
OpenAI 发布的 GPT-OSS 模型 是其自六年前 GPT-2 以来最重要的开源大语言模型。在此期间,LLM 的能力取得了巨大进步。虽然与 DeepSeek、Qwen、Kimi 等现有开源模型相比,该模型本身在能力上未必有飞跃性提升,但这为我们重新审视近年来 LLM 的发展轨迹提供了一个很好的切入点。
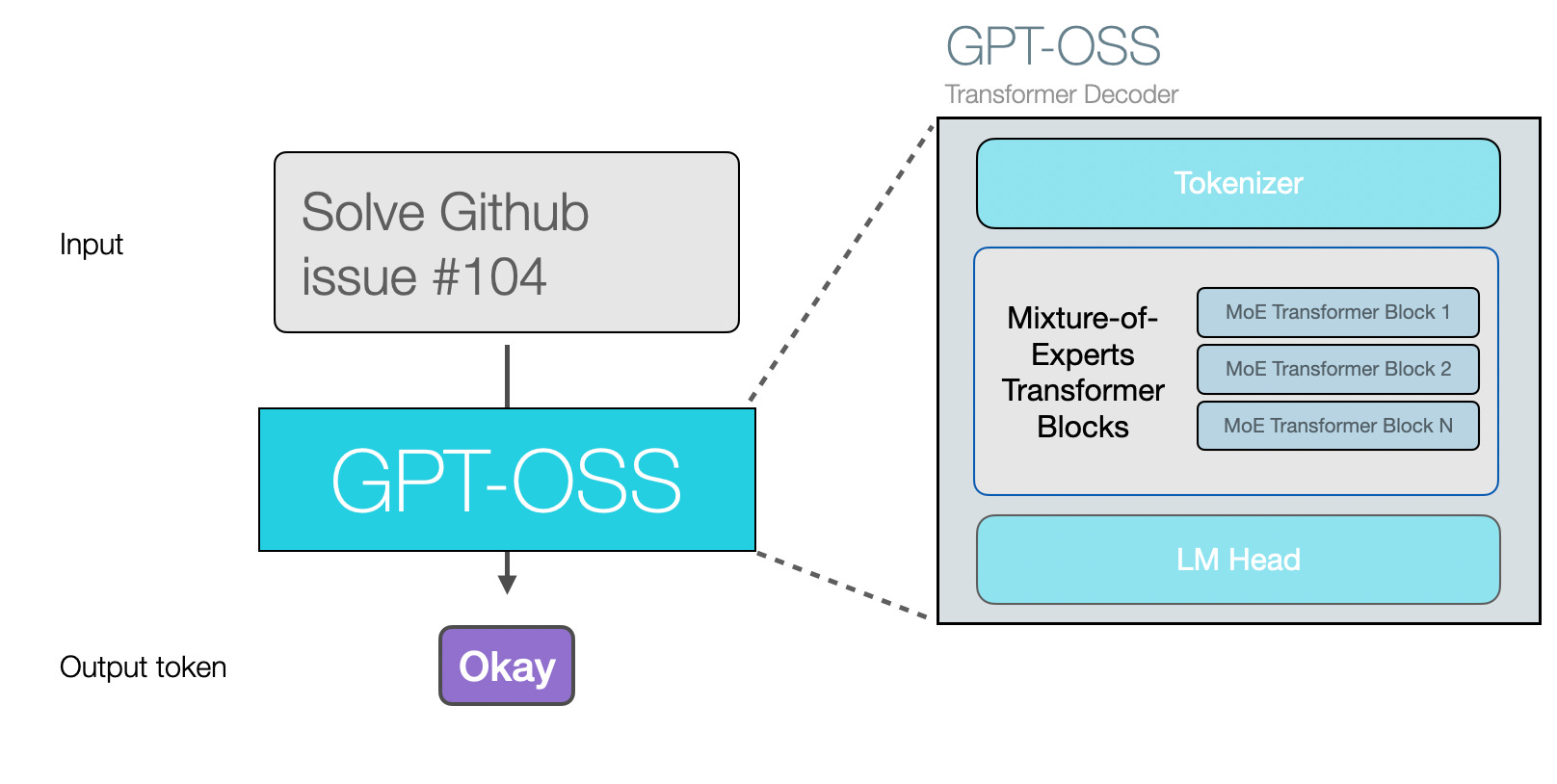
GPT-OSS 与先前模型相似之处在于,它仍是基于自回归架构的 Transformer 模型,每次生成一个 token。
