
首先关于生成器的那些事:
1.通常的for…in…循环中,in后面是一个数组,这个数组就是一个可迭代对象,类似的还有链表,字符串,文件。它的缺陷是所有数据都在内存中,如果有海量数据的话将会非常耗内存。
它可以是mylist = [1, 2, 3],也可以是mylist = [x*x for x in range(3)]。
*它的缺陷是所有数据都在内存中,如果有海量数据的话将会非常耗内存。
2.生成器是可以迭代的,但只可以读取它一次。因为用的时候才生成。比如 mygenerator = (x*x for x in range(3)),注意这里用到了(),它就不是数组,而上面的例子是[]。
3.生成器(generator)能够迭代的关键是它有一个next()方法,工作原理就是通过重复调用next()方法,直到捕获一个异常。
yield的那些事
1.带有 yield 的函数不再是一个普通函数,而是一个生成器generator,可用于迭代,工作原理同上。
2.yield 是一个类似 return 的关键字,迭代一次遇到yield时就返回yield后面(右边)的值。重点是:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行)开始执行。
3.简要理解:yield就是 return 返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始。
4.带有yield的函数不仅仅只用于for循环中,而且可用于某个函数的参数,只要这个函数的参数允许迭代参数。比如array.extend函数,它的原型是array.extend(iterable)。
python案例:
#!usr/bin/env python#_*_ coding:utf-8 _*_#foo测试yield生成器原理def foo():
yield 1
yield 2
yield 3
yield 4
yield 5res=foo()
print('未加入for 循环时,yield输出是一个generator{}'.format(res))
print('用for将生成器调用')for item in res:
print(item)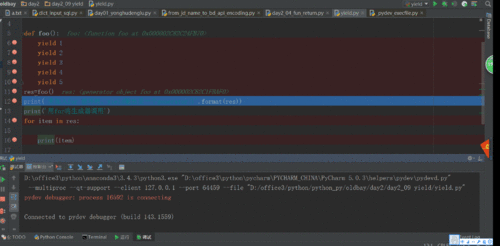
#实现yield,读取文本位置def yieldreadlines():
'''
以下是seek()方法的语法:
fileObject.seek(offset[, whence])
参数:offset -- 这是在文件中,读/写指针的位置。
whence -- 这是可选的,默认为0,这意味着绝对的文件定位,其它的值是1,这意味着寻求相对于当前位置,2表示相对于文件的末尾
'''
#定义seek
seek =0
while True: with open('yieldreadlines.txt','r') as f:
f.seek(seek) #起始位置
data=f.readline() if data: #TRUE
#tell():返回文件读取指针的位置
seek =f.tell() yield data else: return #return 退出当前yieldreadlines函数for item in yieldreadlines():
print(item)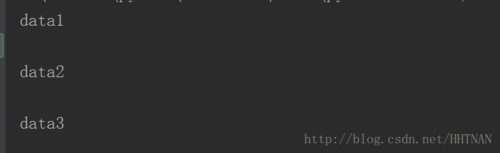
通常yield用在线程池或者程序运行过程中避免阻塞,





