
神经网络基本理论
人工神经网络本质是用机器函数拟合的过程(输入拟合函数输出)模拟人脑学习的过程(现象内在规律知识),其基本结构如下图:
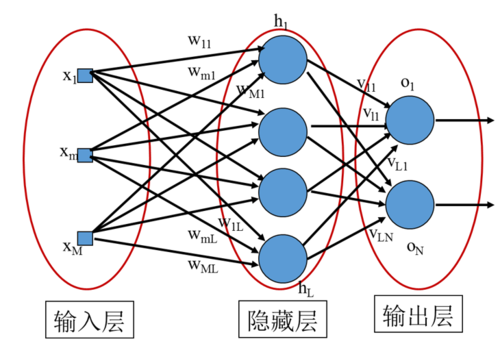
图1 神经网络基本结构
其具有如下特点:
•神经元及其连接
•输入层、输出层和隐藏层
•输入、输出层各一,隐藏层大于1时为深度神经网络
•输入输出节点数固定
•信息在层间的传输由连接强度决定
•连接强度随训练而改变
具体到神经单元之间的连接,同样是模拟神经元:

图2 神经单元信息传递
RNN与LSTM
NLP中常将中文的分词问题转换为序列标注问题。例如用BMES对‘小明’进行标注
小=[1,0] label=[1,0,0,0]
明=[0,1] label=[0,0,1,0]
基本的神经网络无法考虑上文信息(最多能考虑固定长度的相邻信息),由于训练语料中出现大量明天、明白、明暗等词,所以导致明.label=[1,0,0,0]×
如果现在通过某种方式告诉神经网络‘明’的上下文信息,那么:
小明、小明、小明、小明明.label=[0,0,1,0]√
上面提到的某种方式就是RNN。

图3 RNN网络结构
RNN通过连接每次输入的隐藏层节点实现单向传递过去信息的效果,所有输入共享参数矩阵。在有时间特征和序列特征的数据处理中经常使用RNN且能得到更好的效果。
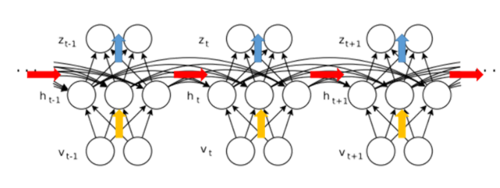
图4 RNN结构展开示意图
然而基本的RNN本身存在设计缺陷。若只看图3蓝色箭头线的、隐藏状态的传递过程,不考虑非线性部分,那么就会得到一个简化的式子(1):
(1) ht= Whh· ht-1
•如果将起始时刻的隐藏状态信息h0向第t时刻传递,会得到式子(2)
(2) ht= (Whh)t· h0
•Whh会被乘以多次,若允许矩阵Whh进行特征分解
(3) Whh = Q·ᴧ·QT
•式子(2)会变成(4)
(4) ht= Q·ᴧt·QT·h0
当特征值小于1时,不断相乘的结果是特征值的t次方向0衰减;
当特征值大于1时,不断相乘的结果是特征值的t次方向∞扩增。这时想要传递的h0中的信息会被掩盖掉,无法传递到ht。
为了解决上述问题,设计了LSTM。LSTM是在标准RNN的基础上装备了若干个控制数级的gates。可以理解成神经网络(RNN整体)中加入其他神经网络(gates),而这些gates只是控制数级,控制信息的流动量。根据gates所用于控制信息流通的地点不同,它们又被分为:
•输入门:控制有多少上一时刻的单元输入信息可以流入当前单元。
•遗忘门:控制有多少上一时刻的单元中的输出信息可以累积到当前时刻的单元中。
•输出门:控制有多少当前时刻的单元中的信息可以流入当前隐藏状态中。

图5 LSTM神经单元结构
常规的递归网络只对所有过去状态存在依赖关系。所以递归网络的一个扩展就是双向(bidirectional)递归网络:两个不同方向的递归层叠加。

图6 BI-LSTM网络结构图
BI-LSTM(双向长短期记忆模型)至少含有两个递归层,正向与反向递归层,其网络结构如图所示。正向(forward)递归层是从最初时刻开始由前向后计算,而反向(backward)递归层是从最末时刻开始由后向前计算。各个递归层的计算结果通过一定方式综合起来得到最终隐藏序列值。
现在在NLP序列标注工作中比较流行的做法是将BI-LSTM的输出端的Softmax与CRF结合,即BI-LSTM-CRF模型,这个放到本人设计的DBLC模型中介绍(如果不悖学术道德...)。
代码与实验对比
这里用TensorFlow对BI-LSTM做一个简单的序列标注示例。
输入数据的格式、label格式,网络参数矩阵定义如下所示(不知道简书怎么插公式,直接截图了)。数据均采用One-Hot方法进行向量化。