2025 年中期的 LLM 主要差异体现在:它们通过生成 token 所实现的解决问题的能力已大幅提升,能够应对更为复杂的任务,这主要得益于:
- 使用工具
- 逻辑推理
- 提升问题解决和编程能力
下图展示了其主要架构特征,这些特征与当前主流开源模型并无显著差异。与 GPT-2 最大的架构区别在于 GPT-OSS 采用了 专家混合模型 架构。
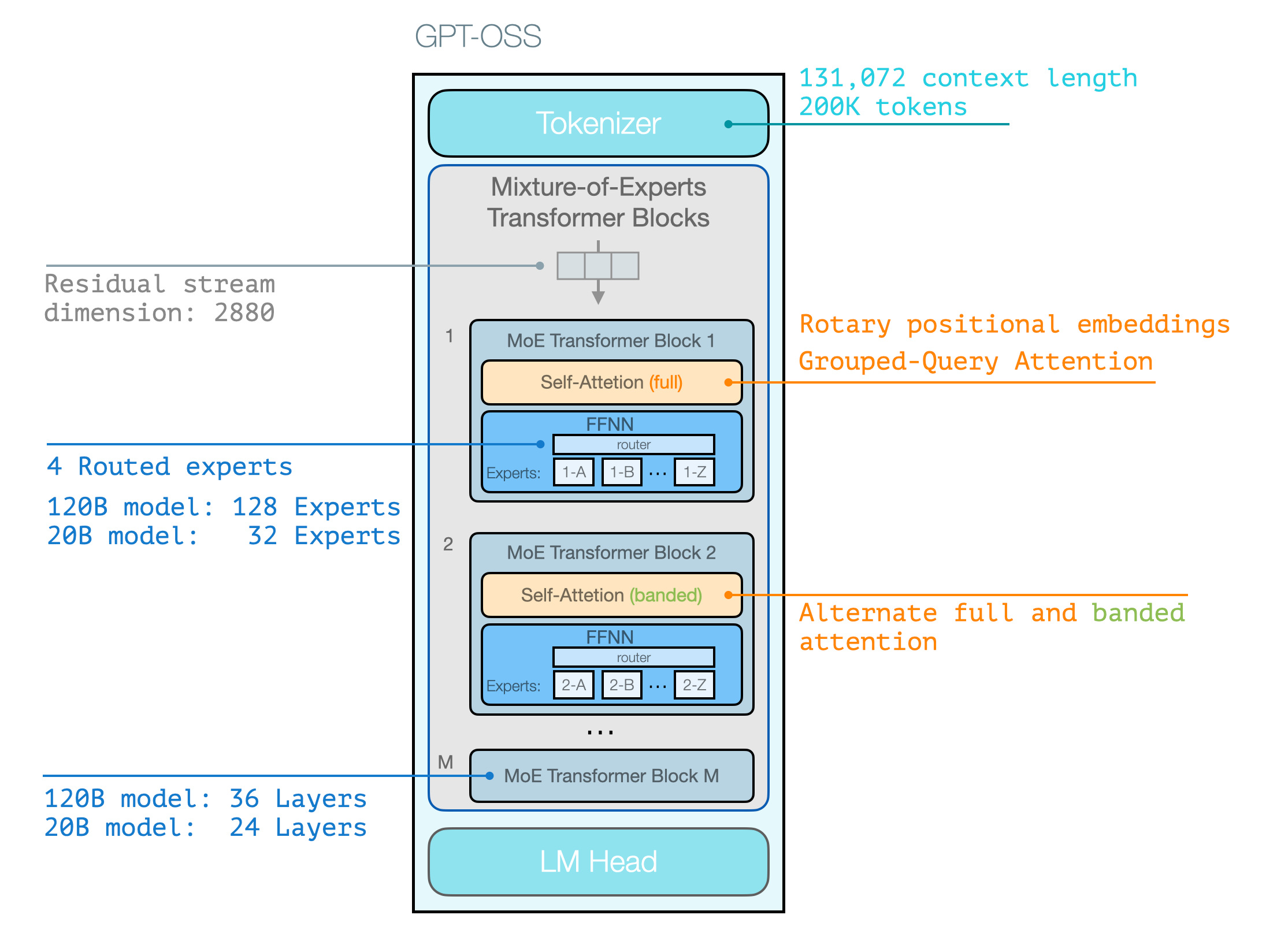
运用课程中介绍的注意力机制可视化语言,GPT-OSS 的 Transformer 模块结构如下图所示。
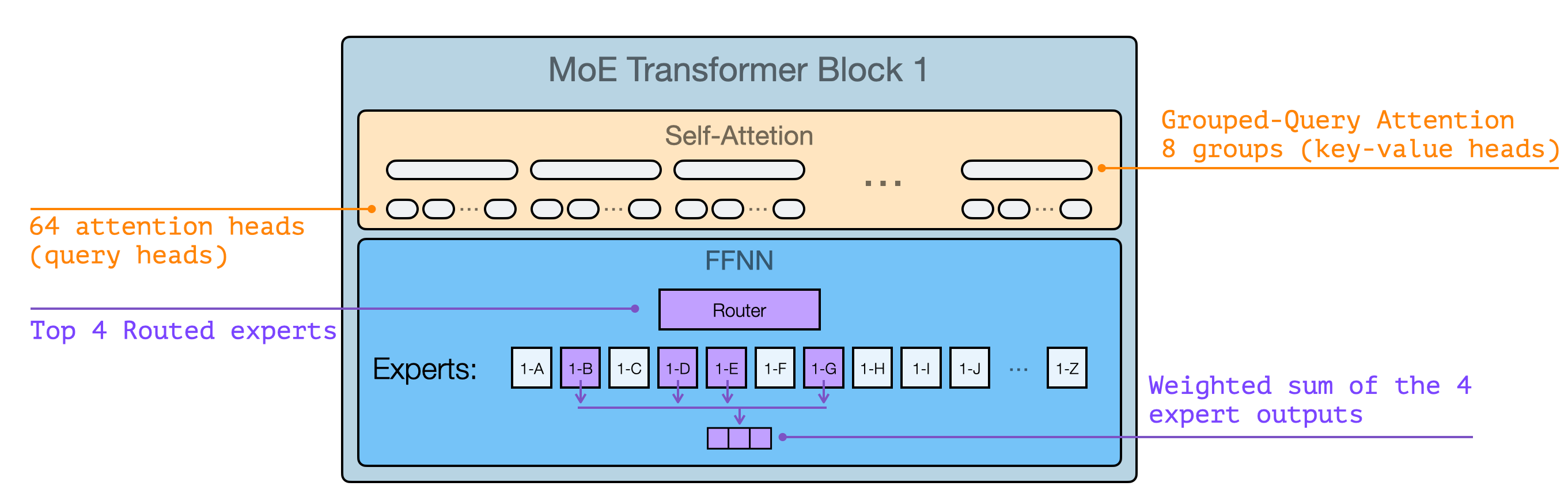
