声明
本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请在公众号【K哥爬虫】联系作者立即删除!
逆向目标
- 目标网站:
aHR0cHM6Ly9sb2dpbi50YW9iYW8uY29tL2hhdmFuYW9uZS9sb2dpbi9sb2dpbi5odG0/Yml6TmFtZT10YW9iYW8= - 目标 JS:
aHR0cHM6Ly93d3cud2FuZG91amlhLmNvbS9hcHBzLzc3MzUwMTI= - AI 模型:
GPT-5.5
逆向分析
最近主要想测试一下 AI 在 JS 解混淆层面上的强度,所以拿某里的混淆代码完整跑了一遍。经过测试,我用最直白、最简洁、最不绕弯子的话术总结:AI 确实很强,但 token 消耗也很猛。 token 消耗的接受程度:

拿到文件,第一步先判断有没有格式化检测,以免代码还原的没问题,却因为格式化检测导致替换失败,最后误判成还原逻辑有误。
先拿格式化后的 JS 替换测试:
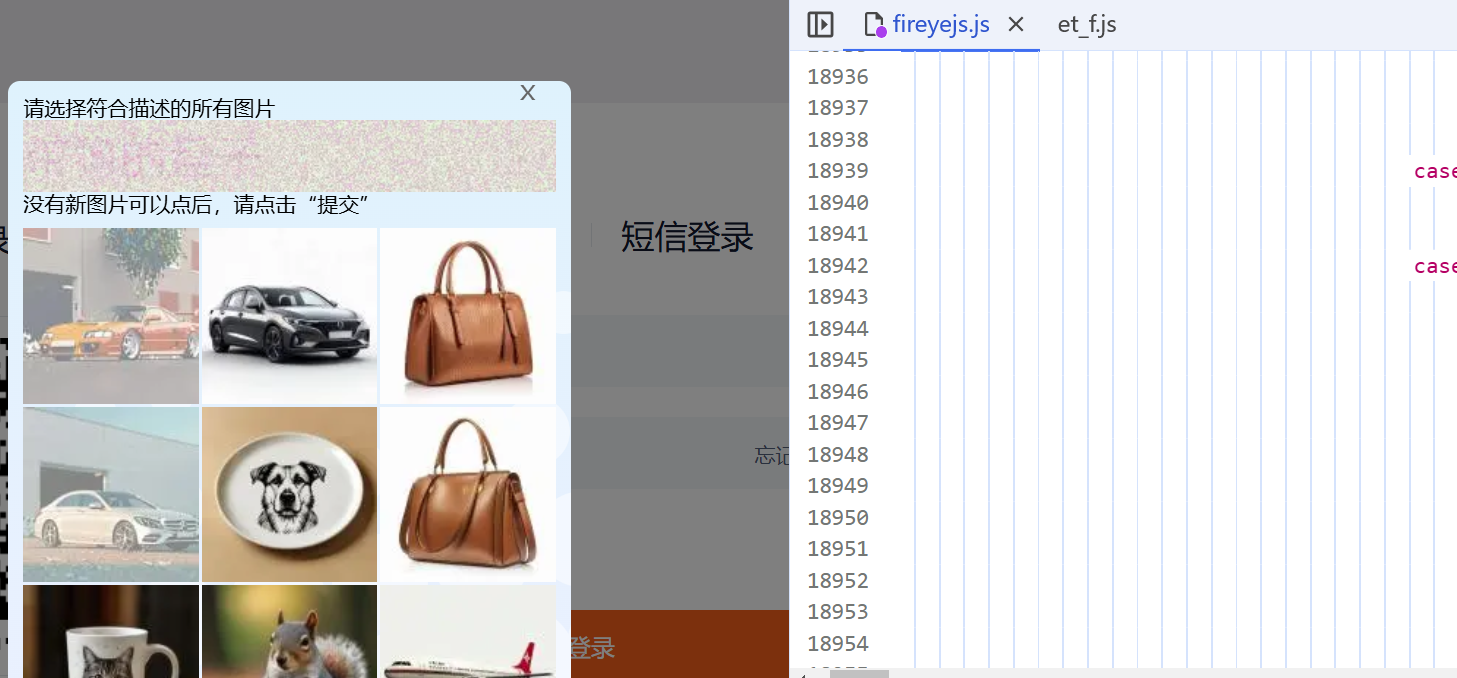
替换失败,页面弹出了九宫格。
这基本说明存在格式化检测,需要先处理这一层。这里主要校验 mr 函数是否被格式化,hook 代码如下:
{
const _toString2 = Function.prototype.toString;
Function.prototype.toString = function toString() {
let res = _toString2.apply(this, arguments);
if (this.name === 'mr') {
return 'function mr(v,z,s,AN,JY,eo)'; // 代码太长,已省略
}
return res;
};
}
替换成功之后,才真正可以开始分析了。
如果你刚接触解混淆,别急着自己硬读,可以先让 AI 帮你把混淆点归纳出来:

根据以往分析某里 JS 的经验,这类代码真正复杂的地方通常不是字符串,也不是变量名,而是控制流:
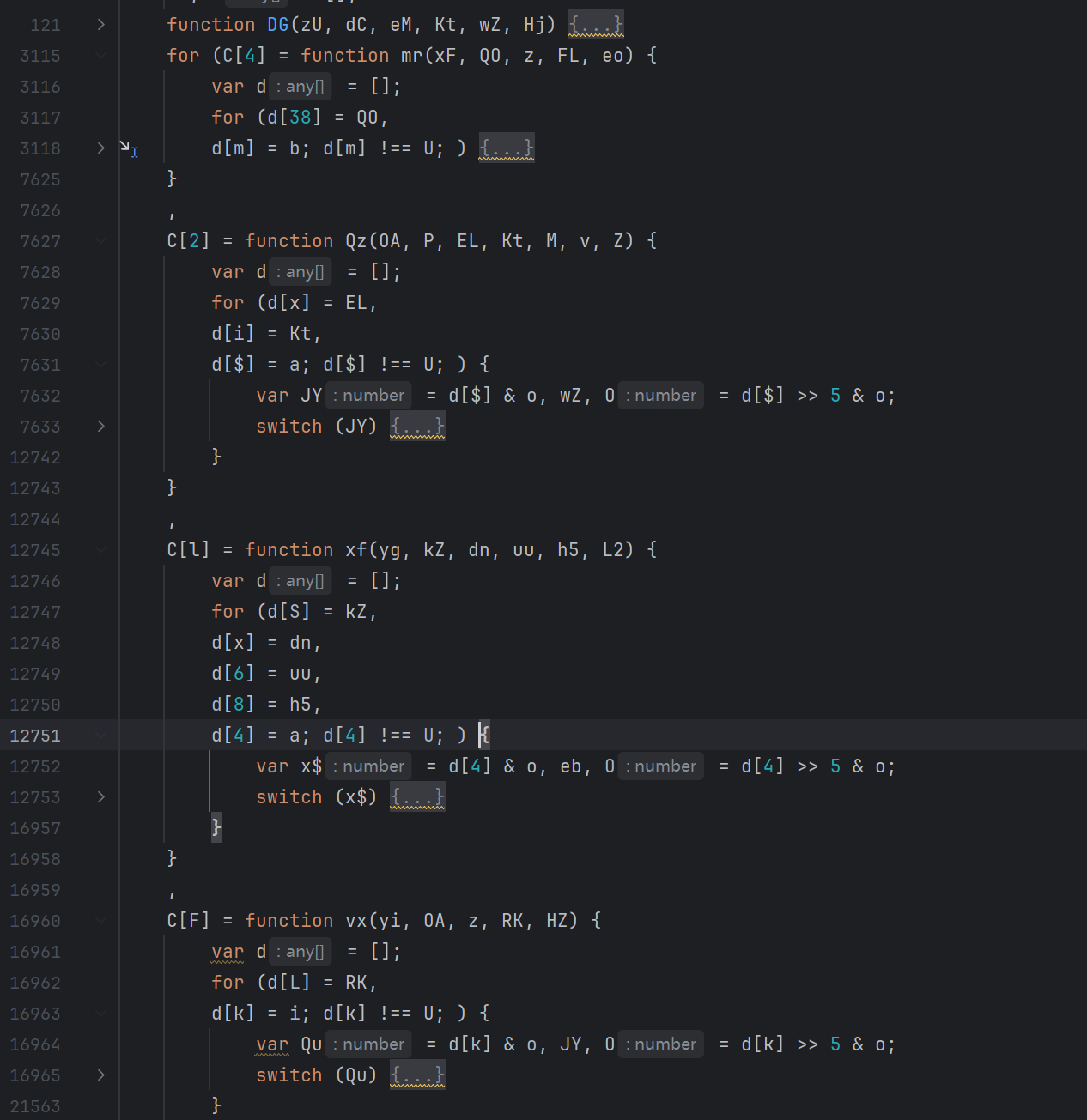
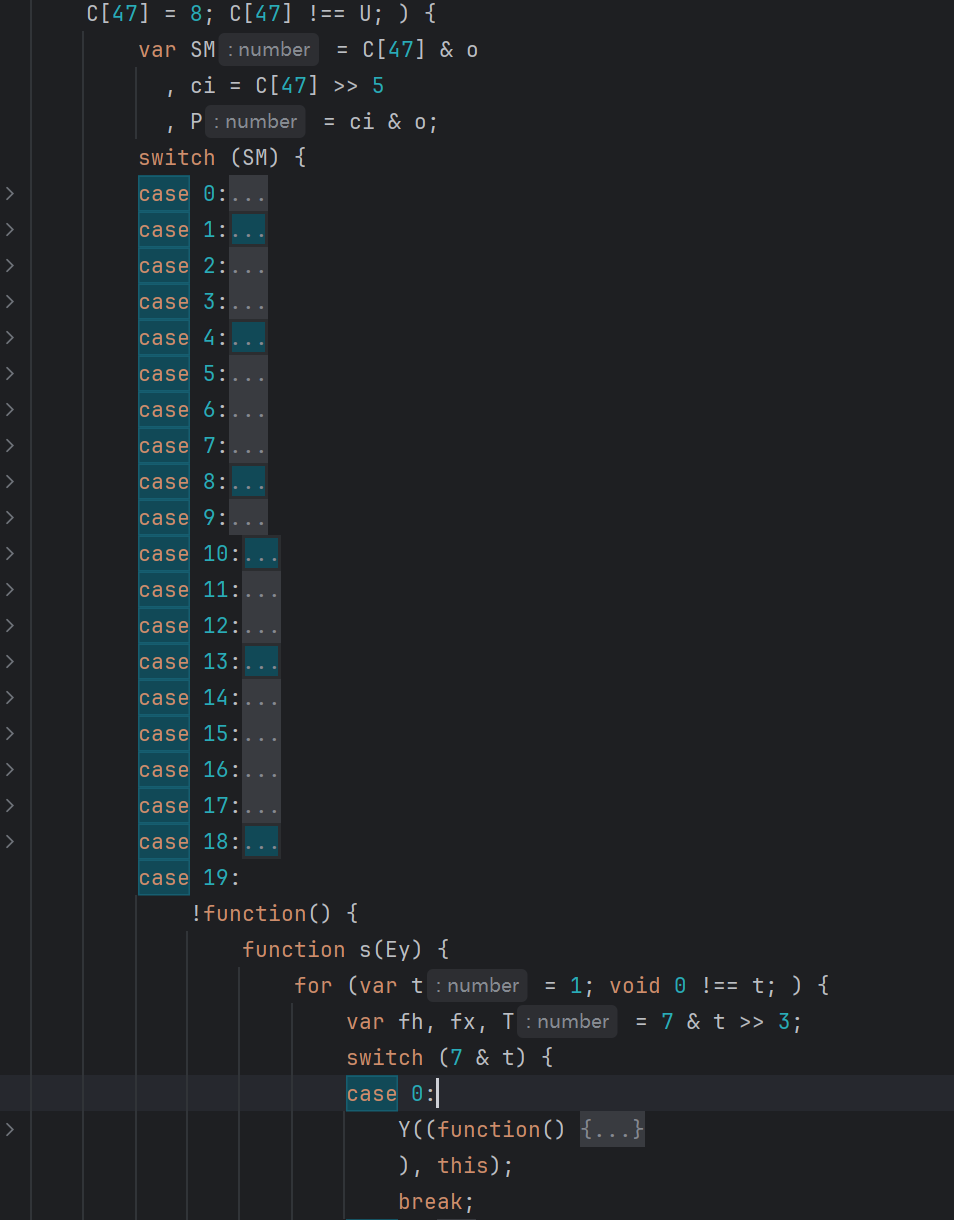
里面有多个控制流,而且还有控制流嵌套。控制流这块不能一上来就硬还原,很多状态跳转被塞进三目表达式、短路表达式和逗号表达式里,不先拆开,后面看状态机会很难受。
所以动业务逻辑之前,要先做一轮预处理:把压在表达式里的赋值、判断、跳转拆成普通语句,让代码先变成能继续处理的形态。
预处理
利用 AI 还原混淆代码,思路往往比工具更重要。有了思路,可以让 AI 生成自己想要的插件,本文不贴完整脚本,重点讲解混淆处理顺序和思路。
预处理阶段先不看业务、不删分支,只做一件事:把控制流外壳拆开。
先把表达式里的判断、赋值、跳转拆开。执行顺序清楚了,后面再看状态机、case 合并和虚假分支。
可以主要按下面这几个大的方向处理:
- 三目表达式、逻辑表达式等转成
if; - 逗号表达式拆成顺序语句;
- 自执行函数去除。
三目表达式、逻辑表达式转 if 语句
真实代码里最常见的,就是这种夹着状态跳转的三目链:
2 == K ? b = 3 : K < 2 ? 0 == K ? b = void 0 : K > 0 && (b = 42 == P ? 2 : X) : 3 == K ? b = 41 == P ? 6 : H : K > 3 && (b = 40 == P ? 4 : x)
这类表达式不要硬读,先把 2 == K 规整成 K == 2,也就是把变量统一移到左边,代码如下:
const _if_change = {
BinaryExpression(path) {
