
Python的确挺神的~但不是生来就那么神。
Python是在1991年被创造出来的,但真正开始被广泛使用是Python 2.6以后的事情了。从2012年开始到现在,Python的热度持续累积,成为关注度增长最快的语言。
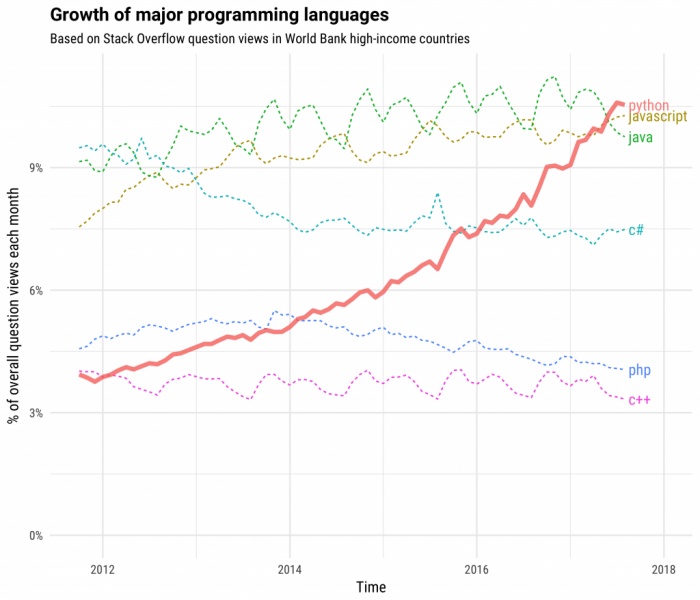
所以说,Python并没有像Golang等语言那么幸运,生来就备受关注;而是因为语言本身的设计特点对生态环境有着极强的适应能力,同时适时抓住了成长机遇,从而厚积薄发。

精妙的设计哲学
早期的Python,在Java、PHP、JS、C++等重重包围下,尽管受众不广,但仍旧得以生存,主要因为Python的设计哲学使其具备了十足的生命力。
忍不住要分享一下精妙的Python之禅(摘自Python官网),它并非出自Python创始人之手,但已被官方认可为编程原则。而精妙之处在于它不仅适用于编程,更适用于人生。原来每一个热爱代码的优秀编程者都是哲学家。
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity.Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than right now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!

带着这种哲学,Python逐渐发展成了一个特别简明友好、容易上手、功能强大的语言,发展过程中,Python抓住了三次飞速发展的机会。
适时抓住成长机遇
第一个机会,Web与敏捷开发
在受到广泛关注之前,Python更多地是作为简单脚本语言,配合一些系统相关工作而被运用(主要是跟Perl抢地盘)。Python开始受到广泛关注,得益于Google的推动。Google或许不是第一家使用Python的公司,但它是第一家大规模使用Python进行Web相关开发的全球著名公司,从而有力地证明了Python能够很好地完成Web开发相关的许多工作。
而此时互联网正开始向快速开发转型,开发速度对于企业,尤其是初创企业而言至关重要,因此Python简洁便利与高效开发的特点吸引了众多企业和组织,同期衍生出来的社区环境又为Python提供了无数优质到可以进行生产级使用的模块和包;对比彼时PHP的模板式开发,Java的庞大繁杂,Ruby的语法新奇多变,Python为中小型企业的快速开发提供了尤为可能的解决方案,从而使得Python开始小有名气。

第二个机会,科学计算
相较于商业开发,科学计算面向更多的是非专业的编程人员,从这个方向上来说,抛开商业化软件不谈,Python的竞争对手也是前有Fortran,后有R、Julia语言的存在,虽然历史积累不如Fortran,抽象形式不及R,现代化和综合性能不如Julia,但是这些却仍然没有妨碍Python在这个领域里大显身手。
历史积累不如Fortran?没关系!借助C接口把Fortran包包裹起来让Python用就好;
抽象形式不及R?没关系!Python语法简单库还多,学习起来也不难,效率还高一丢丢,更重要的是借助这些特点能直接做产品,比R更具市场亲和力;
现代化不如Julia?没关系!Python社区大,要啥包有啥包。