需注意这些架构细节大多并非创新设计,与最新开源 MoE 模型的技术路线基本一致。
消息格式化对更多用户而言,模型推理和工具调用的行为细节与格式化方式比架构本身更为重要。
下图展示了模型的输入输出结构:
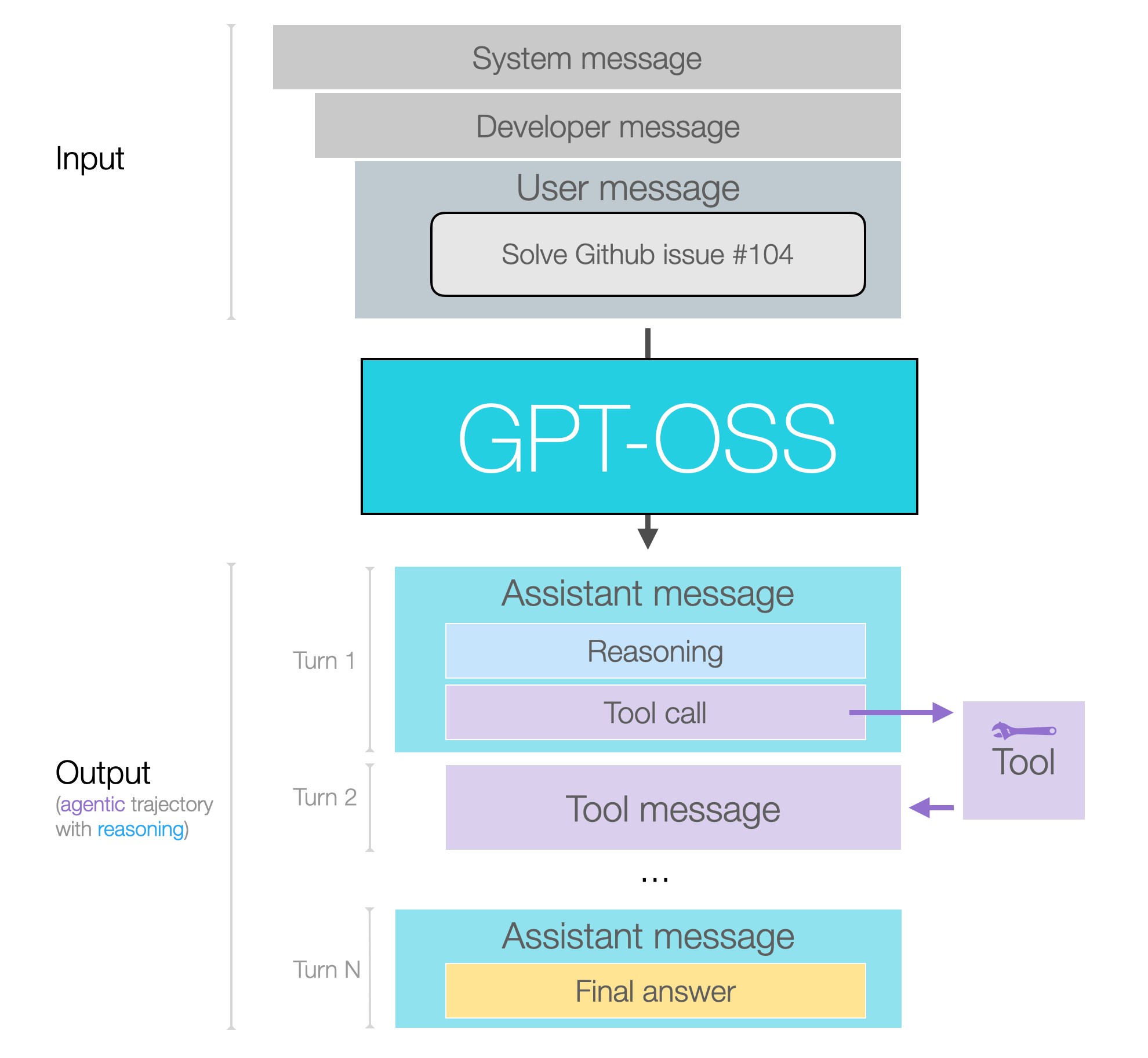
我们通过三类开源 LLM 主要用户群体来解析这个结构:
-
LLM 应用终端用户
-
示例:ChatGPT 应用使用者
-
主要关注发送的用户消息和最终答案,某些应用可能会展示部分中间推理过程
-
LLM 应用开发者
-
