
如果你想了解当前AI大语言模型(LLM)的工作原理,揭开ChatGPT、DeepSeek等技术背后的奥秘,那么一定要认识本文的主角——Transformer。
每当提起Transformer这个话题,似乎人人都能说出几个相关术语,比如自注意力机制、编码器(encoder)、解码器(decoder)等等。但如果深入追问具体细节,却很少有人能真正讲明白。
Transformer最初源自一篇被誉为“AI大航海时代起点”的论文:
- Attention is All You Need
这篇论文首次提出的Transformer架构,如今已成为所有大语言模型的基石。
今天,我们就从这篇开创性论文出发,真正理解Transformer到底是什么。
本文不涉及复杂公式,只通过图解方式,力求让更多读者在阅读后能够通俗、系统地讲解Transformer的工作原理,从而真正明白它为何如此备受瞩目。
首先,我们引用论文中Transformer模型的整体架构图:
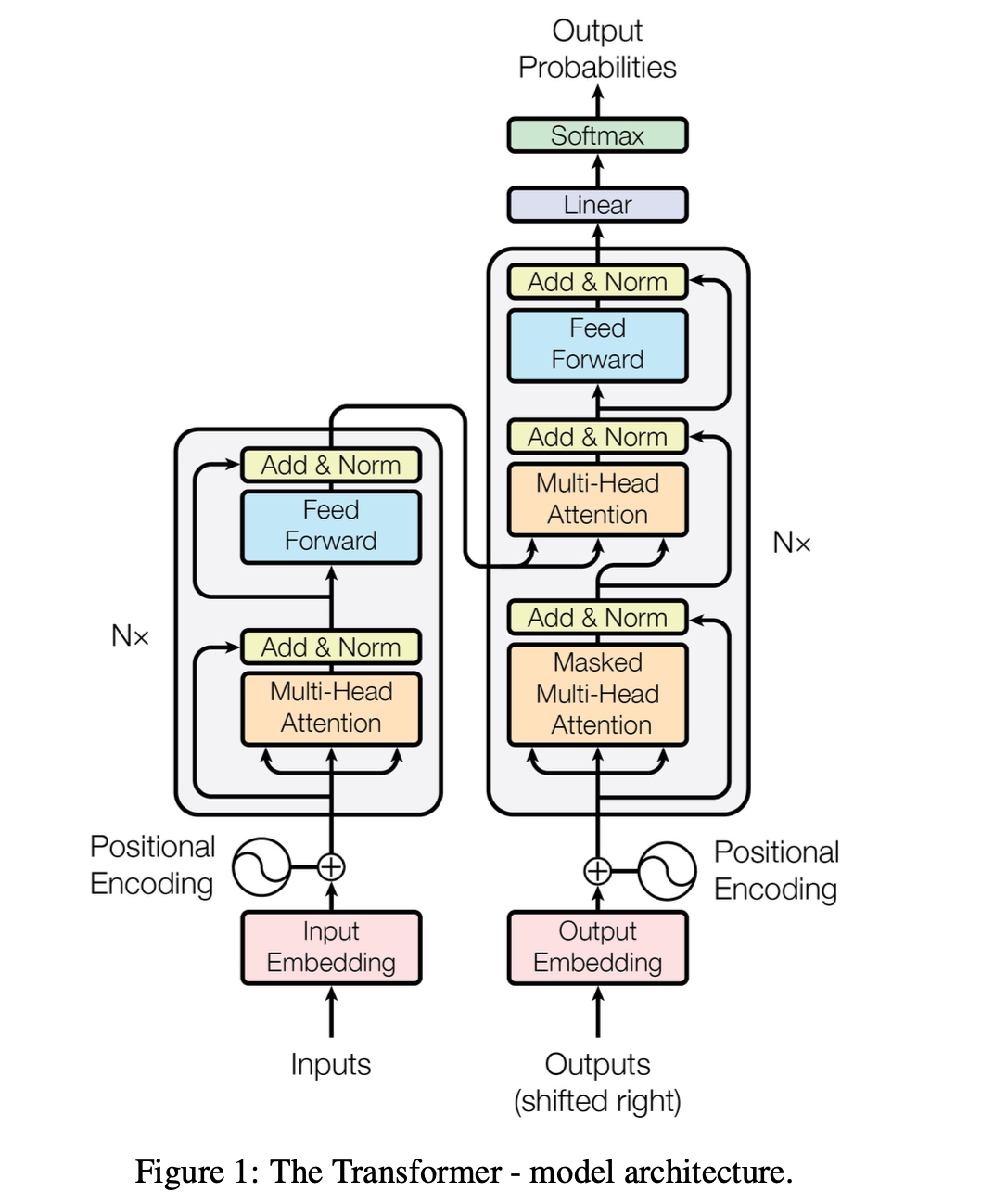
乍一看架构图是不是有点眼花缭乱?