let {node, parentPath} = path;
if (!types.isIfStatement(parentPath)) return;
let {left, right, operator} = node;
if (!types.isNumericLiteral(left) || !types.isIdentifier(right)) return;
let res;
switch (operator) {
case "===":
case "==":
case "!==":
case "!=":
case "&":
res = operator;
break;
case "<":
res = ">";
break;
case "<=":
res = ">=";
break;
case ">":
res = "<";
break;
case ">=":
res = "<=";
break;
default:
throw "符号调用有新情况" + operator;
}
path.replaceWith(types.binaryExpression(res, right, left));
}
}
再把里面的逻辑表达式以及三目表达式展开成 if,展开后,每个 K 的取值走哪一支就清楚了:
if (K == 2) {
b = 3;
} else if (K < 2) {
if (K == 0) {
b = void 0;
} else if (K > 0) {
b = P == 42 ? 2 : X;
}
} else if (K == 3) {
b = P == 41 ? 6 : H;
} else if (K > 3) {
b = P == 40 ? 4 : x;
}
这一步先只展开,不急着合并,等边界清楚后,再收成分派表。
逗号表达式还原
逗号表达式是顺序执行,混淆代码喜欢把几句赋值压成一条,比如下面这几种:
变量定义混淆
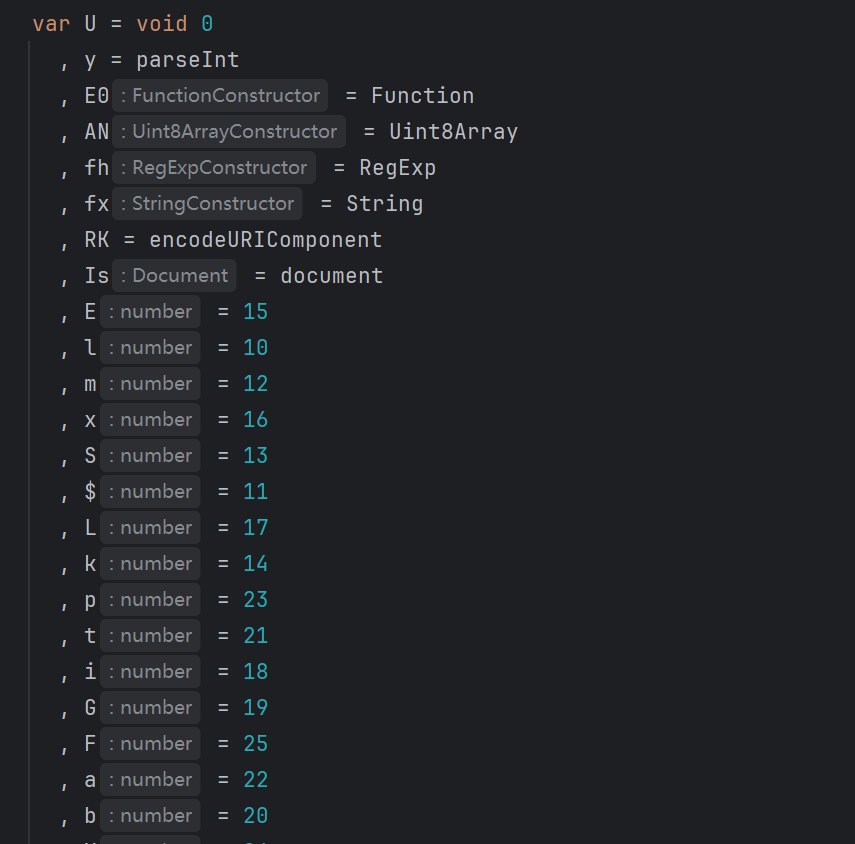
把变量定义放到一起,不方便观察,可以转化成下面这种形式:
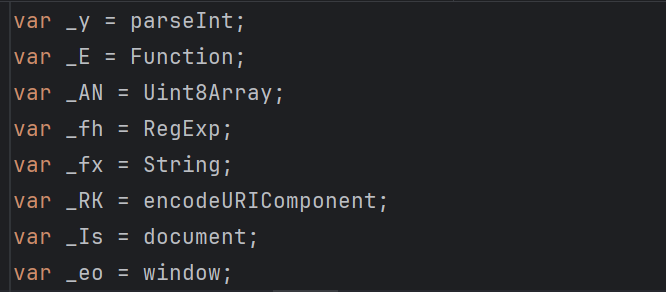
var U = void 0;
var y = parseInt;
var E0 = Function;
循环表达式混淆
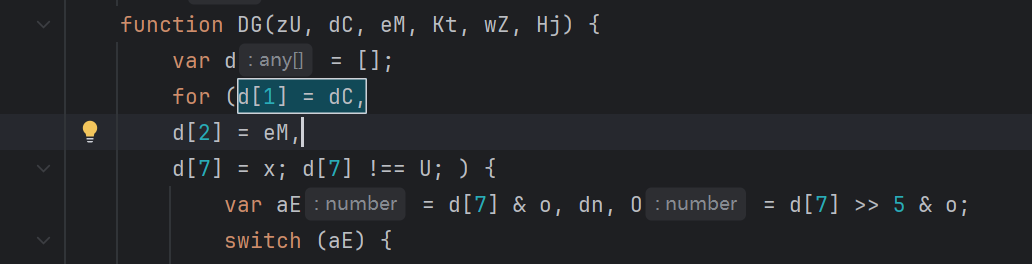
这里就是先赋初值,再进入循环。预处理时拆成顺序语句,方便观察,可以转化成下面这种格式:
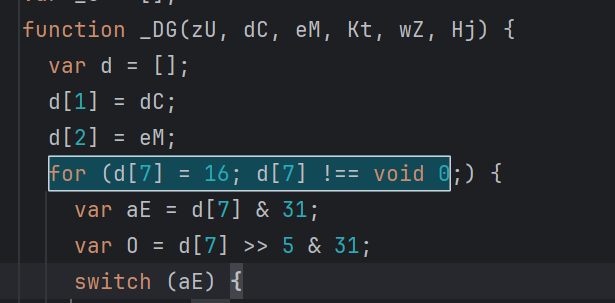
return 表达式混淆
再看这种返回语句里的逗号链:
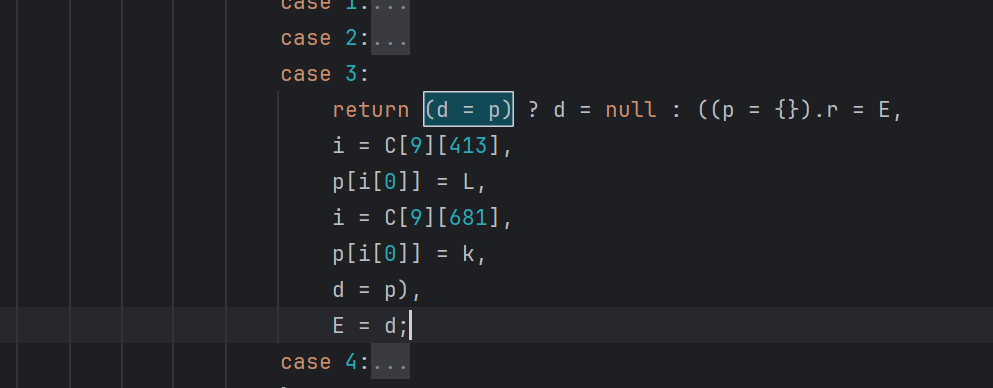
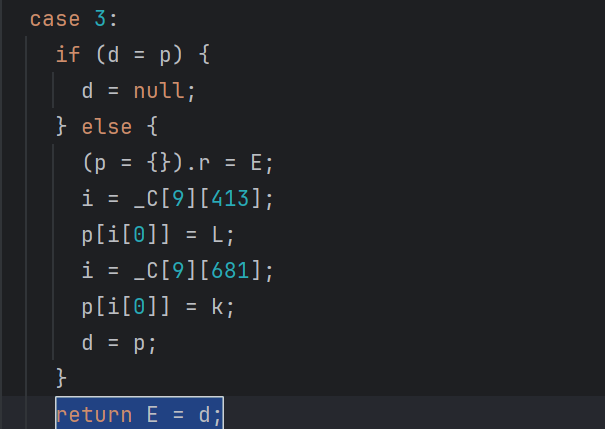
这种把三目表达式转化成 if 之后,再处理逗号表达式,最终还原的代码如下:
自执行函数还原
再来看自执行函数。混淆代码经常把逻辑包进匿名函数,再马上执行,对于这类混淆,一般需要注意作用域的问题,比如:
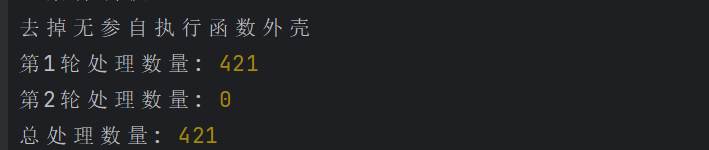
无参自执行函数
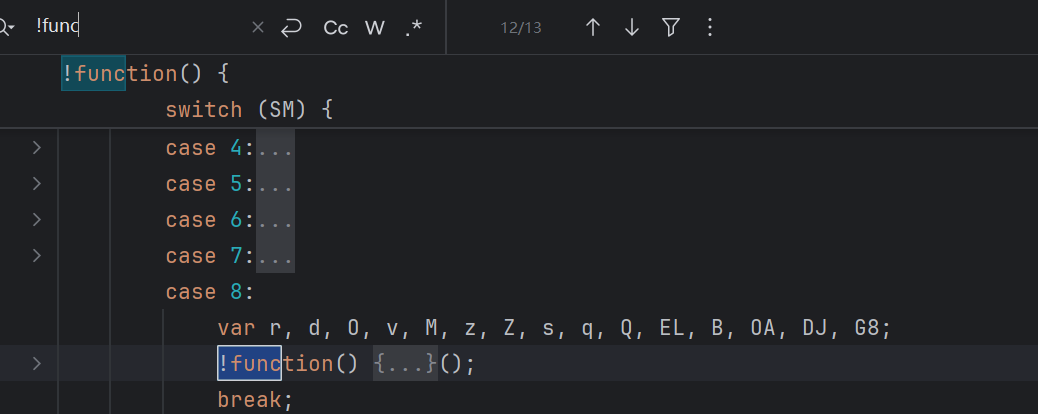
这种无参的一般比较简单,直接去除掉自执行函数壳子,然后注意变量作用域即可。
变体自执行函数
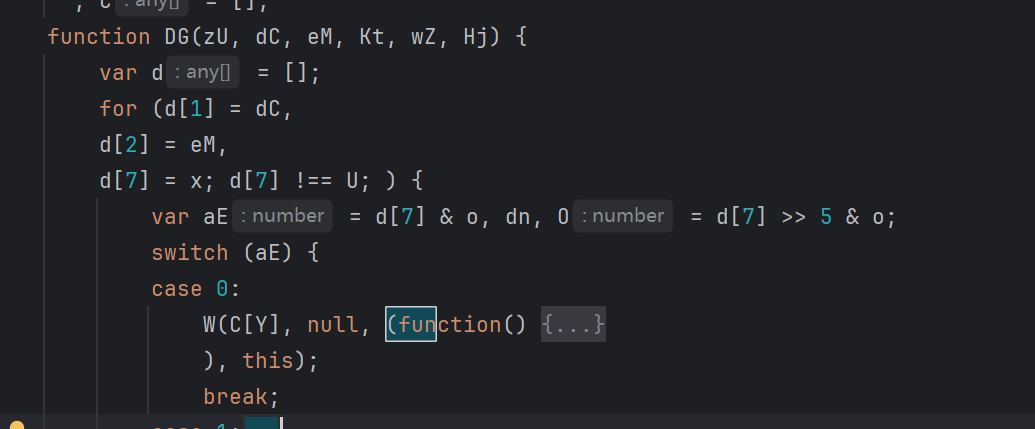
这种可以简单手动分析一下,也可以直接丢给 AI:
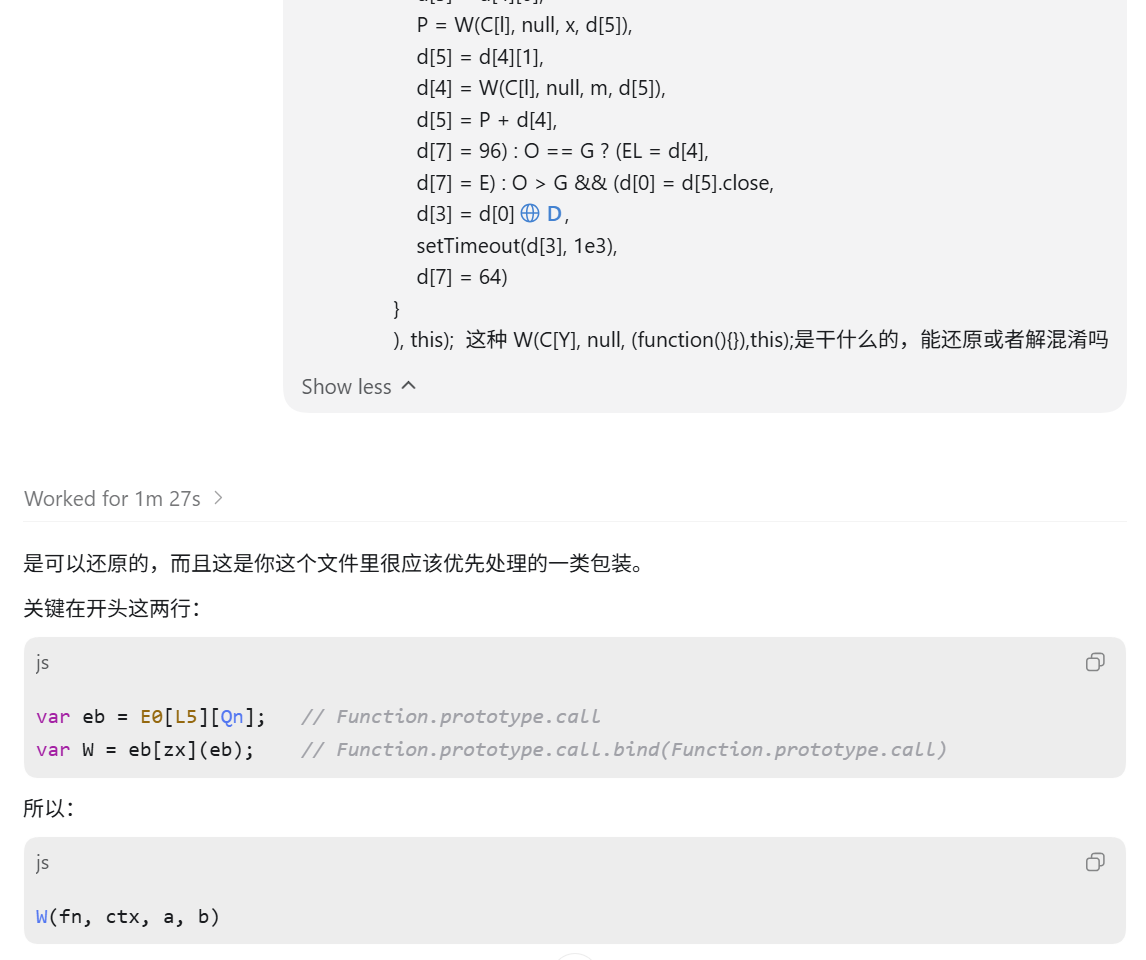
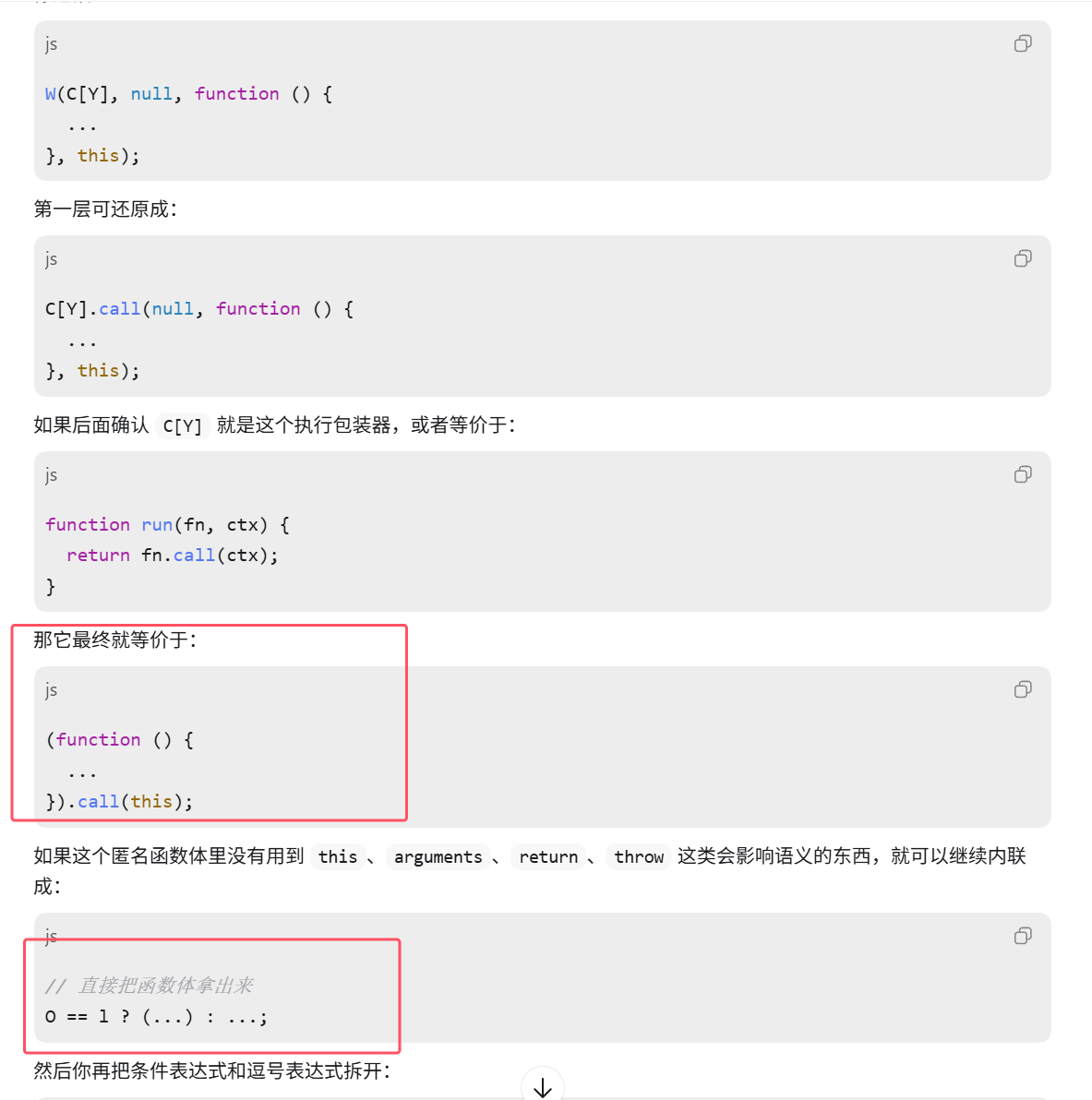
