
本工具仅限学术交流使用,严格遵循相关法律法规,符合平台内容的合法及合规性,禁止用于任何商业用途!
一、开发背景
作为国内极具影响力的短视频社交平台,dy凭借极强的互动性与庞大的达人创作者生态,已成为热点事件发酵、优质内容传播的重要阵地。为满足用户多样化的数据采集需求,我基于 Python 技术开发了这款「dy聚合采集工具」。该工具集成了评论采集、达人主页采集、链接转换三大核心功能,可提供一站式数据采集解决方案。
工具主体采用 Python 语言开发实现,各模块功能分工如下:
tkinter:GUI软件界面
requests:爬虫请求
json:解析响应数据
time:间隔等待,防止反爬
pandas:保存csv结果
logging:日志记录
二、代码实现逻辑
2.1 登录配置
首次使用需要配置Cookie,新版支持自动化一键配置。
方法一:自动获取(推荐)
- 点击软件界面中的"Cookie辅助工具"按钮
- 在弹出的浏览器中登录账号
- Cookie自动保存到
cookie.txt
方法二:手动配置
# cookie.txt 文件内容示例
ttwid=1%7C...; passport_csrf_token=...; sid_guard=...
2.2 评论采集示例
代码示例:采集指定视频评论
import requests
import pandas as pd
import time
def collect_comments(video_id, cookie, max_pages=10):
"""
采集视频评论
Args:
video_id: 视频ID
cookie: 登录Cookie
max_pages: 最大采集页数
Returns:
DataFrame: 评论数据
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Cookie': cookie,
'Referer': f'https://www.douyin.com/video/{video_id}'
}
comments_data = []
cursor = 0
for page in range(max_pages):
url = 'https://www.douyin.com/aweme/v1/web/comment/list/'
params = {
'aweme_id': video_id,
'cursor': cursor,
'count': 20
}
try:
response = requests.get(url, headers=headers, params=params)
data = response.json()
if 'comments' not in data:
break
for comment in data['comments']:
comments_data.append({
'评论者': comment['user']['nickname'],
'评论内容': comment['text'],
'点赞数': comment['digg_count'],
'评论时间': comment['create_time'],
'IP属地': comment.get('ip_label', '')
})
cursor = data.get('cursor', 0)
if not data.get('has_more'):
break
time.sleep(2) # 避免请求过快
except Exception as e:
print(f'采集异常: {e}')
break
return pd.DataFrame(comments_data)
# 使用示例
if __name__ == '__main__':
# 替换为你的Cookie
cookie = 'your_cookie_here'
video_id = '7123456789'
df = collect_comments(video_id, cookie, max_pages=5)
df.to_csv('comments.csv', index=False, encoding='utf_8_sig')
print(f'共采集 {len(df)} 条评论')
2.3 用户作品采集示例
代码示例:采集博主作品列表
import requests
import pandas as pd
def collect_user_posts(sec_uid, cookie, max_count=50):
"""
采集用户作品列表
Args:
sec_uid: 用户sec_uid
cookie: 登录Cookie
max_count: 最大采集数量
Returns:
DataFrame: 作品数据
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Cookie': cookie,
'Referer': 'https://www.douyin.com/'
}
posts_data = []
max_cursor = 0
while len(posts_data) < max_count:
url = 'https://www.douyin.com/aweme/v1/web/aweme/post/'
params = {
'sec_user_id': sec_uid,
'count': 20,
'max_cursor': max_cursor
}
try:
response = requests.get(url, headers=headers, params=params)
data = response.json()
aweme_list = data.get('aweme_list', [])
if not aweme_list:
break
for aweme in aweme_list:
posts_data.append({
'视频标题': aweme.get('desc', ''),
'视频链接': f"https://www.douyin.com/video/{aweme['aweme_id']}",
'点赞数': aweme['statistics']['digg_count'],
'评论数': aweme['statistics']['comment_count'],
'转发数': aweme['statistics']['share_count'],
'发布时间': aweme['create_time']
})
max_cursor = data.get('max_cursor', 0)
if not data.get('has_more'):
break
except Exception as e:
print(f'采集异常: {e}')
break
return pd.DataFrame(posts_data[:max_count])
# 使用示例
if __name__ == '__main__':
cookie = 'your_cookie_here'
sec_uid = 'MS4wLjABAAAA...' # 从用户主页URL获取
df = collect_user_posts(sec_uid, cookie, max_count=100)
df.to_csv('user_posts.csv', index=False, encoding='utf_8_sig')
print(f'共采集 {len(df)} 条作品')
2.4 链接转换示例
import re
def extract_uid_from_url(url):
"""
从主页链接提取UID
Args:
url: 个人主页链接
Returns:
str: UID
"""
# 匹配模式: https://www.douyin.com/user/MS4wLjABAAAA...
pattern = r'douyin\.com/user/([^/?]+)'
match = re.search(pattern, url)
if match:
return match.group(1)
return None
def convert_app_to_pc_url(app_url):
"""
APP链接转PC链接
Args:
app_url: APP端分享链接
Returns:
str: PC端链接
"""
# APP链接格式: https://v.douyin.com/xxx/
# 需要请求重定向获取真实video_id
response = requests.get(app_url, allow_redirects=False)
location = response.headers.get('Location', '')
# 提取video_id
match = re.search(r'/video/(\d+)', location)
if match:
return f"https://www.douyin.com/video/{match.group(1)}"
return None
# 使用示例
if __name__ == '__main__':
url = 'https://www.douyin.com/user/MS4wLjABAAAA...'
uid = extract_uid_from_url(url)
print(f'UID: {uid}')
三、软件界面演示
搜索作品及评论: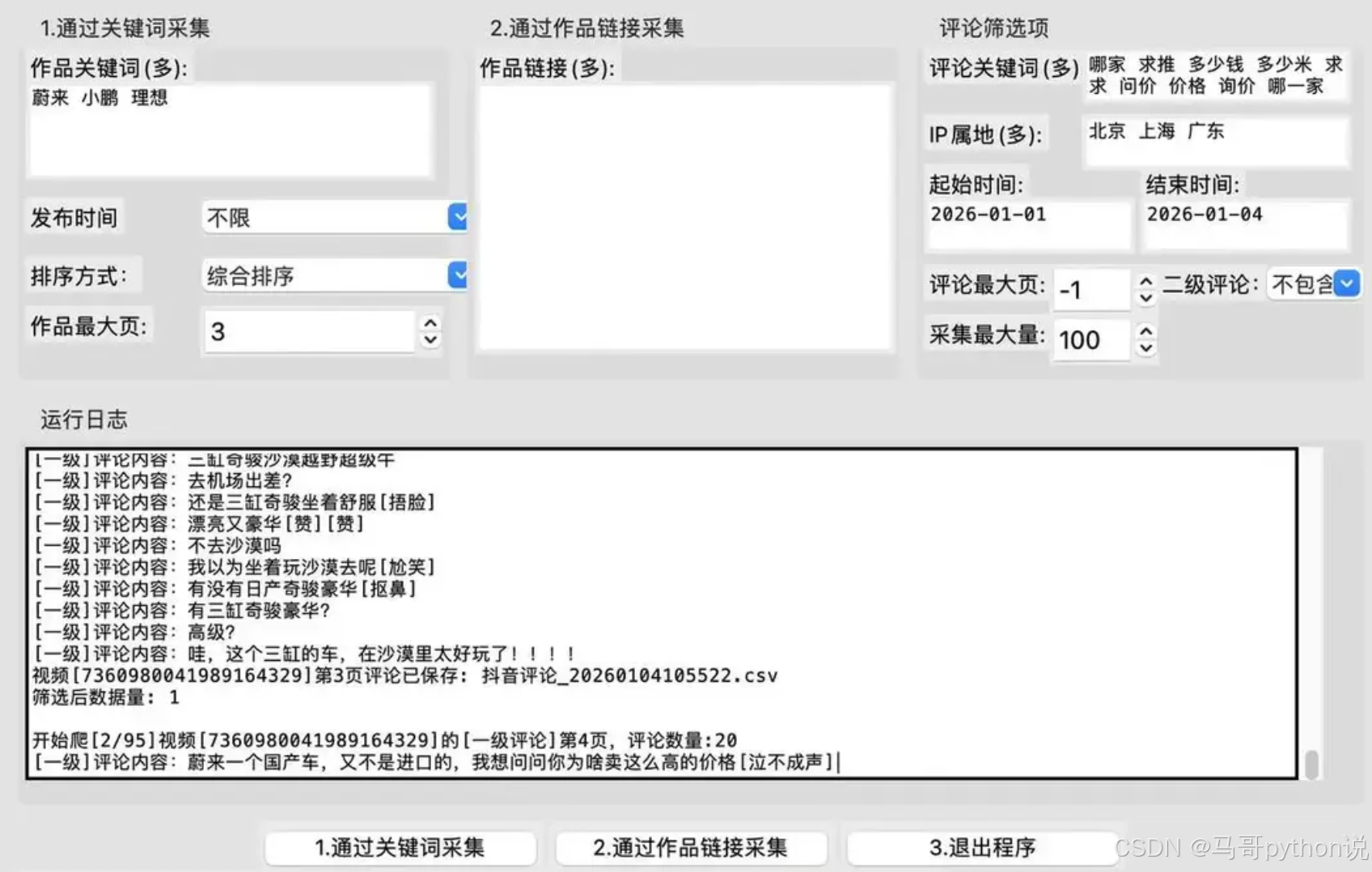
主页作品采集: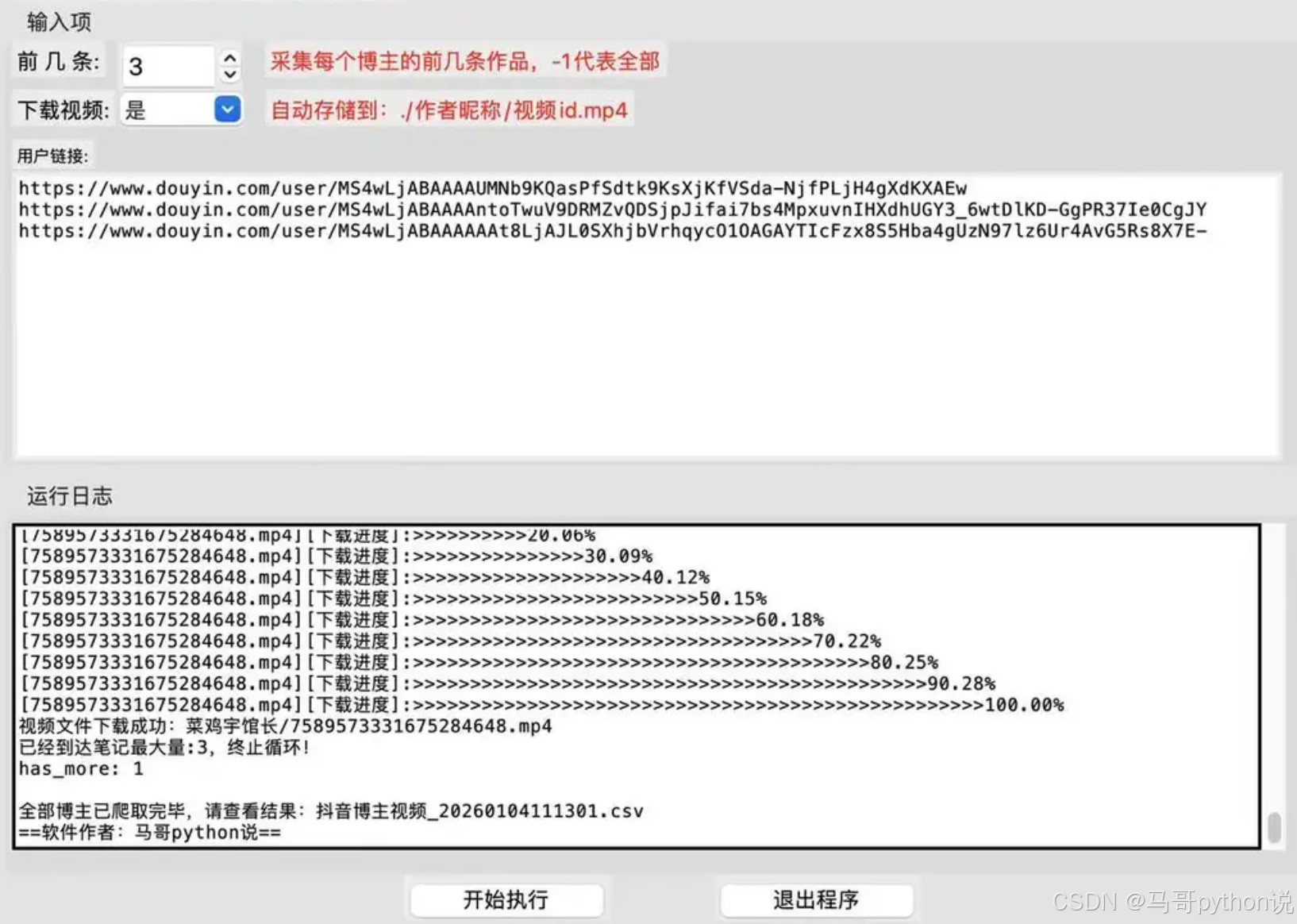
转换功能界面: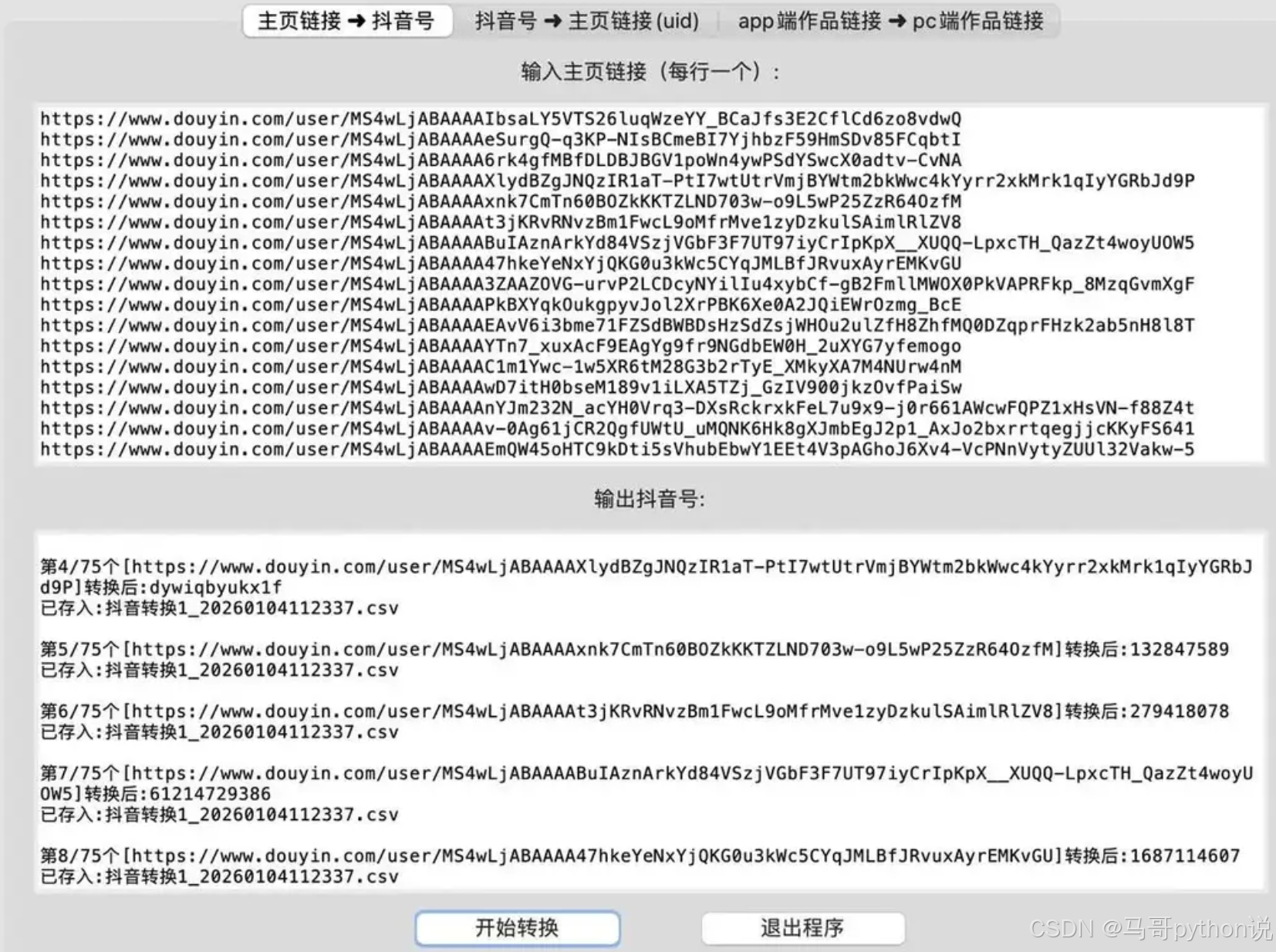
四、数据输出格式
4.1 评论数据CSV
目标链接,页码,评论者昵称,评论者ID,评论者UID,评论时间,IP属地,点赞数,评论级别,评论内容
https://www.douyin.com/video/7123456789,1,张三,zhangsan,123456,2026-03-14 10:00:00,北京市,128,1,这个视频很棒!
4.2 作品数据CSV
作者昵称,UID,粉丝数,视频标题,视频链接,发布时间,点赞数,评论数,转发数
科技达人,123456,125800,Python教程,https://...,2026-03-14,12500,890,6700
五、功能与使用
5.1 填写cookie
开始采集前,先把自己的cookie值填入cookie.txt文件。
新版已经支持一键自动配置,无需手动繁琐配置。
复制的cookie值自动写到当前文件夹的cookie.txt文件中。
5.2 软件登录
用户登录界面:需要登录。
5.3 启动采集
1)登录成功之后,选择需要的功能模块(搜索帖子/博主帖子/评论);
2)设置相关参数(如关键词、时间范围、博主链接等);
3)点击「开始执行」,等待采集完成(可实时查看采集进度);
4)采集完成后,在默认的当前文件夹中查看csv数据文件或视频下载等。
5.4 演示视频
软件使用的完整过程演示: 【工具演示】爬抖音聚合软件
END、原创声明
“爬抖音聚合软件"首发公号"老男孩的平凡之路”,欢迎技术交流、深入探讨。
本软件由本人独立原创开发,本文章由本人原创编写,请勿二创或任何形式的转载、盗发,违者必究!