别担心,接下来我们将一步步通俗解析这张架构图的深层含义。
图的左侧Input(输入)部分整体代表编码器(Encoder);右侧Output(输出)部分整体代表解码器(Decoder)。
01|输入是如何被Transformer“理解”的?整个输入流程你可以先记住以下关键步骤:
词语 → 向量化 → 加入位置信息 → 生成Q/K/V → 计算注意力 → 前馈神经网络(FFN) → 输出
下面我们来逐一讲解。
① 输入嵌入(Input Embedding):将词语转化为数字向量
模型本身无法识别“我”、“你”、“猫”这类词语,只能处理数字。
因此,需要将每个词转换为一个向量,即一组数字,例如:
我 → [0.12, -0.88, 0.43, ...]
这里为方便理解简化了数值精度。向量化是基础步骤,也是理解后续内容的关键起点。
② 位置编码(Positional Encoding):为模型赋予“位置感知”能力
Transformer不像传统的循环神经网络(RNN)那样逐词顺序处理输入,因此模型本身缺乏对词语先后顺序的“天然”感知。
所以需要额外告知模型:
“这是第1个词,这是第2个词……”
论文采用了正弦(sin)和余弦(cos)函数计算位置编码,使每个词都能明确自己的“位置”。
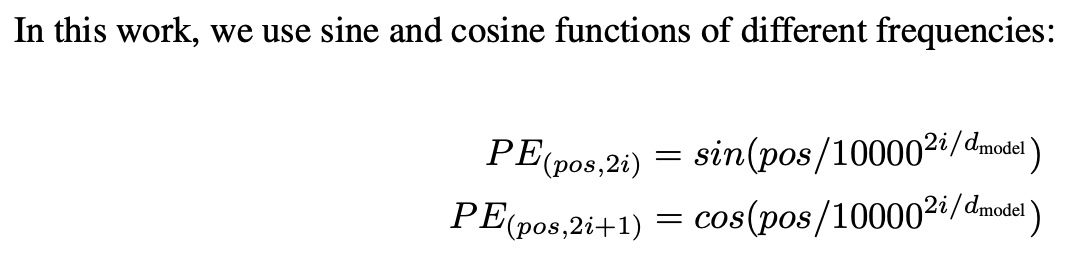
正弦/余弦位置编码初看可能有些数学感,但对模型而言是一种简单高效的实现方式。
它如同为每个位置贴上独一无二的“节奏标签”,使Transformer能够识别词语的“位置”,同时无需额外的训练成本。
③ Q / K / V:自注意力机制的核心
这一设计堪称神来之笔,令人叹为观止。
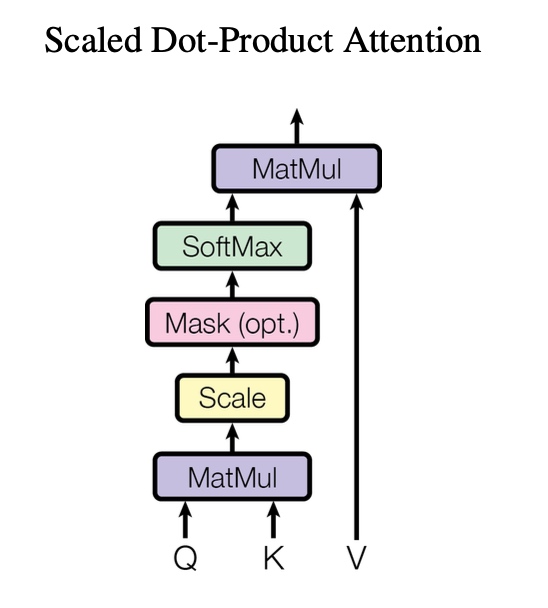
句子中的每个词语都会生成三个向量:
- Q(查询向量):代表“我想寻找什么?”
- K(键向量):代表“我是谁?我具备哪些特征?”
- V(值向量):代表“我的实际语义内容是什么?”
这些并非抽象概念,而是通过矩阵乘法实际计算得到的向量。
随后,每个词语会执行以下操作:
用自己的 Q 向量与其他词语的 K 向量进行“匹配度评分”,相当于询问:“你与我的关联程度如何?”
评分越高,模型就会越关注该词语。
最后,依据评分对 V 向量进行加权求和,生成该词语的“新语义表示”。
这就是基本的自注意力机制。
02|为何需要多头注意力机制?既然有了单一的自注意力,为何还要引入多头注意力机制呢?
因为自然语言的理解需要多维度视角。
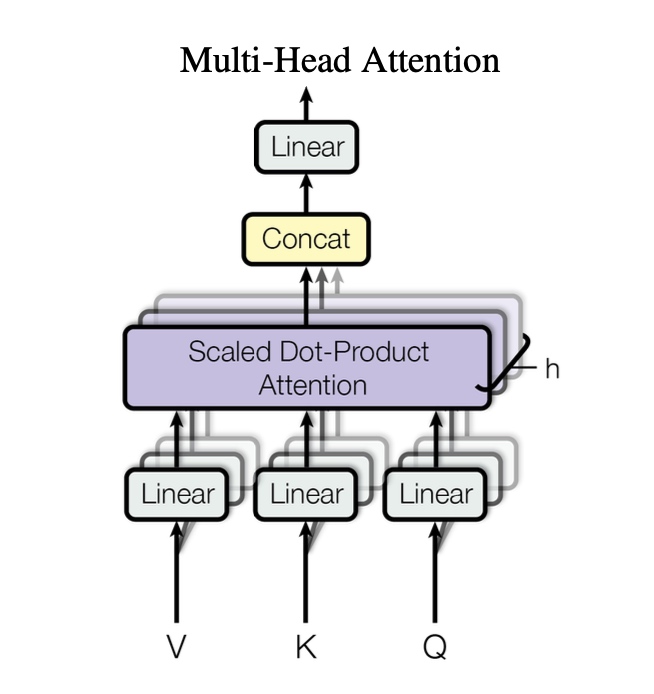
注意力头的数量是一个可调节的超参数,每个注意力头能够聚焦于不同的语言层面,例如:
- 有些头专门分析主谓结构
- 有些头负责追踪代词指代关系
- 有些头侧重情感色彩识别
- 有些头界定名词短语边界
- 有些头捕捉长距离依赖关系
- 有些头解析句法树结构
- ……
Transformer 模型并不局限于单一视角,原论文中即采用了 8 个并行的注意力头。
实际应用中可扩展至 12 个、48 个甚至更多注意力头,实现对句子的多角度深度扫描。
下图展示了论文中的一个简单示例,同一段文本经过两个不同注意力头处理后呈现出的关联模式,可见其关注焦点存在显著差异:
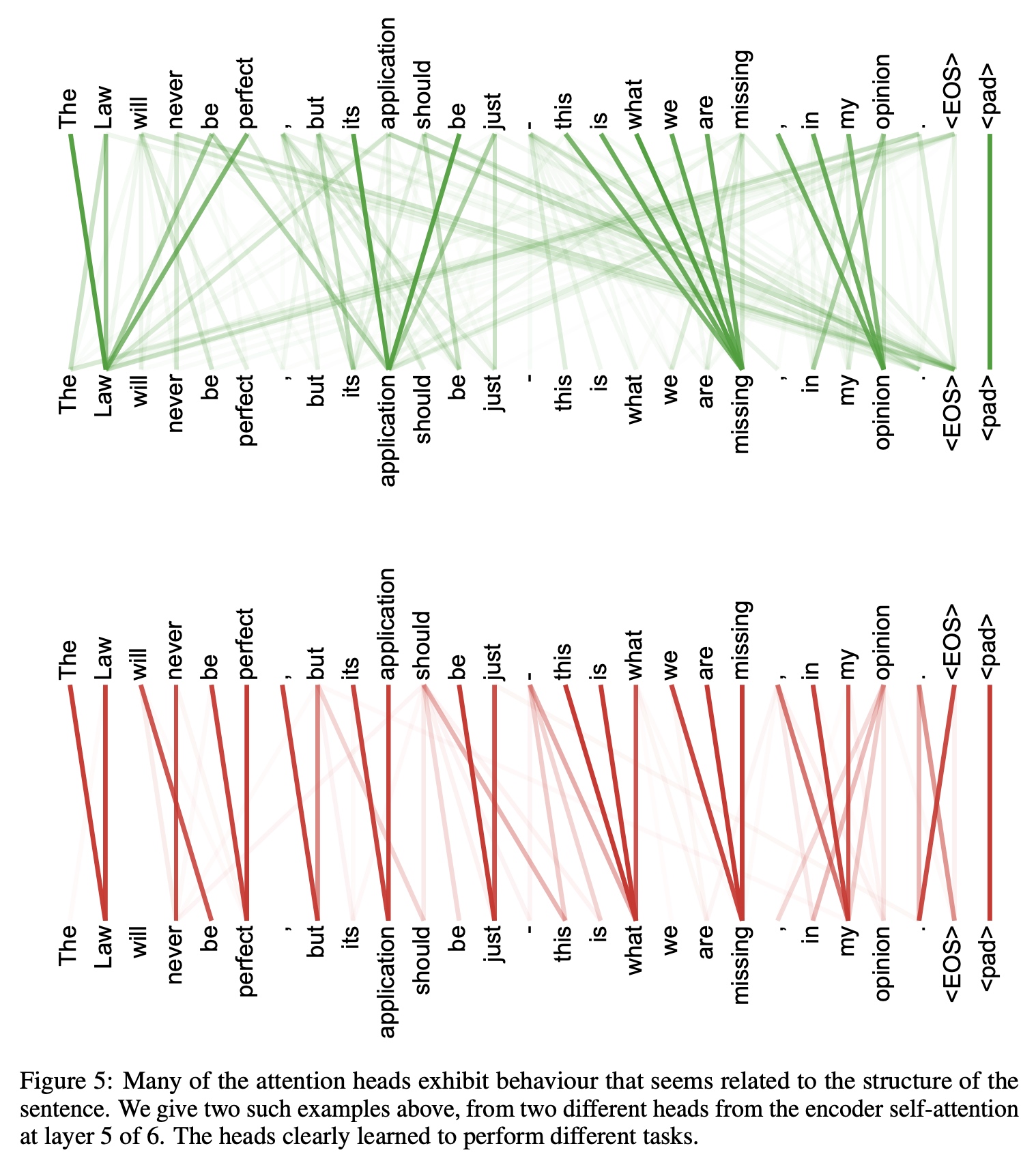
这正是多头注意力机制的直观体现。
03|残差连接与层归一化:提升训练稳定性自注意力机制仅对词向量进行了一次加工,但原始输入信息仍需保留。
因此采用如下结构:
原始输入 + 注意力输出 → 执行层归一化(对应架构图中的 Add & Norm 模块)
这种残差连接结构显著提升了训练过程的稳定性,使模型能够堆叠更多层数。
04|前馈网络(FFN):语义信息的深度加工注意力层的作用是广泛收集相关信息,实现信息的聚合;
而前馈网络则负责对这些信息进行更深层次、更复杂的非线性变换处理。
还是觉得抽象?我们可以这样理解:注意力机制负责发现关联,而前馈网络则致力于提升特征的表达能力。
论文中关于前馈网络的关键描述可参考下图:

简单来说,前馈网络就是一个经典的两层全连接神经网络结构:
线性变换 → ReLU激活 → 线性变换
通过前馈网络的处理,每个词元都能获得更加丰富和抽象的特征表示。这使得模型能够表达更复杂的语义模式,而不仅仅局限于简单的线性组合。
05|重复堆叠N次:论文采用6层,实际可扩展更多在原始论文中,编码器的Nx模块被设计为6层堆叠结构。
但这实际上是一个可调整的超参数。
后续的BERT、GPT、Llama等模型都将层数扩展到了几十层甚至上百层。
一般来说,模型层数越多、规模越大,其理解能力就越强。
这也是为什么在模型训练中,通过增加计算资源(如GPU)能够实现"大力出奇迹"效果的理论基础。
06|解码器:如何实现类人的内容生成?解码器作为模型的"文本生成器",其工作流程严格遵循架构图右侧的设计,核心机制是"从左到右,逐词生成"。
为了深入理解这一过程,我们以机器翻译任务为例:输入"I Love You",期望输出"我爱你"。
① 输出嵌入:将输出词转换为向量表示
处理方式与输入嵌入类似,每个输出词都被映射为一个向量,为后续计算做准备。
② 右移操作:防止模型"提前看到答案"
在模型训练阶段,需要将标准答案整体右移一位,并在开头添加起始标记,相当于让模型完成填空任务:
题目: <start> 我 爱此时模型接收到的输入为:
<start> 我 爱即原始序列向右移动了一个位置。
③ 掩码多头注意力:屏蔽未来信息
有读者可能会质疑:仅仅右移一位似乎效果有限,模型仍然能够看到部分答案内容,存在直接复制的风险,无法达到理想的训练效果。
这时就需要掩码多头注意力机制发挥作用,通过屏蔽未预测的词来防止模型"窥探未来答案"。
该机制与上述的右移操作协同工作,共同确保模型无法"提前获取答案信息"。
例如,模型需要依次完成以下填空任务:
第一空:题目是 <start> ______
第二空:题目是 <start> 我 ______