答案很明确,速度也快。这里的 this 指向全局 window,那就可以直接把函数体拿出来,还原结果如下:
if 转化为 switch
三目链拆成 if 后,还要看它是不是业务判断。如果一直围绕同一个变量比较,比如 K == 2、K < 2、K > 3,大概率就是状态分派。
转换方法可以按这几步来:
- 先统一比较方向,把
2 == K改成K == 2; - 找分派变量。这里一直在判断
K,所以switch的变量就是K; - 推
K的范围。这里K = 7 & b >> 3,所以K只能是0-7; - 沿着
if树收集路径条件,把每条路径换成具体 case; - 路径里不是分派变量的条件,比如
P == 42,不要放到case上,保留在 case 内部。
还是看前面的片段,原始形态是这样:
2 == K ? b = 3 : K < 2 ? 0 == K ? b = void 0 : K > 0 && (b = 42 == P ? 2 : X) : 3 == K ? b = 41 == P ? 6 : H : K > 3 && (b = 40 == P ? 4 : x)
经过上面处理后变成这样:
if (K == 2) {
b = 3;
} else {
if (K < 2) {
if (K == 0) {
b = void 0;
} else {
if (K > 0) {
if (P == 42) {
b = 2;
} else {
b = 24;
}
}
}
} else {
if (K == 3) {
if (P == 41) {
b = 6;
} else {
b = 32;
}
} else {
if (K > 3) {
if (P == 40) {
b = 4;
} else {
b = 16;
}
}
}
}
}
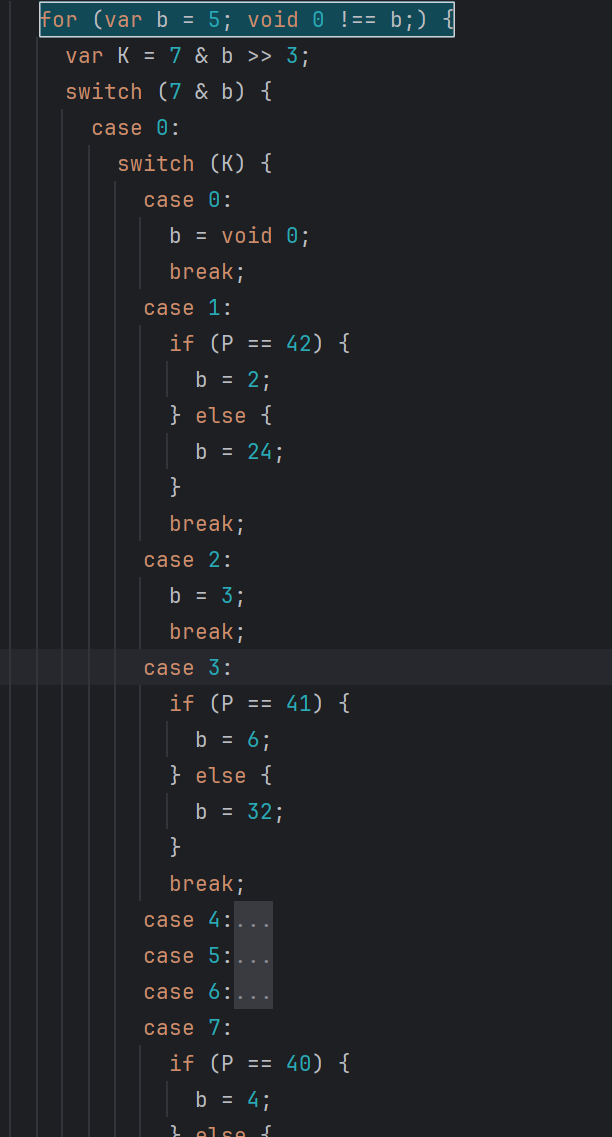
统一比较方向并展开后,就能看出它是在按 K 给 b 赋下一个状态。这里可以收成 switch:
这棵 if 树对应的路径如下:
K == 0 -> b = void 0
K == 1 -> P == 42 ? b = 2 : b = 24
K == 2 -> b = 3
K == 3 -> P == 41 ? b = 6 : b = 32
K in 4..7 -> P == 40 ? b = 4 : b = 16
所以生成出来就是:
switch (K) {
case 0:
b = void 0;
break;
case 1:
if (P == 42) {
b = 2;
} else {
b = 24;
}
break;
case 2:
b = 3;
break;
case 3:
if (P == 41) {
b = 6;
} else {
b = 32;
}
break;
case 4:
case 5:
case 6:
case 7:
if (P == 40) {
b = 4;
} else {
b = 16;
}
break;
}
结果如下:
多层 switch 转化成一重
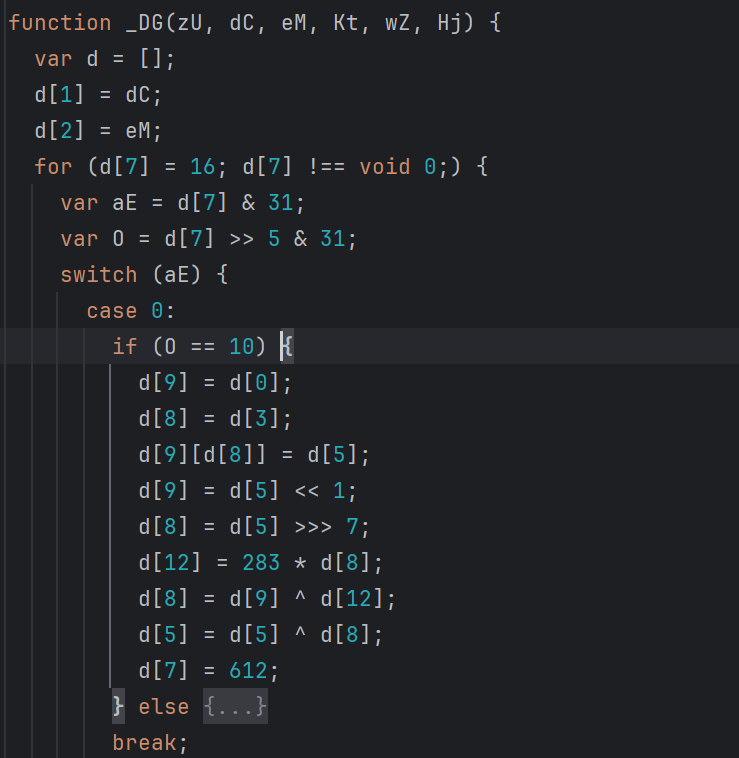
处理完内层分派,再看多层 switch。这类控制流经常把一个状态值拆成低位和高位:
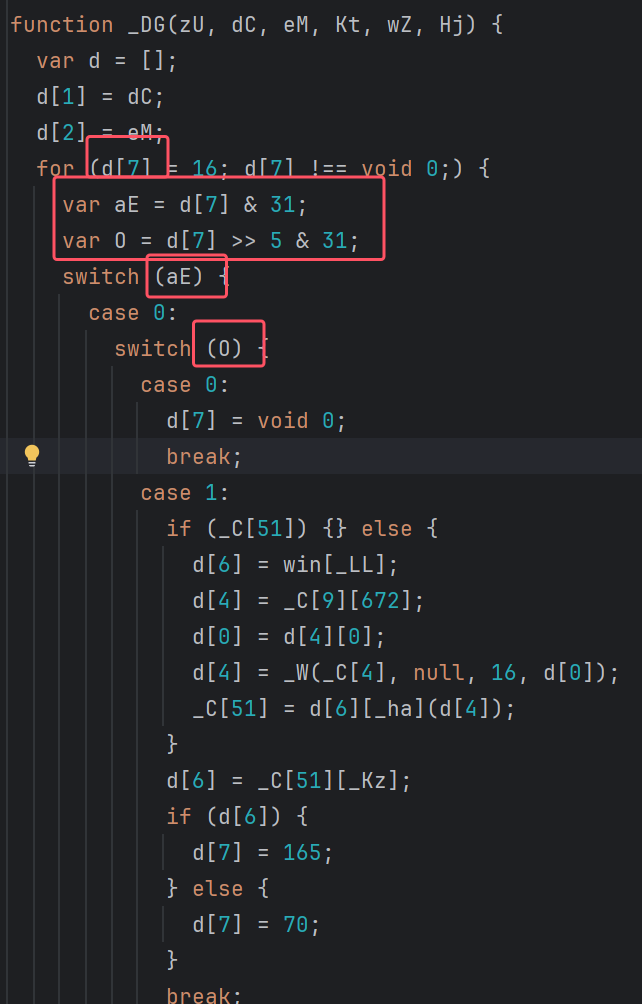
var aE = d[7] & o;
var O = d[7] >> 5 & o;
switch (aE) {
case 0:
d[7] = void
break;
}
这两个变量都来自 d[7]。aE 取低位,O 取高位。只有低位、高位都来自同一个状态变量,并且位移、掩码能确认,才压成一层,原状态值:
low = d[7] & 31
