还可以填写url:PyQuery(url='https://maoyan.com/')
还可以填写本地文件:PyQuery(filename=''),''中填写本地文件的路径
3.1css选择器的基本用法
如果想选取class名为class1下的li可以这样写result('.class li')和css的选择器写法是一样的。
3.2find()方法,子节点,父节点,兄弟节点
和上面不同这里的find()方法是查找所有的子孙节点,
如果想获取li下的所有a节点可以这样写:result('li').find('a')即可
如果只想查找子节点:children()方法即可
父节点:parent()获取直接父节点
获取所有父节点:parents()获取所有父节点,如果只想要父节节点中class为class1的可以这样写:parents('.class1')
注意:输出的是父节点的所有内容。
兄弟节点:siblis()方法,如果只想要兄弟节点中id为id1的可以这样写:parents('#id1')
3.3对于获取的结果,不想上面返回的是列表,这里如果返回多个对象需要for循环遍历
3.4获取属性,文本,
例如我们想要获取li下a的href属性(attr()函数),由于有多个结果,所以我们这里需要遍历。
如图:
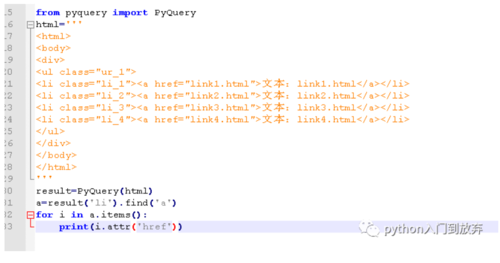
结果:

注意:如果不遍历,只会输出第一个
如果我们想要获取文本值:text()方法,只需要将attr()函数改为text()函数即可
3.6对属性,文本,class的删除,修改
addClass('class1'):表示添加一个class名,名字为class1
removeClass('class1')表示删除一个class名,名字为class1
我们来实例一下:
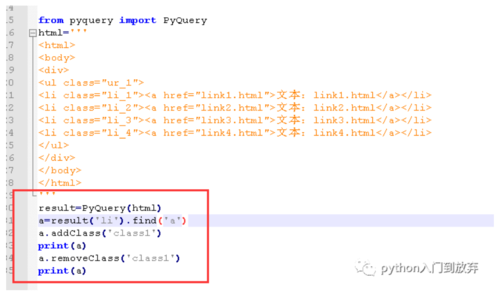
结果:

同时我们还可以添加属性,文本
添加属性:attr('name','name1')
添加文本:text('123123')
添加代码:html('12122')
有了添加,就有删除remove()函数
比如如果我们想删除li下的所有a节点
可以这样写:result('li').find('a').remove()
4.0完
作者:初新晓
链接:https://www.jianshu.com/p/ef5fc046fcea