示例:Cursor 或 Manus 开发者
-
输入消息:可自定义系统和开发者消息——定义模型预期行为、安全选项、推理级别和可用工具。还需对用户消息进行大量提示工程和上下文管理
-
输出消息:可选择是否向用户展示推理轨迹。同时需定义工具集并控制推理深度
-
LLM 后训练工程师
- 进行模型微调的高级用户需要处理所有消息类型,并按规范格式化数据(包括推理过程、工具调用及响应)
后两类用户(LLM 应用开发者和后训练工程师)可通过理解助手消息的通道概念获益。该功能实现在 OpenAI Harmony 代码库中。
消息通道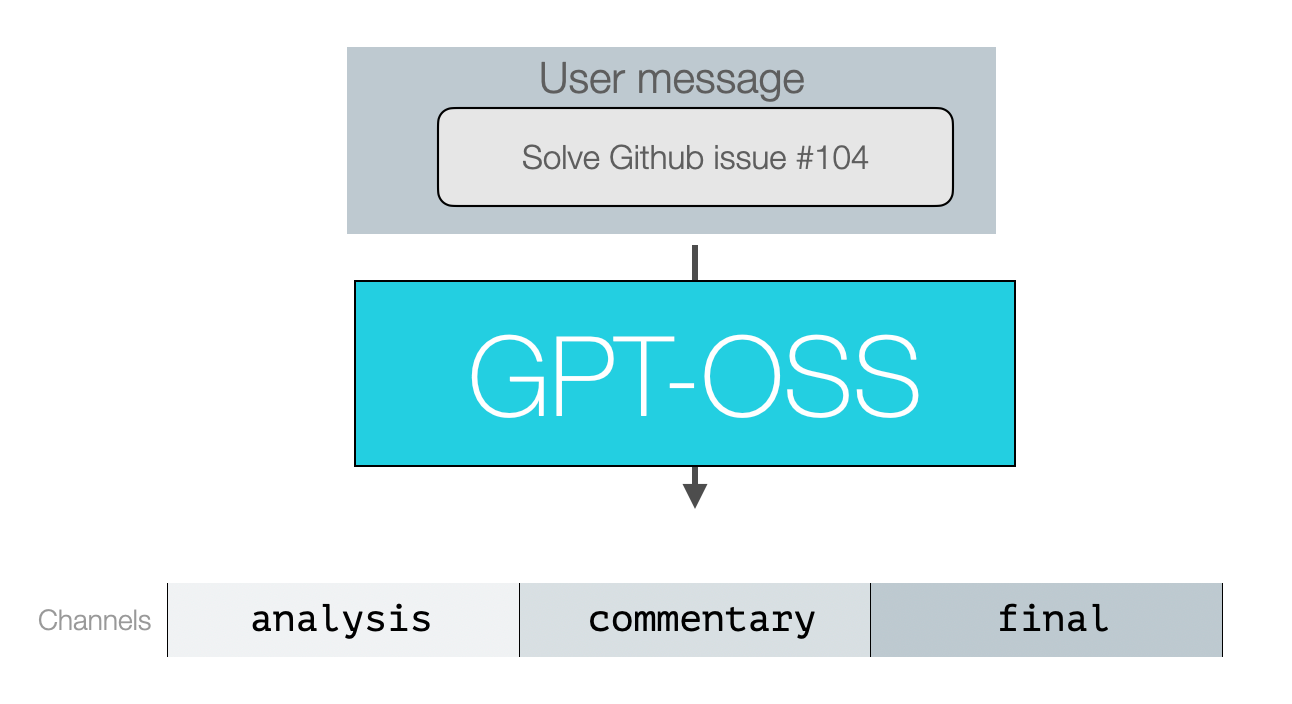