high = d[7] >> 5 & 31
state = low | (high << 5)
合并后,就可以把分支压成一层,结果如下:
合并共享 case
多层 switch 压平后,还会出现共享 case。常见形态是多个 case 走同一段逻辑:
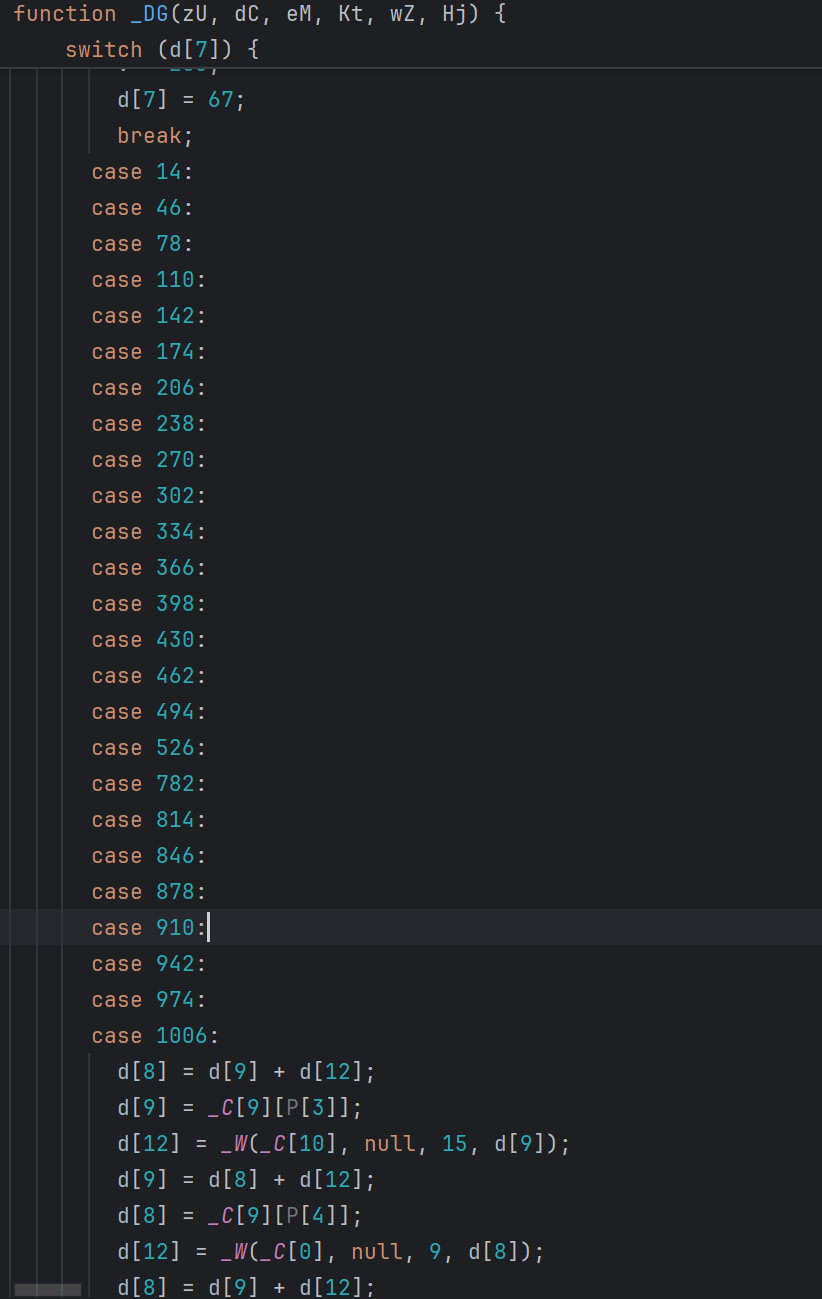
这里的思路是先选一个代表 case,其他入口指向它,比如这里选择 case 14:
46 -> 14
78 -> 14
110 -> 14
这里把 case 转化后,其他 case 里如果还跳到上面的数字,也要一起改成 14,还原结果如下:
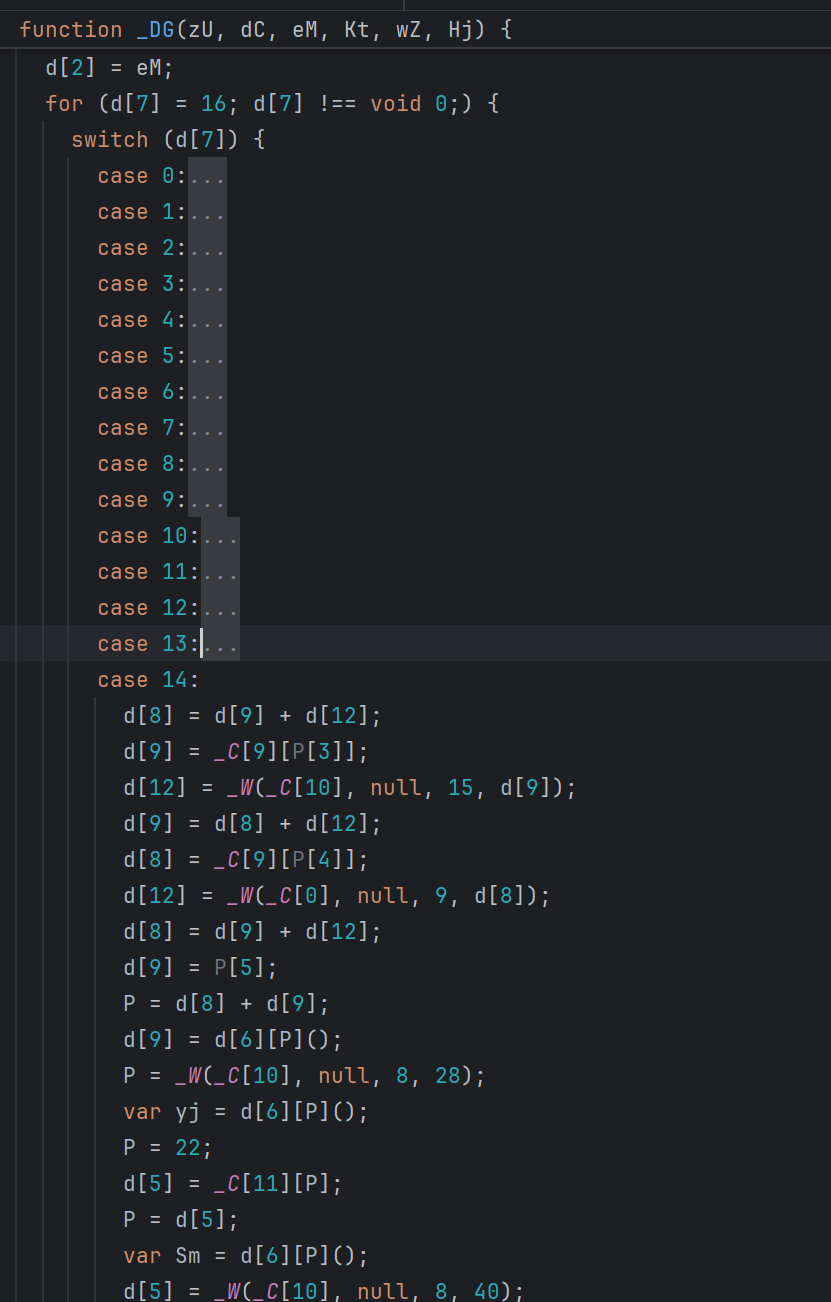
这样预处理基本上完成了,最后可以验证一下,看替换后是否还能出滑块。这里可以手动替换文件看能否通过验证,也可以让 AI 写个简单的验证脚本,每处理一次混淆后,就调用一下,看能否替换成功:

响应正常,就代表这次替换基本成功。当然,也可以再次手动替换文件验证一遍。该预处理的解混淆代码和验证脚本会分享到知识星球,有兴趣的小伙伴自取。
虚假分支去除
预处理做完后,状态机结构已经能看出来。但还是有很多 case 不好分析:
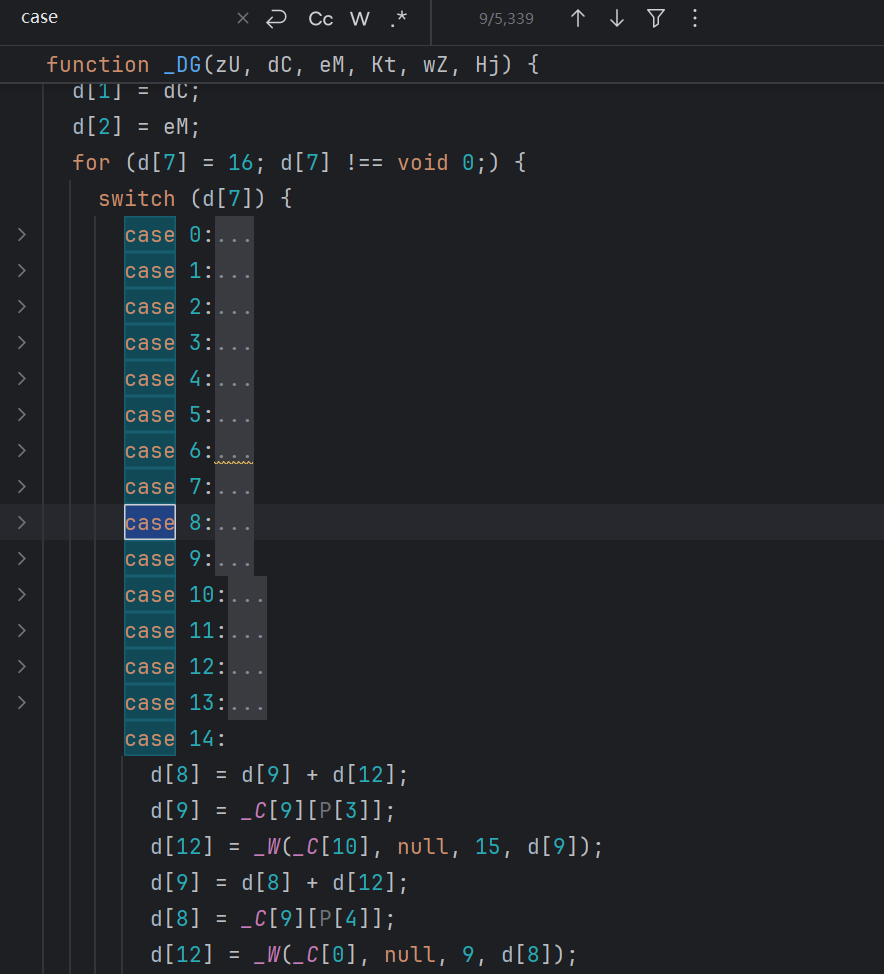
还有 5000 多个,接下来就是处理这些 case 节点。先去除虚假分支,主要分为下面两个步骤:
收集虚假分支
收集的时候主要打两类点:条件分支和单跳转 case。
条件分支
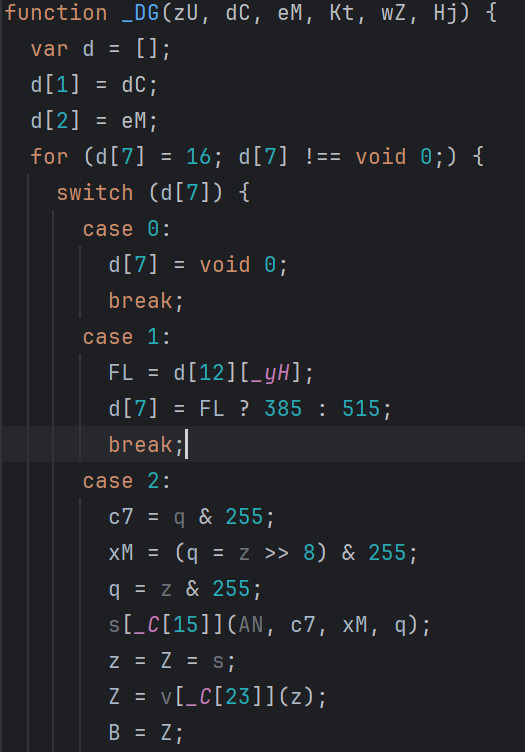
预处理之后会有很多这种状态跳转:
d[7] = FL ? 385 : 515;
FL 决定状态往哪边跳。先把条件提出来,这里声明变量接收这个条件值:
var gfvar_2 = FL;
d[7] = gfvar_2 ? 385 : 515;
运行时记录它出现过哪些结果:
if (window.faker_obj['gfvar_2'] === undefined) {
window.faker_obj['gfvar_2'] = new Set();
}
window.faker_obj['gfvar_2'].add(gfvar_2 ? true : false);
d[7] = gfvar_2 ? 385 : 515;
用 Set 是为了合并结果。只出现一个值,后面可以折叠;出现 [true, false],就不能删。
还有一种条件本身带赋值,比如:
RK = (AN = s < q) ? 2 : 41;
这种不能直接删判断,因为 AN = s < q 有赋值副作用。先保留副作用,再打点:
var gfvar_6 = AN = s < q;
if (window.faker_obj['gfvar_6'] === undefined) {
window.faker_obj['gfvar_6'] = new Set();
}
window.faker_obj['gfvar_6'].add(gfvar_6 ? true : false);
RK = gfvar_6 ? 2 : 41;
单跳转 case
有些 case 就是假分支,根本就不会执行:
case 0:
d[7] = void 0;
break;
这种 case 可以加一个命中标记:
if (window.faker_obj['__case_hit__0__d_7___0'] === undefined) {
window.faker_obj['__case_hit__0__d_7___0'] = new Set();
}
window.faker_obj['__case_hit__0__d_7___0'].add(true);
跑完后,就能知道哪些 case 命中过。