图7 LSTM序列标注示例
完整代码放在最下方,只用了中国管理案例库的语料中的609个字训练,但效果比7个字好多了...训练数据量对神经网络来说确实很重要。

图8 训练数据量对训练效果的影响
图中more是用609个字,而less是7个字。蓝线准确率上升平稳,偶然性较小,且最终得到更高的结果。
接下来是LSTM与BI-LSTM对比。

图9 LSTM与BI-LSTM训练Loss对比

图10 LSTM与BI-LSTM训练Acc对比
import tensorflow as tffrom numpy import *from gensim.models import word2vec
tf.set_random_seed(1)
lr = 0.001batch_size = 609epoch=1500n_inputs = 6 # 输入层节点数n_steps =1# 时步n_hidden_unis = 7 # 隐藏层节点n_classes = 4 # 输出层节点数def getData():
f=open(r'C:\Users\Administrator\Desktop\程序\DL for NLP\tf_tagging-master\tf_tagging\data\test\wordlabel.txt',encoding='utf8')
wordvlist,labellist=[],[]
f1=open(r'C:\Users\Administrator\Desktop\程序\DL for NLP\tf_tagging-master\tf_tagging\data\test\word.txt',encoding='utf8')
wordlist=list(set(l.strip() for l in f1.readlines()))
f1.close() for l in f.readlines():
word,label=l.split(' ')[0],l.split(' ')[1].strip()
wordv=zeros(len(wordlist))
wordv[wordlist.index(word)]=1
labelv=[0,0,0,0] if label=='B':
labelv=[1,0,0,0] if label=='I':
labelv=[0,1,0,0] if label=='E':
labelv=[0,0,1,0] if label=='s':
labelv=[0,0,0,1]
labellist.append(labelv)
wordvlist.append([wordv])
f.close() return len(wordlist),wordvlist,labellist
n_inputs,batch_xs,batch_ys=getData()
batch_xs = array(batch_xs)
batch_ys = array(batch_ys)# 定义训练数据的存储变量x = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
y = tf.placeholder(tf.float32, [None, n_classes])# 定义权重和偏移量矩阵weights = { # (10,7)
'in': tf.Variable(tf.random_normal([n_inputs, n_hidden_unis])), # (4,10)
'out': tf.Variable(tf.random_normal([n_hidden_unis, n_classes]))
}
biases = { # (10,)
'in': tf.Variable(tf.constant(0.1, shape=[n_hidden_unis, ])), # (4,)
'out': tf.Variable(tf.constant(0.1, shape=[n_classes, ]))
}def RNN(X, weights, biases):
# 输入层 => 隐藏层
# X(7 batch, 1 steps, 6 inputs) => (7*1, 6)
X = tf.reshape(X, [-1, n_inputs]) # W*X+B
X_in = tf.matmul(X, weights['in'])+biases['in']
X_in = tf.reshape(X_in,[-1, n_steps, n_hidden_unis]) # lstm_cell
lstm_cell = tf.contrib.rnn.BasicLSTMCell(n_hidden_unis, forget_bias=1.0, state_is_tuple=True)
_init_state = lstm_cell.zero_state(batch_size, dtype=tf.float32)
outputs, states = tf.nn.dynamic_rnn(lstm_cell, X_in, initial_state=_init_state, time_major=False) # 隐藏层 => 输出层
results = tf.matmul(states[1], weights['out']) + biases['out'] return results
pred = RNN(x, weights, biases)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
train_op = tf.train.AdamOptimizer(lr).minimize(cost)
correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
init = tf.global_variables_initializer()with tf.Session() as sess:
sess.run(init)
step = 0
while step < epoch:#这里是香格里拉
'''batch_xs = [[[1, 0, 0, 0, 0, 0]], [[0, 1, 0, 0, 0, 0]], [[0, 0, 1, 0, 0, 0]], [[0, 0, 0, 1, 0, 0]],
[[0, 0, 0, 0, 1, 0]], [[0, 1, 0, 0, 0, 0]], [[0, 0, 0, 0, 0, 1]]]
batch_ys = [[1, 0, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1], [1, 0, 0, 0], [0, 1, 0, 0], [0, 1, 0, 0],
[0, 0, 1, 0]]'''
sess.run([train_op], feed_dict={
x: batch_xs,
y: batch_ys
}) if step %50==0:
loss = sess.run(cost, feed_dict={x: batch_xs, y: batch_ys})
acc = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys})
print( str(step/50)+"test,Minibatch Loss= " + "{:.6f}".format(loss) + ", Test Accuracy= " + "{:.5f}".format(acc))
step += 1
print("Finish!")
作者:帅气的学术狗
链接:https://www.jianshu.com/p/a47cdedd4433