模型输出均为助手消息,并通过"通道"类别标识消息类型:
- 分析通道:用于推理(及部分工具调用)
- 评论通道:用于函数调用(及多数工具调用)
- 最终通道:包含最终回复的消息
假设我们给模型一个需要推理并使用多个工具调用的提示,下图展示了一个使用了全部三种消息类型的对话示例:
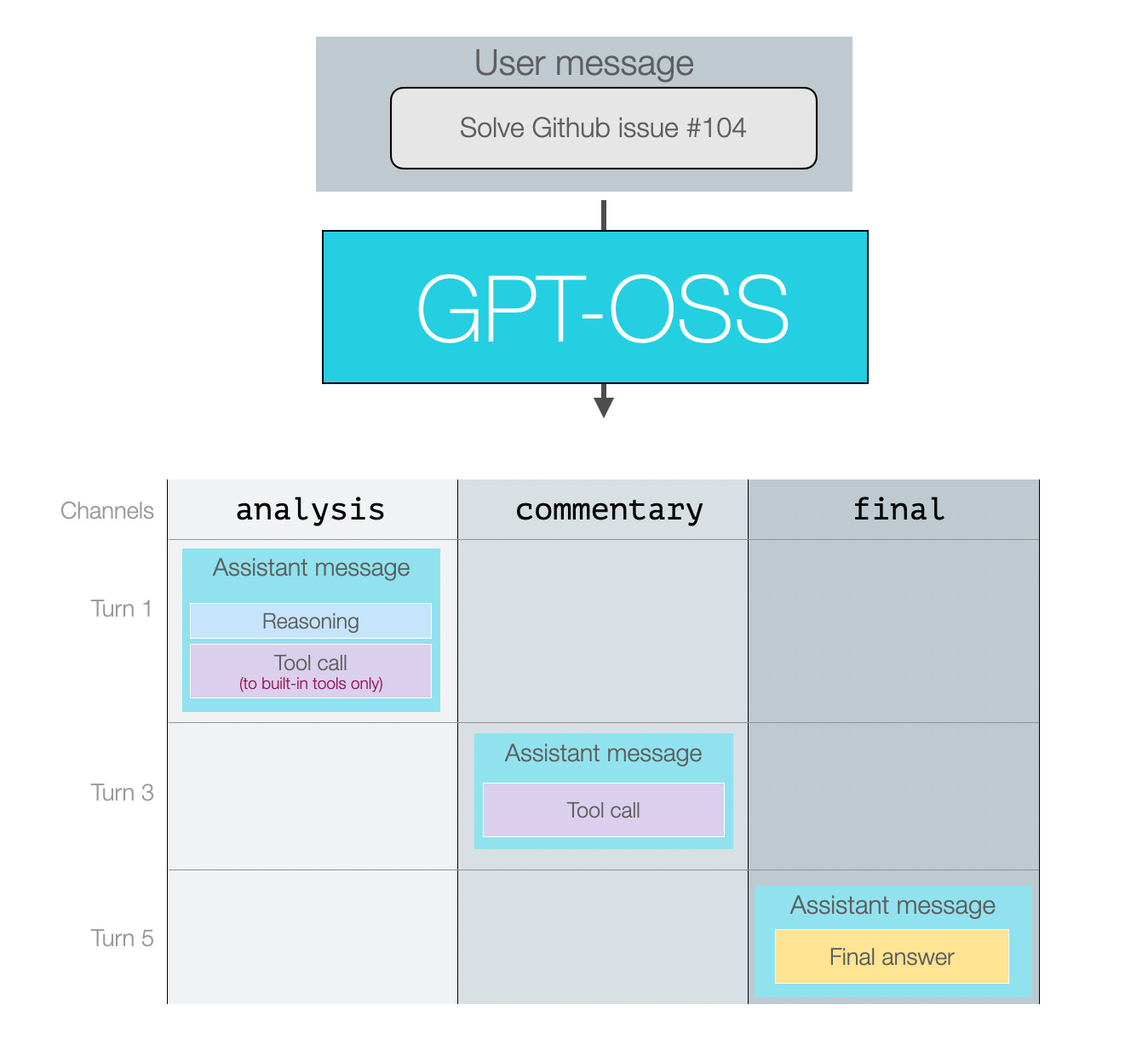
图中标注为第 1、3、5 轮是因为第 2、4 轮属于工具调用响应。最终答案将是终端用户可见的内容。