采集出来的数据大概是这种:
{
"gfvar_1603": [false],
"gfvar_1604": [true, false],
"__case_hit__2283__m__8": [true]
}
单次采集不够,多跑几种场景,结果做并集,不要覆盖。比如 A 场景是 [false],B 场景是 [true],合并后就是 [false, true],不能删。
加入代码的同时不要忘了在上面定义:
window.faker_obj = {};
最终执行样例如下:
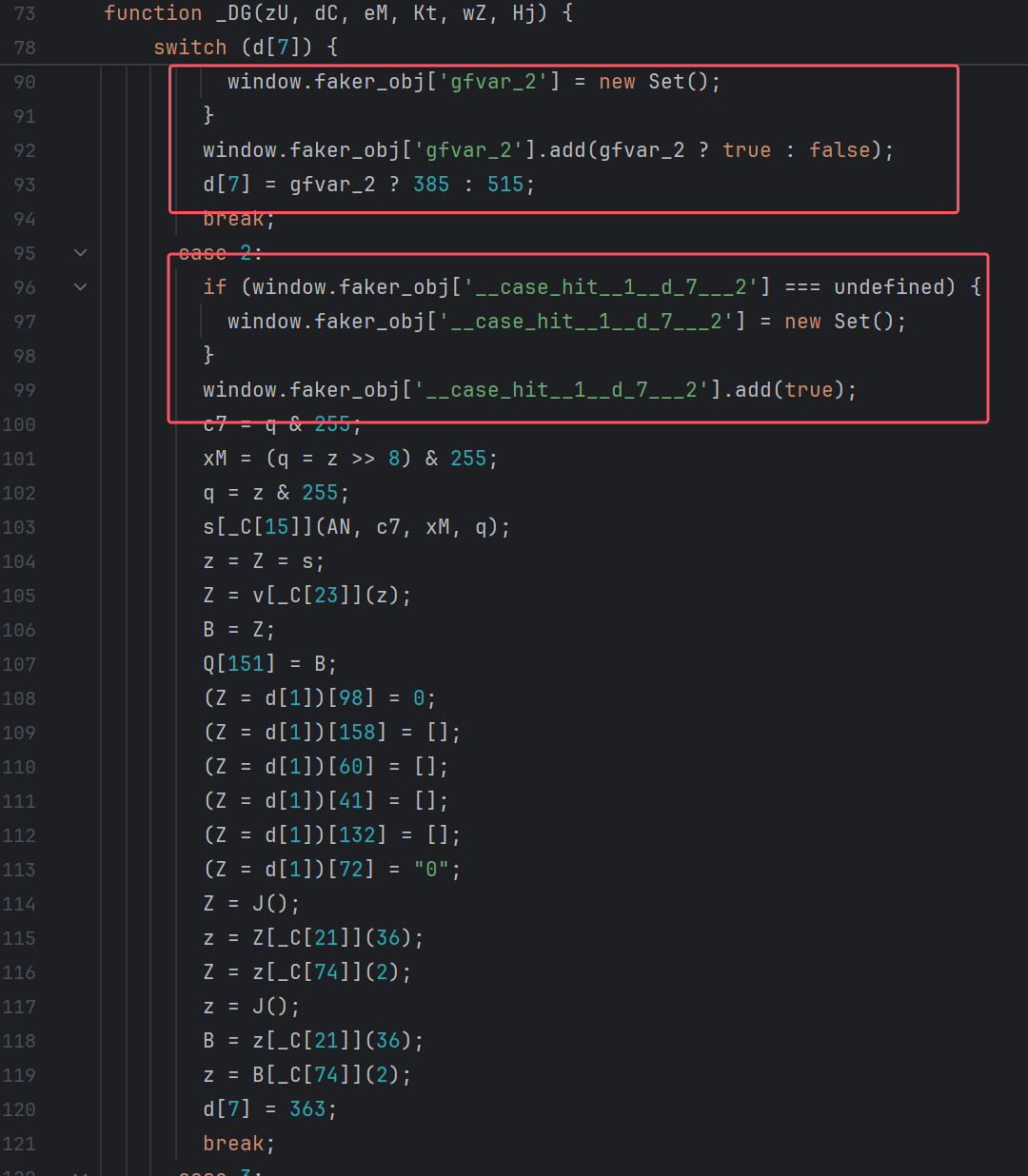
去除虚假分支
删除阶段只处理证据明确的分支,上面从浏览器收集的结果如下:
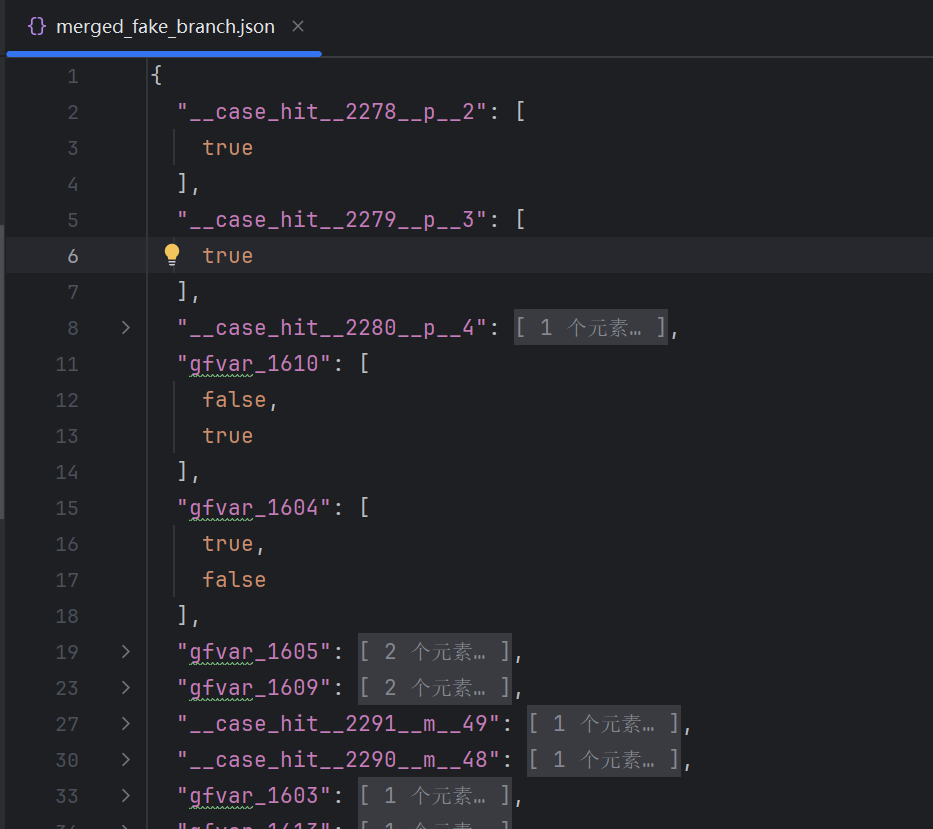
根据这个 json 文件分析,主要看以下几种情况:
单一结果
比如采集结果里只有:
{
"gfvar_1608": [false]
}
那这种代码:
d[7] = gfvar_1608 ? 640 : 70;
就可以折叠成:
d[7] = 70;
如果是 if 语句也是一样:
if (gfvar_1608) {
d[7] = 640;
} else {
d[7] = 70;
}
保留 else,删除 if 那支。反过来,只有 [true] 就保留 true 分支。
单跳转 case
第二种是没有命中过的单跳转 case,比如:
case 12:
d[7] = 480;
break;
没有 __case_hit__ 记录,只能作为删除候选。还要看有没有其他 case 跳到它。只要存在 d[7] = 12 这种入口,就不能直接删。
所以删除单跳转 case 的条件至少要满足两点:
- 当前采集结果里没有命中过这个 case。
- 没有其他状态跳转会进入这个 case。
清理插桩代码
前面加进去的这些东西,最终都不能留:
window.faker_obj = {};
window.faker_obj['gfvar_2'].add(gfvar_2 ? true : false);
window.faker_obj['__case_hit__0__d_7___0'].add(true);
gfvar_* 临时变量也要清理。但不能粗暴删,要看初始化有没有副作用。
比如这种:
var gfvar_6 = AN = s < q;
如果 gfvar_6 后面不用了,也不能整句删。AN = s < q 要保留:
AN = s < q;
虚假分支是在删代码,证明不会走的直接删;证明不了的可以先留着,还原后结果如下:
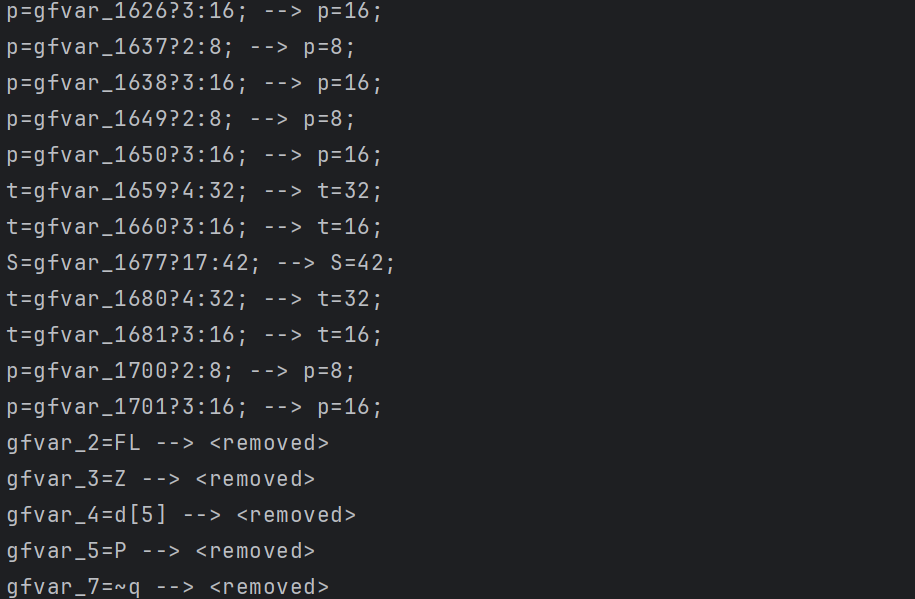
很明显,case 变少了,说明这里有很多垃圾 case 代码。
case 合并
虚假分支删完后,代码会少很多。但剩下的 case 里,还有不少只是中转块。
case 合并不是按编号删 case,而是收缩合并状态图。没有思路的小伙伴可以参考蔡老板的节点算法合并,再让 AI 按这个逻辑进行还原处理,主要还原下面几种结构:
单线 case 拼接
case 合并里最常见的不是 “直接删除”,而是 “把下一个 case 拼到当前 case 后面”。
比如这段:
case 456:
d[6] = [];
d[6][_C[8]](585, 205, 386, 704);
_C[9][40] = d[6];
d[7] = 648;
break;
它的尾部是 d[7] = 648,所以状态边是:
456 -> 648
再看 648:
case 648:
d[6] = Kt[_C[37]];
d[4] = _C[9][40];
d[0] = d[4][0];
d[3] = _W(_C[10], null, 12, d[0]);
// ...