更让人们惊喜的是,借助Python的各种模块和包,能够十分简单地实现之前需要折腾很久的繁杂工作,诸如访问数据库和表格文件,哪怕是在R语言中,仍旧需要从ODBC里一点点拿出数据;而用Python,以Pandas,一句话就能解决数据的读甚至写。
并且,随着计算金融和大数据的兴起,大量程序员开始投入科学计算,相较于Fortran的陈腐、R的浓厚统计数学意味以及Julia的不发达社区,Python自然而然的成了很多人的首选;而经验丰富的程序员又更进一步推动了Python社区的发展,更多优秀的包和模块得到了迅速推广:
矩阵、符号、科学计算?有NumPy、SymPy和SciPy;
统计分析?有Pandas;
可视化?有matplotlib、seaborn;
……
于是,Python很快便在该领域占据了半壁江山。

第三个机会,深度学习
在较早的很长一段时间里,提到机器学习,人们往往会使用C++、Java等作为主要工具。GPGPU的出现使得计算庞杂的机器学习任务开始由CPU向GPU转变,但研究者直接进行GPU编程,在计算复杂的模型时,不仅需要大量心智来分析算法的设计,还不得不投入大量精力解决显卡计算开发中的工程问题,为研究增添了非常大的难度。
随着时间的积累,更多的开源库出现,使得机器学习中主要算法实现抽象成了一个个模块,研究者才得以从繁杂的工程开发中解放出来。此时,代码成了模块的调用和描述,使用诸如C++或Java这样繁杂的工程化语言不再是必要选择,特别是更通用化的深度学习出现,促使研究者需要一种更加易读、易分析的描述性语言(DSL)来解决问题。
而Python因此前在科学计算领域已有广泛应用,加之它能很容易接入现有的C/C++库,以及良好的可读性,成为不少框架的必然选择,如Theano和Caffe。同时,由于AlphaGo亮眼的表现聚焦了众人的注意力,并随后开源了以Python为接口Tensorflow,使得由AI热潮带来的学习者纷纷奔向了Python和Tensorflow。

之后,越来越多的框架都开始提供Python接口——Python能够容易而清晰地描述模型结构,轻松解决计算中的数据输入(无论从硬盘、数据库、网络中的任何一种)问题,简单地实现可视化,并能轻易地设计为Web服务。甚至连使用Lua的Torch都实现了以Python为接口的演进版本PyTorch。至此,Python几乎已经统治了深度学习的模型设计、训练领域。
Python在深度学习上有多神?
正如前文所述,Python极大地减轻了深度学习研究者的心智负担,使之得以将更多的精力集中在模型的设计、改进上。而当深度学习的研究可以集中在对模型结构、对优化算法等方面的研究上,这个领域的进展迅速也就可以被理解了。
不妨看一个简单的例子,此处使用Keras框架中对MNIST(手写数字识别)数据集的深度卷积网络的实现代码:
'''Trains a simple convnet on the MNIST dataset.
Gets to 99.25% test accuracy after 12 epochs
(there is still a lot of margin for parameter tuning).
16 seconds per epoch on a GRID K520 GPU.
'''
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
batch_size = 128
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])让我们详细看看这段不到70行的代码:加载标准数据集不过仅仅5 行,训练部分也就寥寥数行,而其中的模型,更是简单直白:数据顺序地经过若干卷积层(Conv2D)、池化层(MaxPooling2D)、展平(Flatten)和全连接层(Dense)。


这样的一段程序,经过训练,对于手写数字的识别率可以达到99.25%,如果你愿意,也可以为此程序接入微信、网站,或包装成应用程序,一切都只需要简单的几行代码即可完成。
更多Python可以做到的事情请参看你都用 Python 来做什么?

所以你看,Python其实是属于厚积薄发型选手,与其说它神,倒不如说它早就做好了准备,一直在寻找爆发的机会,Python的语言哲学值得认真品读一番。

【python专题推荐】:python数据分析与挖掘。数据分析与挖掘行业火爆,人才稀缺,现在正是入行的最佳时机,慕课网python数据分析与挖掘系列实战课程,助你顺利成为数据分析与挖掘人才。






