
mongodb11天之屠龙宝刀(三)基本操作:增删改查与mysql对比
原文连接:直通车
基本概念_id和ObjectId:
1._id
MongoDB 中存储的文档必有一”_id” 键。这个键的值可以是任何类型的,默认是个ObjectId 对象。在一个集合里面,每个文档都有唯一的”_id” 值,来确保集合里面每个文档都能被唯一标识。如果有两个集合的话,两个集合可以都有一个值为123 的”_id” 键,但是每个集合里面只能有一个”_id” 是123 的文档。
2. ObjectId
ObjectId 是”_id” 的默认类型。它设计成轻量型的,不同的机器都能用全局唯一的同种方法方便地生成它。这是MongoDB 采用ObjectId,而不是其他比较常规的做法(比如自动增加的主键)的主要原因,因为在多个服务器上同步自动增加主键值既费力还费时。MongoDB 从一开始就设计用来作为分布式数据库,处理多个节点是一个核心要求。后面会看到ObjectId 类型在分片环境中要容易生成得多。
ObjectId 使用12 字节的存储空间,每个字节两位十六进制数字,是一个24 位的字符串。由于看起来很长,不少人会觉得难以处理。但关键是要知道这个长长的ObjectId 是实际存储数据的两倍长。
如果快速连续创建多个ObjectId,会发现每次只有最后几位数字有变化。另外,中间的几位数字也会变化(要是在创建的过程中停顿几秒钟)。这是ObjectId 的创建方式导致的。12 字节按照如下方式生成: 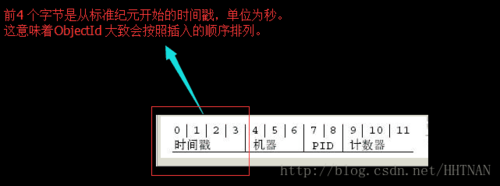
接下来的3 字节是所在主机的唯一标识符。通常是机器主机名的散列值。这样就可以确保不同主机生成不同的ObjectId,不产生冲突。
为了确保在同一台机器上并发的多个进程产生的ObjectId 是唯一的,接下来的两字节来自产生ObjectId 的进程标识符(PID)。
前9 字节保证了同一秒钟不同机器不同进程产生的ObjectId 是唯一的。后3 字节就是一个自动增加的计数器,确保相同进程同一秒产生的ObjectId 也是不一样的。同一秒钟最多允许每个进程拥有256^3(共16777216)个不同ObjectId。
2. 自动生成_id
如果插入文档的时候没有”_id” 键,系统会自动帮你创建一个,如果创建过程中存在字段:”_id”则不会在帮你创建了。通常会在客户端由驱动程序完成。理由如下。
虽然ObjectId 设计成轻量型的,易于生成,但是毕竟生成的时候还是产生开销。在客户端生成体现了MongoDB 的设计理念:能从服务器端转移到驱动程序来做的事,就尽量转移。这种理念背后的原因是,即便是像MongoDB 这样的可扩展数据库,扩展应用层也要比扩展数据库层容易得多。将事务交由客户端来处理,就减轻了数据库扩展的负担。
在客户端生成ObjectId,驱动程序能够提供更加丰富的API。例如,驱动程序可以有自己的insert 方法,可以返回生成的ObjectId,也可以直接将其插入文档。如果驱动程序允许服务器生成ObjectId,那么将需要单独的查询,以确定插入的文档中的”_id” 值。
3.对于系统默认生成_id的检索方式
_id是mongodb自动生成的id,其类型为ObjectId,所以如果需要在python中通过_id查询,就需要转换类型 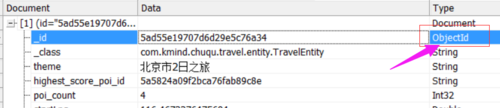
db.travel.find({'_id':ObjectId("5ad55e19707d6d29e5c76a34")})如果时python 下检索则
如果pymongo的版本号小于2.2,使用下面的语句导入ObjectId
from pymongo.objectid import ObjectId
如果pymongo的版本号大于2.2,则使用下面的
from bson.objectid import ObjectId
码如下:
collection.find_one({'_id':ObjectId('50f0d76347f4ec148890ef1e')})mongodb基本操作(对比MYSQL)增删改查
**MongoDB语法与现有关系型数据库SQL语法比较
基本查询
1. 增
db.test.insert({'name':'foobar','age':25})
<==>insert into test ('name','age') values('foobar',25)2. 删
db.test.remove({})
<==> delete * from test
db.test.remove({'age':20})
<==> delete test where age=20
- 聚合函数展示
db.test.remove({'age':{$lt:20}})
<==> delete test where age<20db.test.remove({'age':{$lte:20}})
<==>
delete test where age<=20db.test.remove({'age':{$gt:20}})
<==> delete test where age>20db.test.remove({'age':{$gte:20}})
<==> delete test where age>=20db.test.remove({'age':{$ne:20}})
<==> delete test where age!=20删除单个字段的直通车
3. 改
db.test.update({'name':'foobar'},{$set:{'age':36}})
<==>
update test set age=36 where name='foobar'db.test.update({'name':'foobar'},{$inc:{'age':3}})
<==>
update test set age=age+3 where name='foobar'4. 查
基本查询
db.test.find() <==> select *from test
limit(1)
db.three_province_poi_v9.find().limit(1) <==> select *from test limit 1**MongoDB 同时limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据 db.test.find().skip(10).limit(20) <==> select * from test limit 10,20
where 查询
db.test.find({'name':'foobar'})
<==>
select * from test where name='foobar'db.test.find('this.ID<20',{name:1})
<==>
select name from test whereID<20where count()
db.test.find({'ID':10}).count()
<==>
select count(*) from test where ID=10多条件in
db.test.find({'ID':{$in:[25,35,45]}})
<==>
select * from test where ID in (25,35,45)排序
db.test.find().sort({'ID':-1})
<==>
select * from test order by IDdesc聚合函数:小于
db.test.distinct('name',{'ID':{$lt:20}}) <==>
select distinct(name) from testwhere ID<20修改某个字段的名称
//修改字段名称,把synonymsList表的name_status修改为status
db.getCollection(‘synonymsList’).update({}, {$rename : {“name_status” : “status”}}, false, true)