EL = d[6];
d[7] = 15;
break;
它又会继续跳到 15:
456 -> 648 -> 15
这时候不能把 456 直接改成 648,也不能删掉 456,因为 456 里面有有效副作用:
_C[9][40] = d[6];
正确的合并方向是把 648 的内容接到 456 后面,形成这种中间形态:
case 456:
d[6] = [];
d[6][_C[8]](585, 205, 386, 704);
_C[9][40] = d[6];
d[6] = Kt[_C[37]];
d[4] = _C[9][40];
d[0] = d[4][0];
d[3] = _W(_C[10], null, 12, d[0]);
// 中间逻辑省略
EL = d[6];
d[7] = 15;
break;
这样 456 -> 648 -> 15 就被压成了 456 -> 15。
这里有个限制:只有 648 的前驱只有一个时,才能删原来的 case 648。如果还有别的 case 会跳到 648,就先保留,不能直接删。
所以脚本里必须先统计前驱数量,大概就是:
648 的前驱 = 有多少地方写了 d[7] = 648
如果前驱数量是 1,合并完可以删除目标 case;如果大于 1,说明它是共享节点,删了就会断掉其他入口。
条件分派收成 if
再看条件分派,真实代码里有这种:
var _gf_branch125 = _gf_branch99;
if (!_gf_branch125) {
d[11] = 772;
d[5] = _C[9][784];
d[20] = d[27];
d[21] = _C[9][d[5][0]];
d[22] = _W(_C[10], null, 15, d[21]);
d[21] = d[5][1];
d[7] = d[22] + d[21];
d[21] = d[5][2];
d[5] = _W(_C[0], null, 8, d[21]);
d[21] = d[7] + d[5];
d[5] = d[20] === d[21];
if (!d[5]) {
d[20] = _W(_C[0], null, 17, 86);
d[5] = d[27] === d[20];
}
}
d[11] = _gf_branch125 ? 212 : 450;
break;
这一段的状态边是:
_gf_branch125 == true -> 212
_gf_branch125 == false -> 450
然后看 450:
case 450:
d[20] = d[5];
if (!d[20]) {
d[20] = "blur" === d[27];
}
d[5] = d[20];
if (!d[5]) {
d[20] = _W(_C[0], null, 17, 44);
d[5] = d[27] === d[20];
}
d[20] = d[5];
d[11] = d[20] ? 10 : 707;
break;
这就能继续收缩:
false -> 450 -> 10 / 707
合并后的中间形态可以变成:
var _gf_branch125 = _gf_branch99;
if (!_gf_branch125) {
d[11] = 772;
d[5] = _C[9][784];
d[20] = d[27];
// 原来进入 450 之前的逻辑
d[20] = d[5];
if (!d[20]) {
d[20] = "blur" === d[27];
}
d[5] = d[20];
if (!d[5]) {
d[20] = _W(_C[0], null, 17, 44);
d[5] = d[27] === d[20];
}
d[20] = d[5];
}
d[11] = _gf_branch125 ? 212 : d[20] ? 10 : 707;
break;
然后再把最后的三目展开成更正常的 if:
if (_gf_branch125) {
d[11] = 212;
} else if (d[20]) {
d[11] = 10;
} else {
d[11] = 707;
}
这里有两个细节:
-
_gf_branch125已经是缓存变量了,直接复用就行。如果条件不是缓存变量,而是函数调用、赋值表达式、成员访问链,合并前最好先生成临时变量,避免条件被执行两次。 -
450能不能删,还是看前驱数量。如果除了当前这个分支,还有别的地方会跳到450,那就不能删原 case。
终止分支收成 if-return
有些目标 case 不是继续跳,而是直接 return。这种合并完,可读性提升很明显。
比如这种结构:
var _gf_branch8 = d[4];
if (_gf_branch8) {
d[7] = 268;
d[6] = _W(_C[0], null, 17, 85);
_W(d[2], null, d[6]);
}
if (_gf_branch8) {
return EL;
}
它本质上已经不是状态跳转了,而是普通的提前返回:
if (_gf_branch8) {
d[6] = _W(_C[0], null, 17, 85);
_W(d[2], null, d[6]);
return EL;
}
不能为了好看随便移动 return。目标分支没有其他入口,也没有跨层 break、continue、try/finally,才适合收成 if-return。
自循环 case 还原成 while
还有一种比较关键的形态,是尾部跳回自己,比如:
case 35:
d[3] = d[1][_C[16]];
d[5] = d[0] < d[3];
var _gf_branch = d[5];
if (_gf_branch) {
d[7] = 455;
d[3] = d[1][d[0]];
d[5] = d[3] < 128;
}
var _gf_branch2 = _gf_branch;
if (_gf_branch2) {
d[7] = 449;
d[6] = d[3];
d[0] = d[0] + 1;
}
var _gf_branch3 = _gf_branch2;
if (!_gf_branch3) {
d[7] = 264;
d[6] = d[4][_C[31]]("");
EL = d[6];
}
if (!_gf_branch3) {
return EL;
}
d[3] = _fx[_vx](d[6]);
d[4][_C[15]](d[3]);
d[7] = 35;
break;
这里最后又回到 35:
35 -> 35
这就不是普通中转,而是循环。前面的 _gf_branch、_gf_branch2、_gf_branch3 只是混淆器拆出来的条件缓存。
这种结构还原后,更像正常的 while:
while (true) {
d[3] = d[1][_C[16]];
d[5] = d[0] < d[3];
var _gf_branch = d[5];
if (!_gf_branch) {
d[6] = d[4][_C[31]]("");
EL = d[6];
return EL;
}
d[3] = d[1][d[0]];
d[6] = d[3];
d[0] = d[0] + 1;
d[3] = _fx[_vx](d[6]);
d[4][_C[15]](d[3]);
}
实际还原后可以看到这种形态:
while (true) {
if (J) {
v++;
}
J = 1;
s = v;
q = Q["length"];
var _gf_branch1 = AN = s < q;
if (!_gf_branch1) {
break;
}
s = Q["charCodeAt"](v);
q = 112 ^ s;
s = B;
AN = _fx["fromCharCode"](q);
B = s + AN;
}
这一步的判断也要保守。能收成 while,至少要满足以下几点:
- case 尾部跳回自己;
- 正分支是循环体;
- 负分支是退出逻辑;
- 循环体里没有不安全的
break/continue; - 退出逻辑最后是
return、throw或明确终止;
满足这些,再把自跳 case 收成 while (true),里面用 break 或 return 退出。
拆掉 switch 壳
前面几步做完之后,有些 for + switch 壳已经只剩很少的状态了,这时才考虑拆壳。
比如这种壳:
for (d[7] = 16; d[7] !== void 0;) {
switch (d[7]) {
case 16:
// 初始化
d[7] = 69;
break;
case 69:
// 真实逻辑
d[7] = 15;
break;
case 15:
return EL;
}
}
如果已经能确定只有一条执行链,就可以把它拆成顺序代码。比如:
16 -> 69 -> 15 -> return
按顺序展开,最终还原如下:
还原到这里,case 还是有 200 多个。某里新版 JS 恶心的点就在这里:有些入口不是固定 case,而是通过参数动态选出来的:
d[7] = [69, 43, 417, 44, 160, 587, 451, 553, 173, 524, 97, 456, 387, 521, 393, 257, 74, 519][zU - 0] || 15;

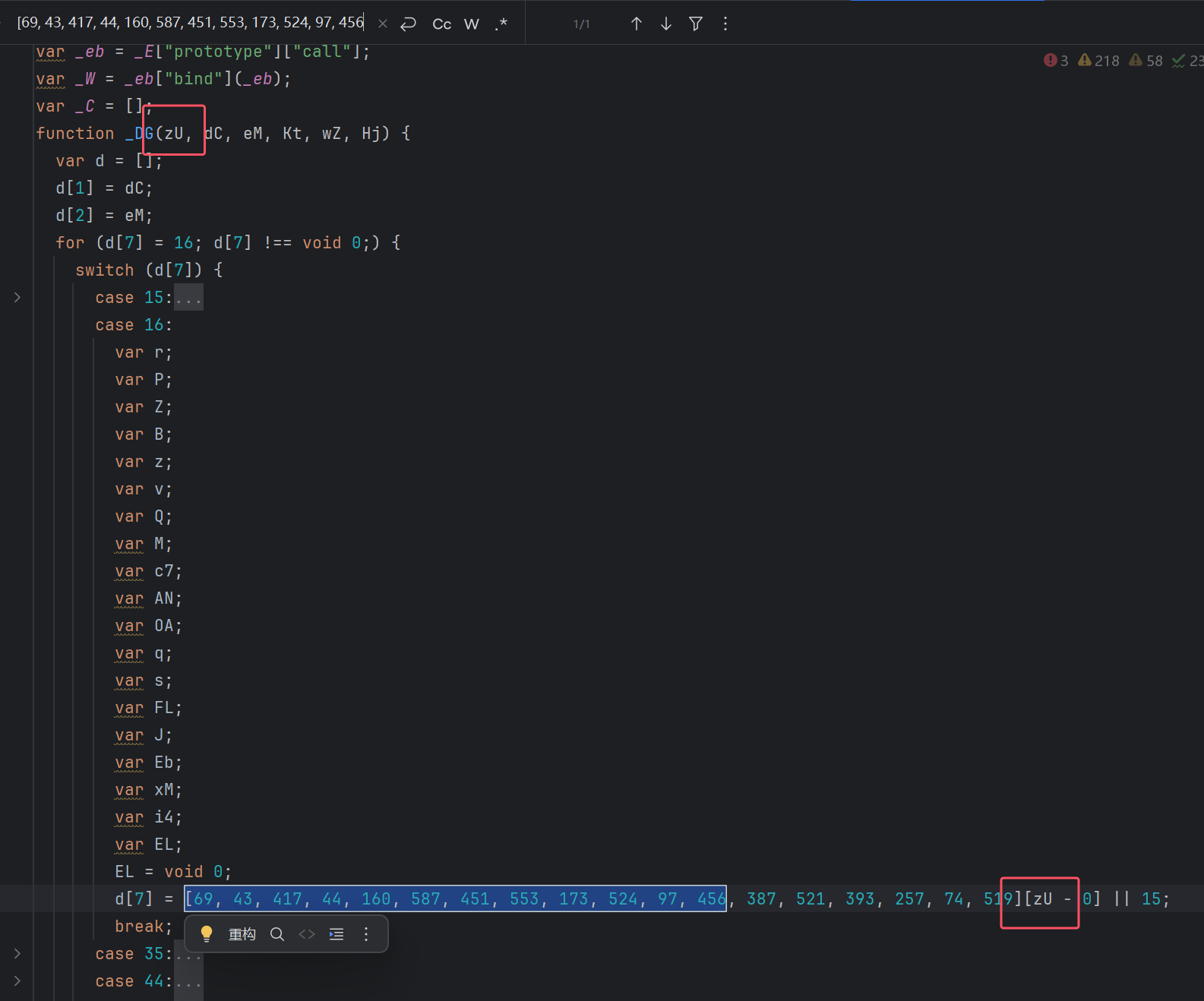
也就是说,入口不是固定一个 case,而是由 zU 选出多个入口,再走不同分支。对于这种,也不用强求全部拆干净,这不影响后面的字符串还原和业务分析。
字符串还原
固定槽位先还原
最容易处理的是固定槽位。比如代码里会大量出现这种:
d[6][_C[8]](0, 2, 1);
d[6] = d[1][_C[16]];
v = d[2][_C[72]];
而 _C 的定义里面有很多固定值:
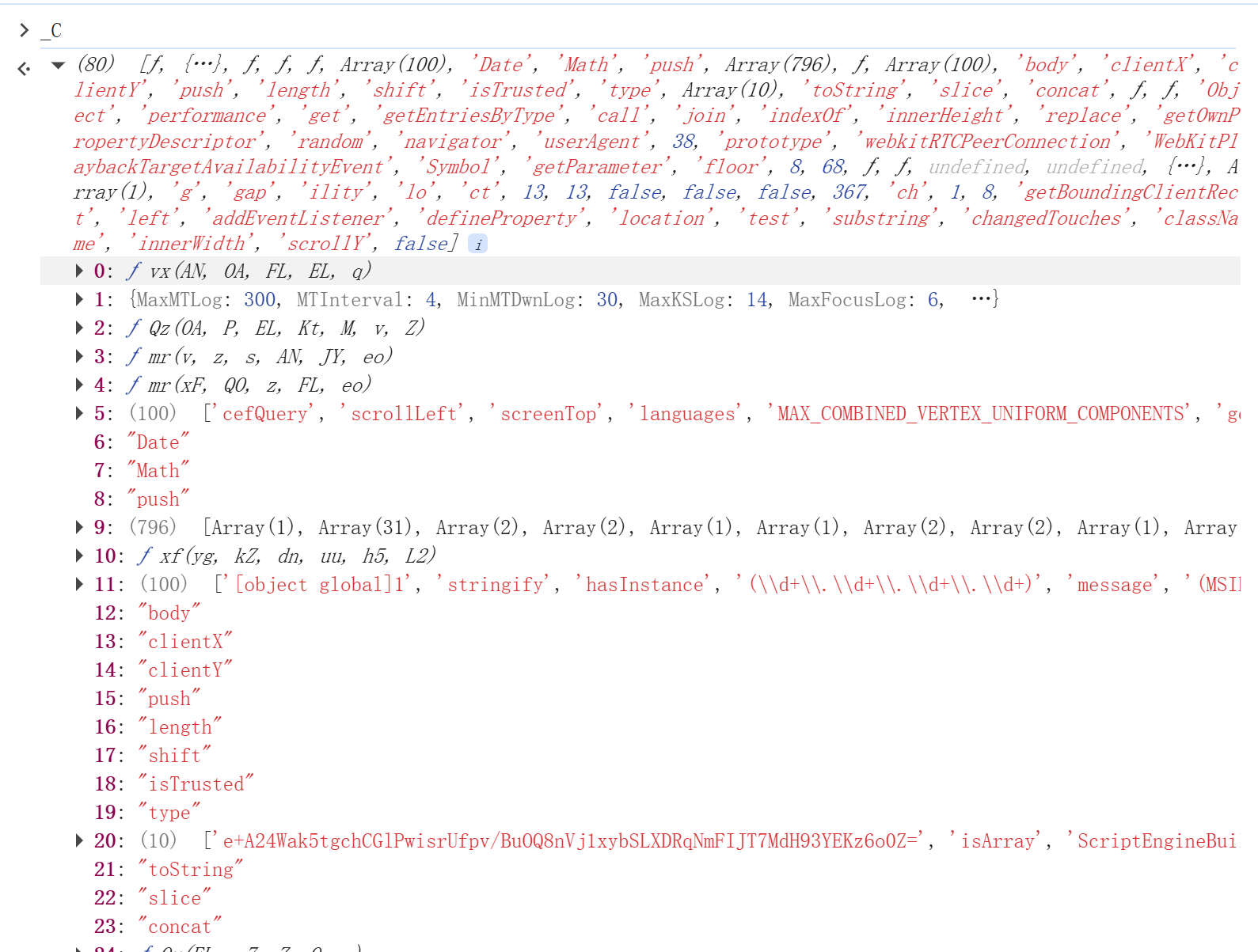
比如 _C[8]、_C[16]、_C[72] 都是固定值,就可以进行还原:
d[6]["push"](0, 2, 1);
d[6] = d[1]["length"];
v = d[2]["location"];
不是所有 _C[index] 都能直接替换。只替换槽位稳定,或者改写值能静态确认的。可以让 AI 写一个判断哪些槽位能还原的函数:
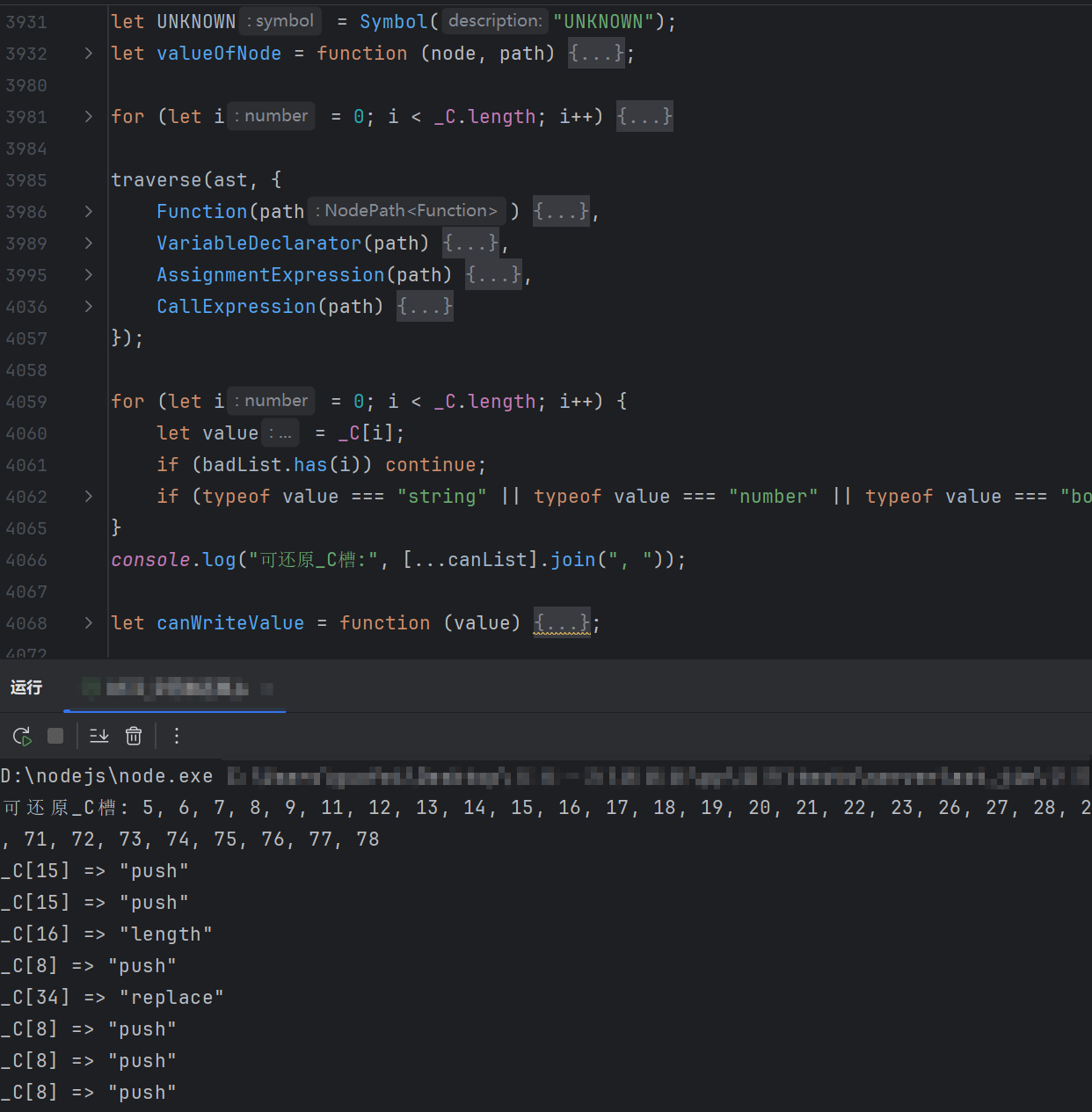
先把固定槽位替换掉,算不出来的先不替换。比如 _C[9],就需要继续动态分析。
还原 _C[9] 递归字符串表
_C[9] 更麻烦,它不是普通一维表,而是字符串片段和数字引用混在一起。
比如还原前能看到这种:
_C[9][253] = ["_f"];
_C[9][192] = ["."];
(v = [])[_C[8]](5, "UM");
_C[9][624] = v;
v = d[2][_C[72]];
_uu = v[_Qz];
v = _C[9][192];
J = v[0];