推理机制推理功能存在需要高级用户权衡的利弊:更多推理时间允许模型投入更多计算资源思考复杂问题,但会增加延迟和计算成本。正因如此,市场上才会同时出现强推理能力 LLM 和无需推理的 LLM,它们各自在不同类型的任务上表现优异。
折中方案是采用支持特定"推理资源配额"的推理模型,GPT-OSS 就属于此类。它允许在系统消息中设置推理模式(低/中/高)。模型卡片 中的图 3 展示了不同模式对基准测试得分和推理轨迹(即思维链)token 数量的影响。
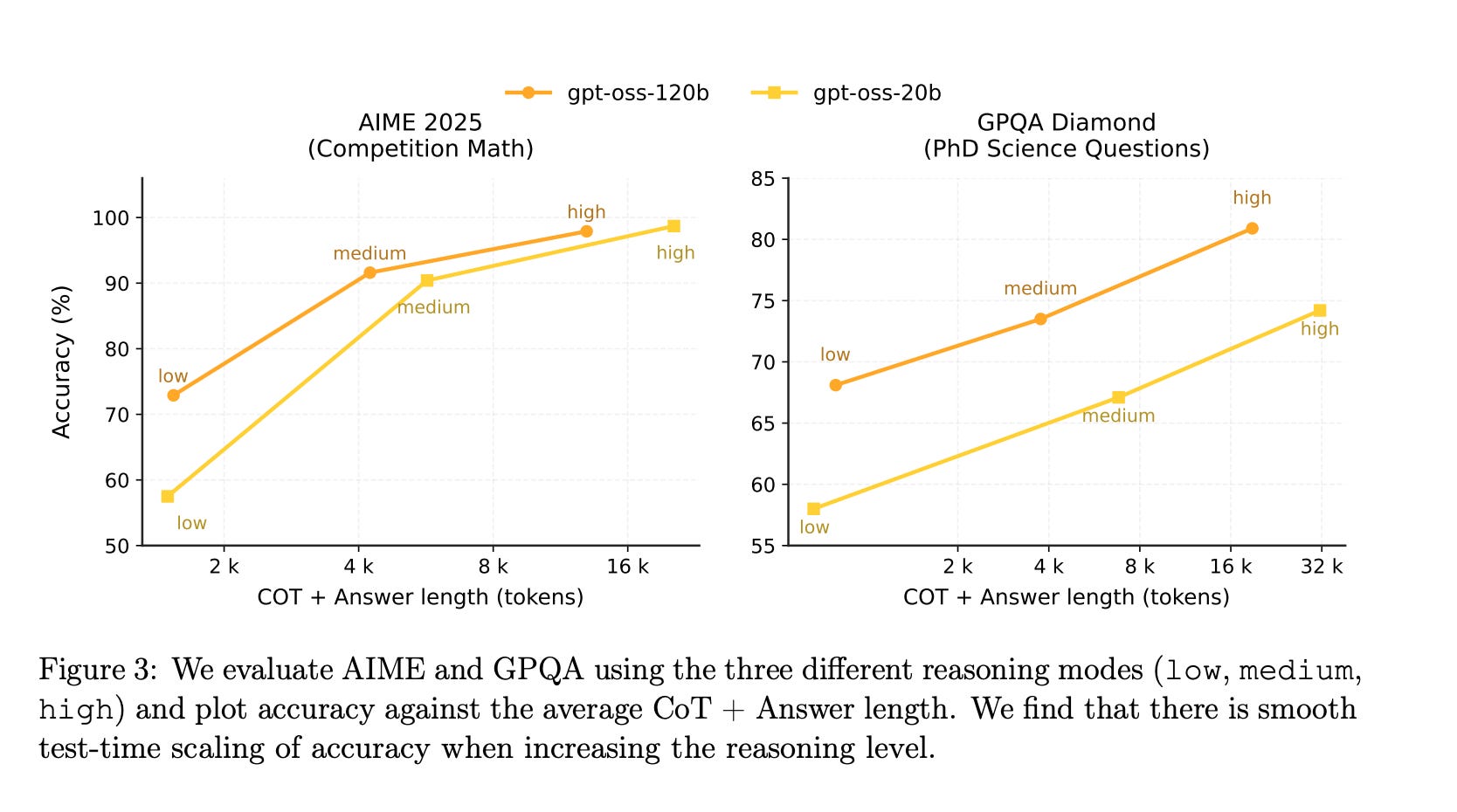
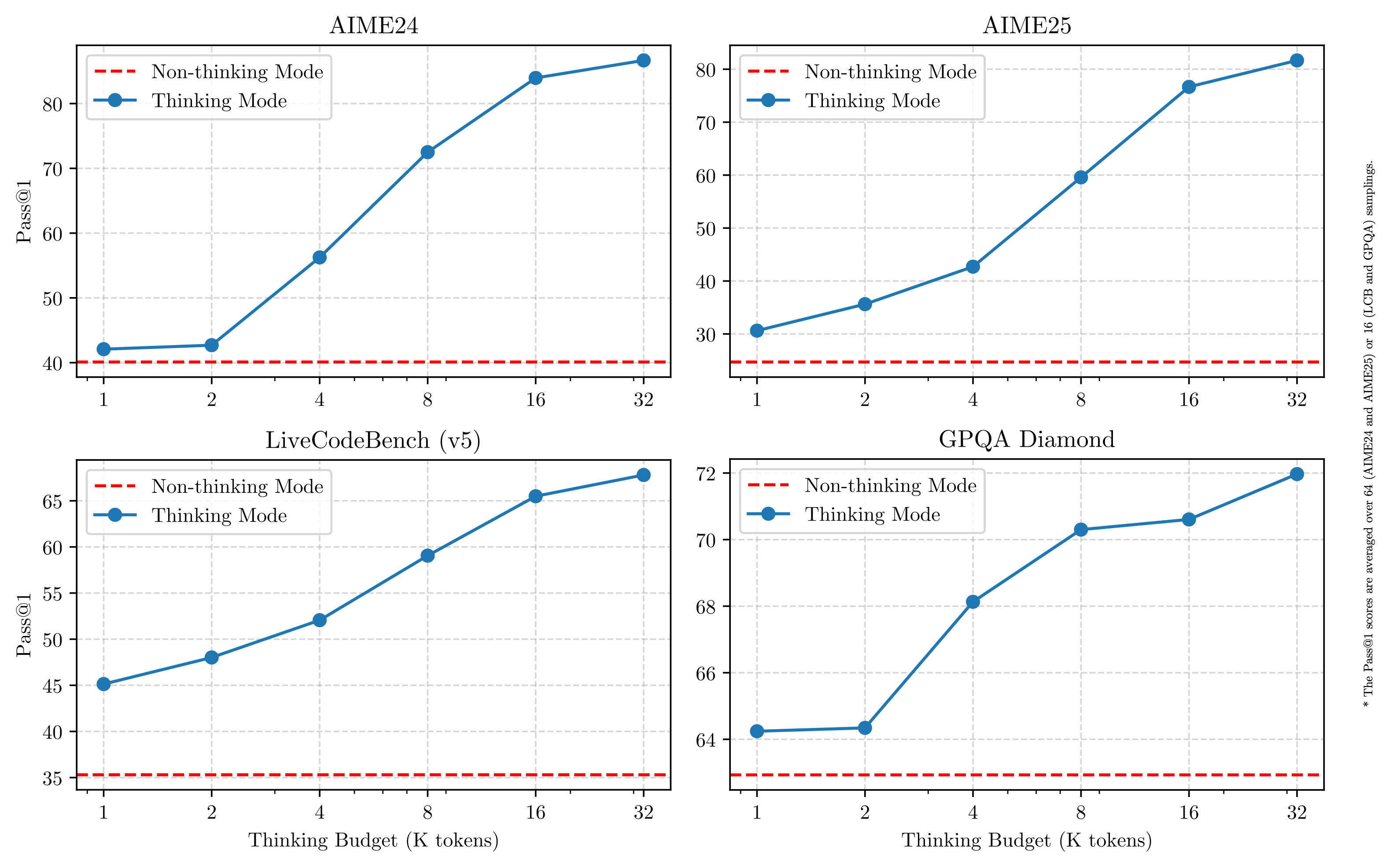