第三空:题目是 <start> 我 爱 ______通过这种设计,模型在每个步骤都只能基于已生成的内容进行预测,确保了生成过程的合理性和准确性。
④ 多头注意力机制——“向编码器请教”
解码器在生成每个新词时,都需要参考编码器的输出结果。这一层注意力机制起到了桥梁作用,将输入与输出联系起来,使解码器能够“向编码器请教”:
“当前生成的词与输入序列中的哪些部分最相关?”
以翻译 “I Love You” 为例:
- 生成“我”时,可能主要关注输入中的 “I”
- 生成“爱”时,可能主要关注输入中的 “Love”
- 生成“你”时,可能主要关注输入中的 “You”
⑤ 线性变换与Softmax:输出下一个词的概率分布
假设已经生成了“我爱”,接下来要预测的字可能对应如下的一组概率值:
你:71%
他:16%
它:11%
其它:2%
选择概率最高的词,即为下一个要生成的词。
最终总结通过本文的逐步解析,我们深入理解了 Transformer 的核心工作机制:从词嵌入与位置编码奠定语义和位置基础,到自注意力与多头注意力实现多角度的语义关联捕捉,再借助残差连接与层归一化确保训练过程的稳定性,最后通过前馈神经网络进行深层的非线性变换,增强特征表达能力。
编码器通过堆叠 N 个相同结构层,逐步深化对输入内容的理解;解码器的每一层则遵循更为严谨的处理流程:
在掩码多头注意力中,确保生成过程中不会“窥探”未来信息,随后进行相加与归一化操作。
在多头注意力机制(即论文中所指的编码器-解码器注意力层)中,解码器“请教”编码器的最终输出,并再次进行相加与归一化处理。
同样经过前馈神经网络进行深层特征提取,最后再经过一次相加与归一化操作,输出给下一层或最终的预测模块。
最终,解码器的输出通过线性变换与 Softmax 层转换为下一个词的概率分布。Transformer 凭借其高度并行化、可扩展的对称架构设计(编码器与解码器层具有相似的核心结构),已成为当今所有大语言模型的基石,完美体现了 “Attention is All You Need” 这一革命性理念。