v = _uu["split"](J);
J = v[_C[16]];
这里有几层混淆:
_C[8]实际是"push";_C[72]实际是"location";_C[16]实际是"length";_C[9][192]实际是".";_Qz这种变量又可能指向"hostname"。
还原之后会清楚很多:
_C[9][253] = ["_f"];
_C[9][192] = ["."];
_C[9][624] = [5, "UM"];
d[1][92] = false;
v = new d[2]["Date"]();
d[1][66] = +v;
v = d[2]["location"];
_uu = v["hostname"];
J = ".";
v = _uu["split"](J);
J = v["length"];
再看一个更明显的例子:
_C[9][245] = ["y_"];
(v = [])[_C[8]](344, "bx", 253, 245, "g", 245, 196);
_C[9][480] = v;
v = _C[9][480];
s = v[0];
q = "__";
s = v[1];
AN = q + s;
s = v[2];
q = "_f";
s = AN + q;
q = v[3];
AN = "y_";
q = s + AN;
s = v[4];
AN = q + s;
s = _C[9][v[5]];
q = "y_";
s = AN + q;
q = v[6];
v = "cl";
q = s + v;
v = d[2][q];
_C[9][480] 里既有数字,又有字符串,数字还要继续回 _C[9] 取值,最后是在拼属性名:
_C[9][245] = ["y_"];
_C[9][480] = [344, "bx", 253, 245, "g", 245, 196];
AN = "__bx_fy_g";
s = "__bx_fy_gy_";
q = "__bx_fy_gy_cl";
v = d[2]["__bx_fy_gy_cl"];
关键是递归解析:
字符串片段 -> 直接拼
数字片段 -> 去 _C[9][数字] 继续取
数组 -> 按顺序展开
遇到循环引用或深度太深就停止,别把脚本跑死。能还原的先还原,不能还原的后续再处理。
_C[0]、_C[4]、_C[10] 运行时解码入口
固定槽位和 _C[9] 处理完后,还会剩 _W(_C[index], ...)。其中 _C[0]、_C[4]、_C[10] 不是普通字符串槽位,它们后面被改成了函数:
_C[4] = function mr(xF, QO, z, FL, eo) {
var d = [];
// ...
};
_C[10] = function xf(yg, kZ, dn, uu, h5, L2) {
var d = [];
// ...
};
_C[0] = function vx(AN, OA, FL, EL, q) {
var d = [];
// ...
};
再结合前面的绑定:
var _W = _eb["bind"](_eb);
所以 _W(_C[10], null, 8, 79) 不是取值,而是在调用 _C[10] 里的函数。_C[0]、_C[4]、_C[10] 都是运行时入口。
这里面有两种:
静态参数
d[35] = _W(_C[4], null, 16, 230);
这种因为参数是固定的,每次结果不变,好还原。
动态参数
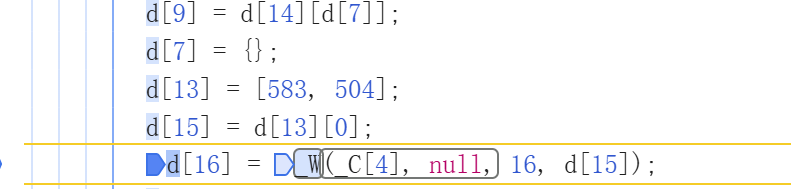
 ](
](这种需要根据上下文来进行还原处理,不能静态还原。
这里为了通用,直接参考虚假分支的方式处理。能返回字符串的就记录,不能返回字符串的就跳过。让 AI 编写好代码后,同样会收集出一个 json 文件:
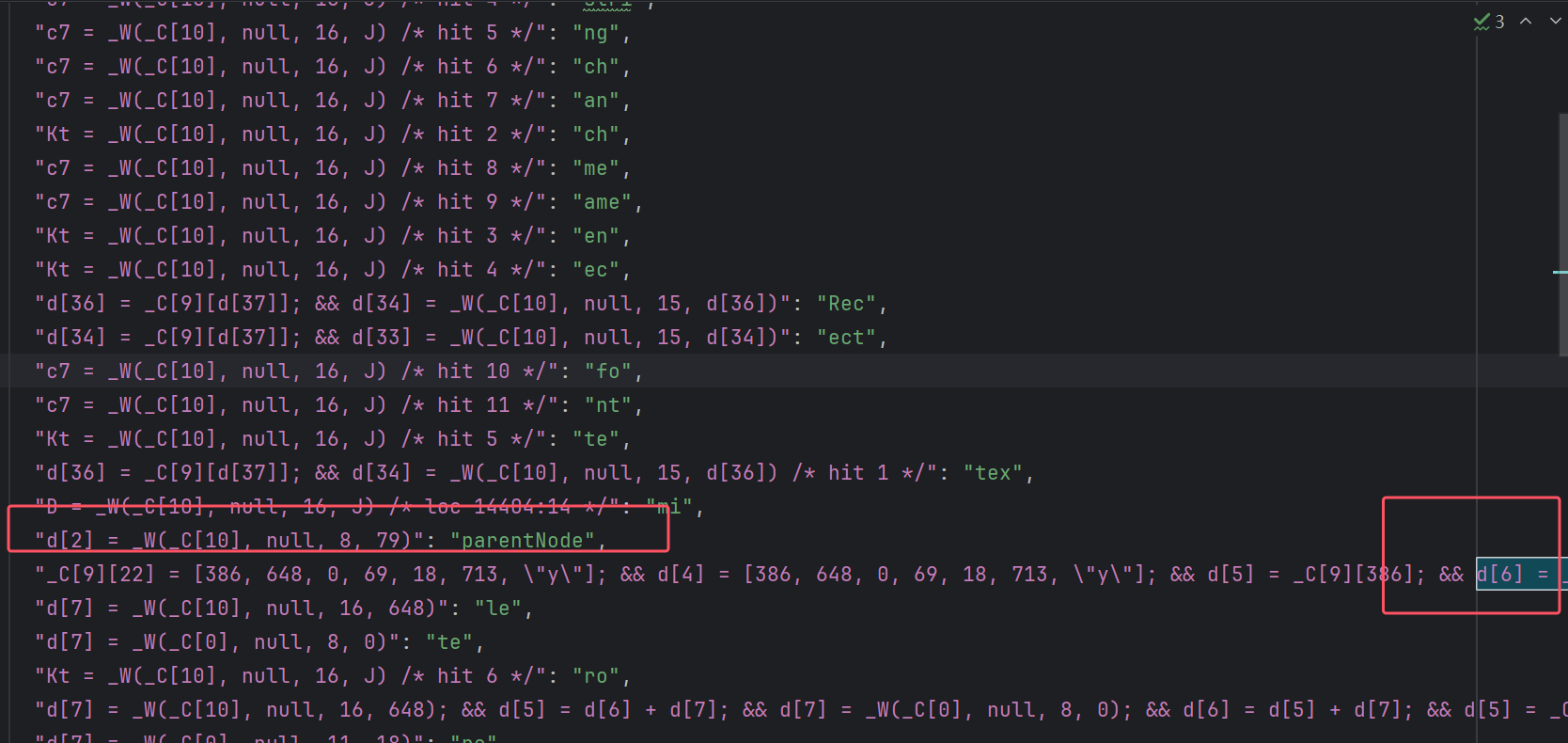

这里面的键有的很长,是因为动态收集时可能遇到多个相同的字符串解密语句,不好判断。遇到这种情况,就让 AI 继续往上记录语句,例如下面的:
d[6] = _W(_C[10], null, 15, d[5])
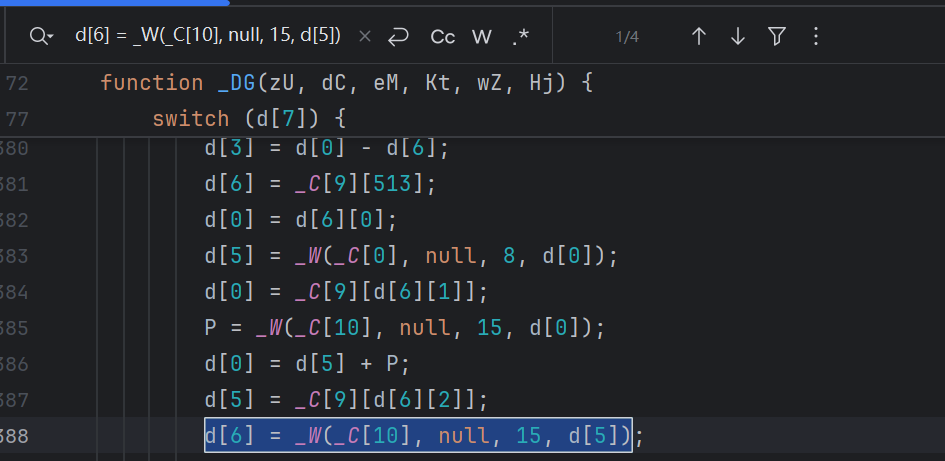
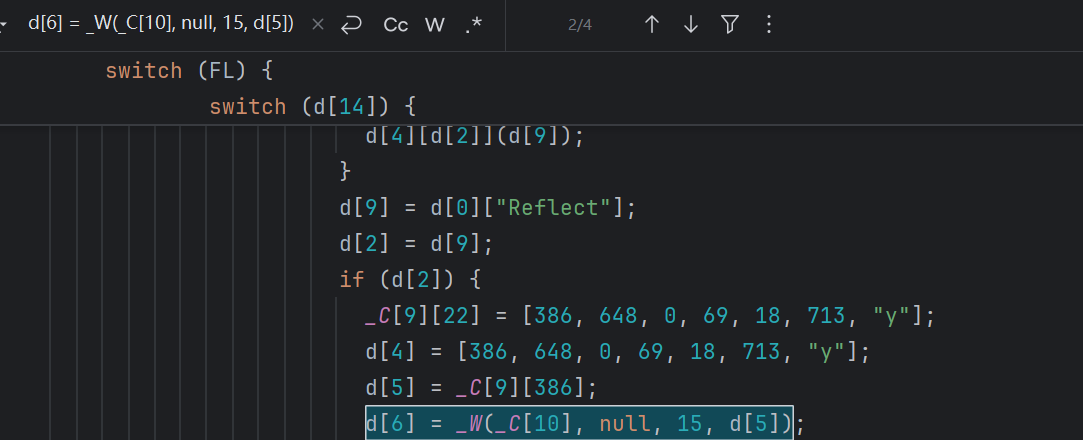
这里有四处相同的字符串解密语句,所以要借助兄弟节点来区分还原。最终还原如下:
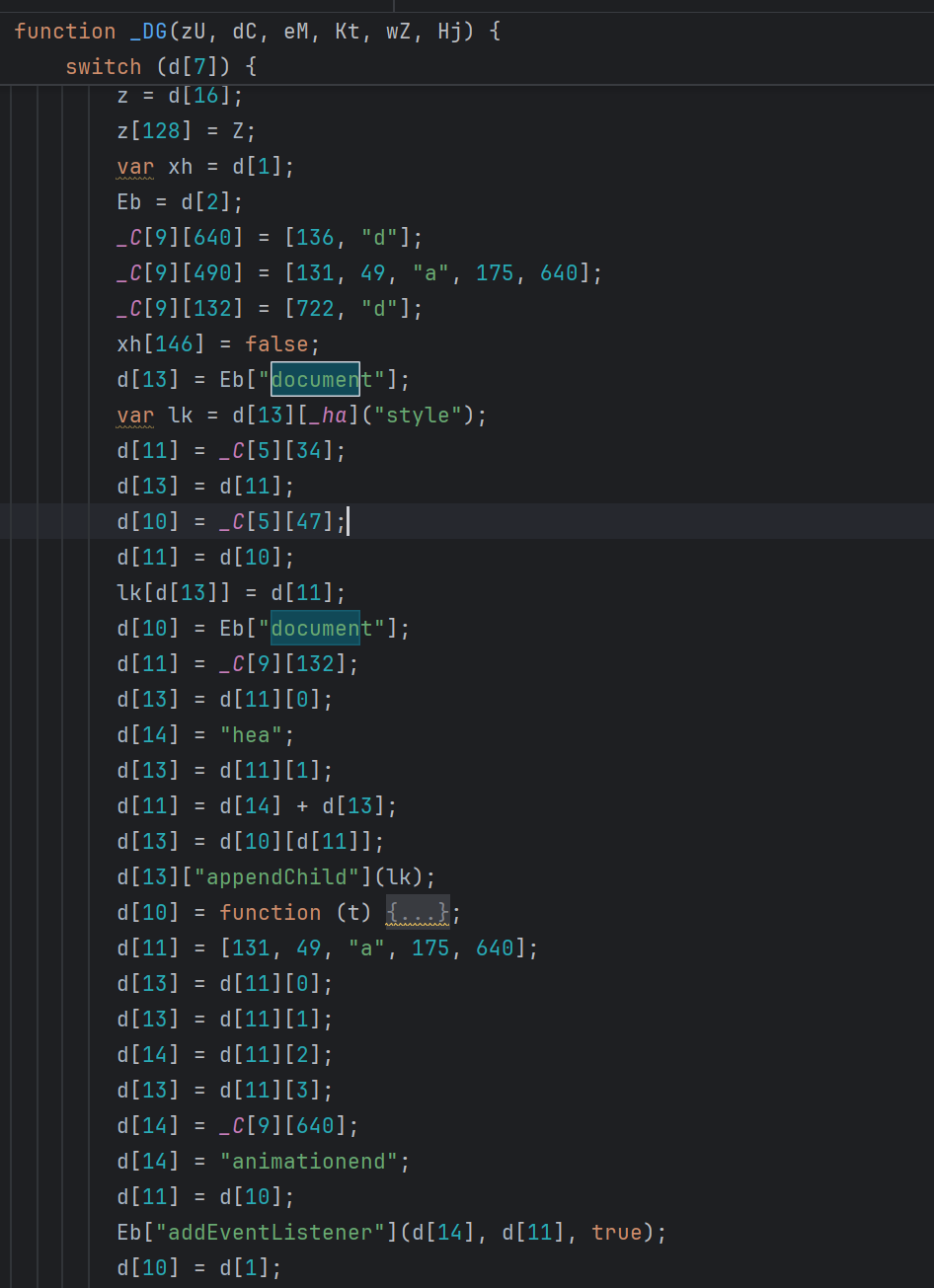
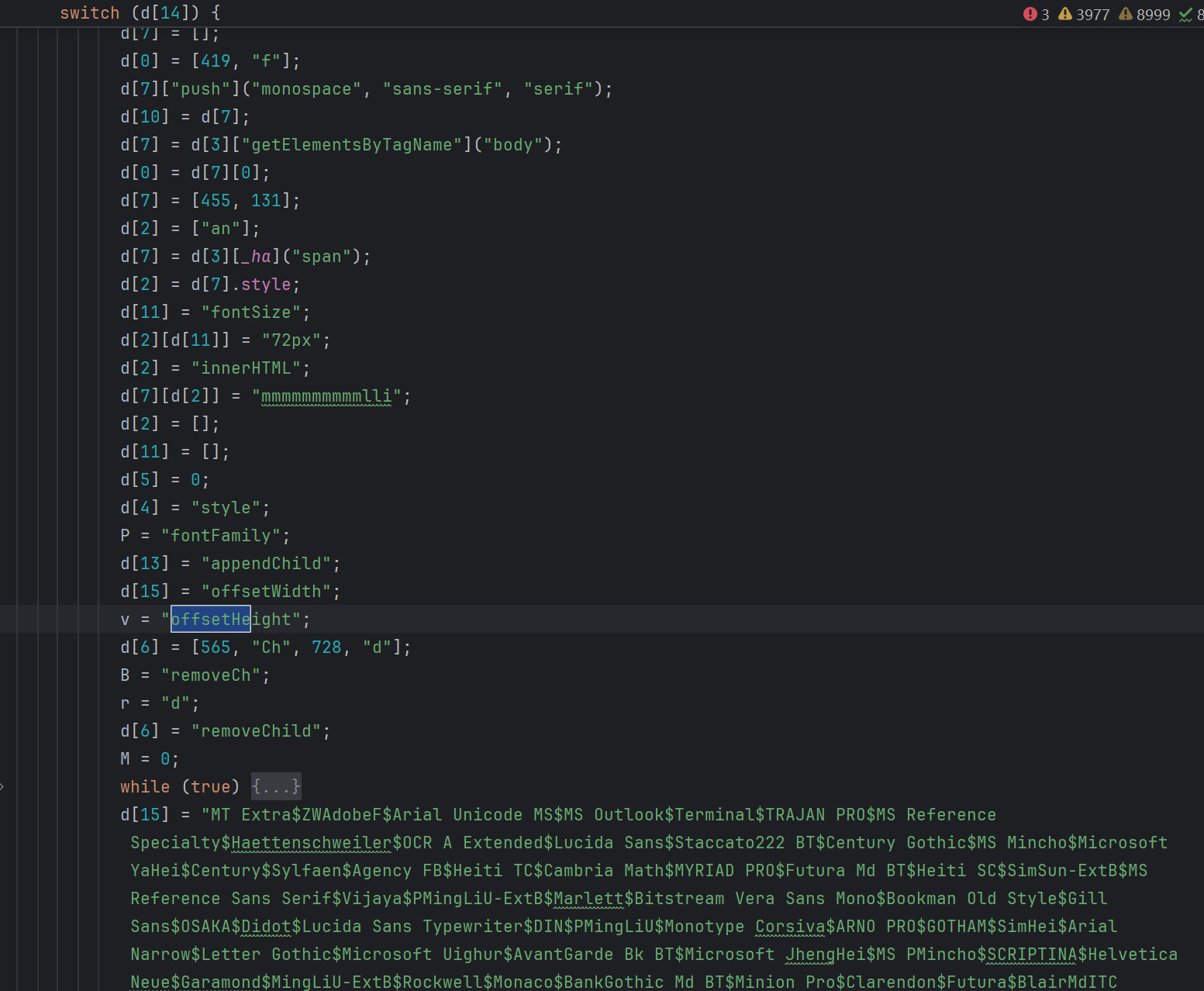
局部代码删除
字符串替换完之后,代码里会出现很多可以继续折叠的局部变量。比如:
J = ".";
v = _uu["split"](J);
J = v["length"];
这种已经能看懂。有些拼接链还可以继续折叠:
AN = "__bx_fy_g";
s = "__bx_fy_gy_";
q = "__bx_fy_gy_cl";
v = d[2]["__bx_fy_gy_cl"];
遇到这种局部清理,可以直接让 AI 处理,把无用的中间变量和临时代码删掉即可,这里就不展开了。
做到这里,字符串层面的混淆基本就拆掉了,后面就可以正常分析算法了。
相关思路和流程就分享到这里,剩下的细节可以按这个流程继续往下还原,相信大家多调教调教 AI,也能还原出自己的解混淆版本。
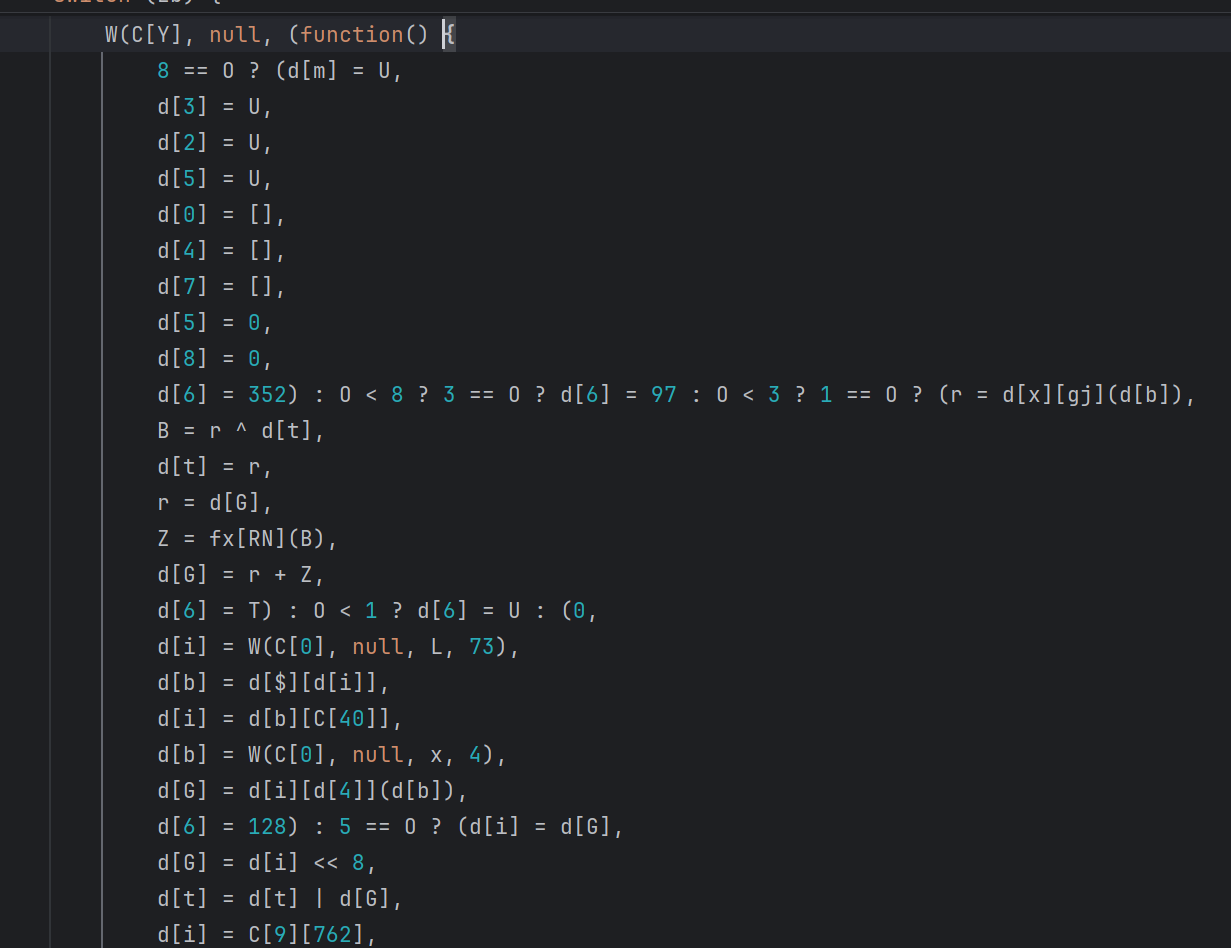
结果展示
还原前:
还原后: