
原理:
如果***type(text) is bytes***,
那么text.decode('unicode_escape')
如果type(text) is str,
那么text.encode(‘latin1’).decode(‘unicode_escape’) 
1. 案例:
*
#coding=utf-8import requests,re,json,tracebackfrom bs4 import BeautifulSoupdef qiushibaike():
content = requests.get('http://baike.baidu.com/city/api/citylemmalist?type=0&cityId=360&offset=1&limit=60').content
soup = BeautifulSoup(content, 'html.parser')
print(soup.prettify()) #.decode("unicode_escape")
#目前soup.prettify()为str
new=soup.prettify().encode('latin-1').decode('unicode_escape') #.dencode('latin-1').encode('latin-1').decode('unicode_escape')
print(new)if __name__=='__main__':
qiushibaike()2. 结果对比:
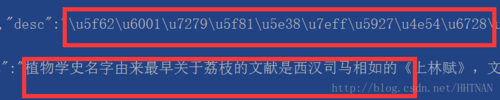
案例2,\xe5\x8f\xa4\xe8\xbf\xb9编码
\xe5\x8f\xa4\xe8\xbf\xb9编码处理
userInputTag=["\xe5\x8f\xa4\xe8\xbf\xb9","\xe5\xbb\xba\xe7\xad\x91"]print(userInputTag[0].encode('latin-1').decode('utf-8'))结果:
古迹
完成转化
出现GBK无法编译
另外爬取时,网站代码出现GBK无法编译python3,如出现如下:
<h1>ÖйúÉÙÊýÃñ×åÌØÉ«´åÕ¯[6]</h1>
示例:
#coding=utf-8import requests#共有6页,首页为空不为6for i in range(6): if i==0:
url='http://www.tcmap.com.cn/list/zhongguoshaoshuminzutesecunzhai.html'
else:
url='http://www.tcmap.com.cn/list/zhongguoshaoshuminzutesecunzhai'+str(i)+'.html'
response=requests.get(url)
print(type(response)) #如需成功编译,在.TEXT下面增加#号部分
html=response.text #.encode('latin-1').decode('GBK')
print(html)
文件读写操作codecs.open
python 文件读写时用open还是codecs.open
案例:当我们需要写入到TXT中的过程中
代替这繁琐的操作就是codecs.open,例如
import codecs
fw = codecs.open(‘test1.txt’,’a’,’utf-8’)
fw.write(line2)
不会报错,说明写入成功。这种方法可以指定一个编码打开文件,使用这个方法打开的文件读取返回的将是unicode。写入时,如果参数 是unicode,则使用open()时指定的编码进行编码后写入;如果是str,则先根据源代码文件声明的字符编码,解码成unicode后再进行前述 操作。相对内置的open()来说,这个方法比较不容易在编码上出现问题。