这与 Qwen3 的二元推理模式(思考/非思考)形成对比。在思考模式下,Qwen3 展示了在达到特定 token 阈值时停止思考的方法,并 报告 了这对各类推理基准测试得分的影响。
为展示不同推理模式的差异,我们选用 AIME25 数据集中的高难度推理题,在 120B 参数模型上测试三种模式:

该题正确答案为 104。中、高推理模式均能得出正确答案,但高模式需要双倍计算/生成时间。
这个例子正好印证了我们之前的观点:必须根据实际应用场景来选择推理模式:
- 执行智能体任务?若任务链涉及多步骤,高甚至中推理模式可能耗时过长
-
实时 vs. 离线场景:考虑哪些任务可离线执行而无需用户等待
- 以搜索引擎为例:通过预先进行的系统优化,可以在查询时实现快速响应
令牌化器与 GPT-4 类似,但效率略有提升——尤其对非英语 token 的处理。注意表情符号和汉字均被分为两个 token(而非三个),阿拉伯文字更多以完整词而非字母为单位分词。
不过尽管令牌化器有所改进,模型主要仍基于英语数据训练。
代码(及 Python 缩进用的制表符)的分词行为基本保持不变。数字分词方式也类似:三位数以内分配独立 token,更大数字则拆分处理。

以下推荐几篇深度解析文章:





