
从小白出发带你领略Python爬虫之美,关注微信公众号:机智出品(jizhjchupin),免费获取源代码及实战教程
一、系统环境:
Windows7+Python3.6
二、结果展示:
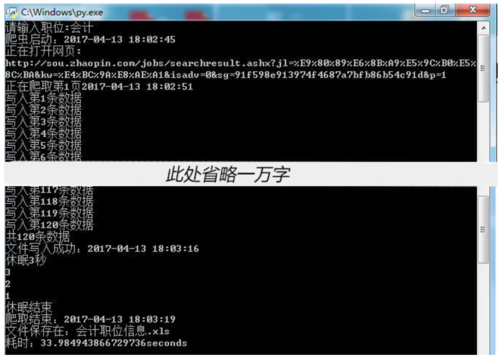
运行过程(这里只爬取了两页展示).jpg
三、代码解释:
step1:需要的库
from bs4 import BeautifulSoup as bsimport reimport timeimport requestsimport xlwtimport xlrdfrom xlutils.copy import copy from random import choice
step2:建立Excel表格
这里我们使用的是Python的第三方库xlwt进行Excel表格的写入
def createxls(keyword):
wb = xlwt.Workbook(encoding = 'ascii')
time9 = time.strftime("%Y-%m-%d", time.localtime())
ws = wb.add_sheet(time9+'智联招聘')#新建工作表
ws.write(0, 0, '职位名称')
ws.write(0, 1, '公司名称')
ws.write(0, 2, '职位月薪')
ws.write(0, 3, '工作地点')
ws.write(0, 4, '发布日期')
ws.write(0, 5, '地点')
ws.write(0, 6, '公司性质')
ws.write(0, 7, '公司规模')
ws.write(0, 8, '学历')
ws.write(0, 9, '岗位职责')
wb.save(keyword+'职位信息.xls')#保存工作表step3:自定义爬虫的User-Agent
为避免被屏蔽,爬取不同的网站经常要定义和修改useragent值。这里我们选取了一些常用的User-Agent,然后利用random的choice随机选择一个作为一次访问的User-Agent。
def useragent(): USER_AGENTS = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)", "Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11", ] headers =choice(USER_AGENTS) return headers
step4:获取招聘页面网址
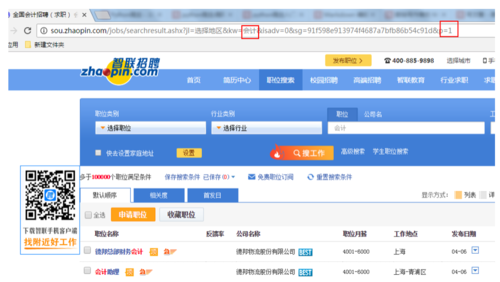
智联招聘.png
观察一些智联招聘的网址后,发现职位在kw=会计中,页码在p=1中,这样就好办了,我们通过修改这两个参数就可以得到所有某个职位的所有页的网址。但是智联招聘不让查看所有页,只能访问90页,那我们就爬90页,一页60条数据,5400条数据也是够了。
而且,如果想获取全网址的招聘信息,只要改下代码给出所有职业的关键词就可以!
def geturllist(keyword): listurl = ['']*90 h= keyword page = 1 d = 0 while d < 90: listurl[d] = 'http://sou.zhaopin.com/jobs/searchresult.ashx?jl=选择地区&kw='+h+'&isadv=0&sg=91f598e913974f4687a7bfb86b54c91d&p='+str(page) d=d+1 page=page+1 return listurl
step5:访问网站
def openurl(url):
print('正在打开网页:\n'+str(url)) try:
user = useragent()
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
r = requests.get(url,headers = headers,timeout = 10)
r.raise_for_status()
r.encoding = r.apparent_encoding return r.text except Exception as e:
print('Error:',e)
time3 = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
content = time3+' '+str(e)
logpath = '51joblog.txt'
with open(logpath,'a') as f:
f.write(content+'\n')
f.close() passstep6:获取数据写入Excel
我们使用bs4库来抓取需要的数据,再写入Excel里面。为了避免被屏蔽,我们爬取一页就用time.sleep模块休眠3秒
def writexls(html,k,temp,keyword):
time3 = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print('正在爬取第'+str(k+1)+'页'+time3)
soup = bs(html, 'lxml')
name = soup.findAll('a',href=re.compile(r'^http://jobs.zhaopin.com/'))
company = soup.findAll('td',{'class':'gsmc'})
money = soup.findAll('td',{'class':'zwyx'})
address = soup.findAll('td',{'class':'gzdd'})
fadate = soup.findAll('td',{'class':'gxsj'})
detail = soup.findAll('span',string=re.compile(r'地点:'))
detail2 = soup.findAll('span',string=re.compile(r'公司性质:'))
detail3 = soup.findAll('span',string=re.compile(r'公司规模:'))
detail4 = soup.findAll('span',string=re.compile(r'学历:'))
detail0 = soup.findAll('li',{'class':'newlist_deatil_last'}) try:
file = keyword+'职位信息.xls'
rb = xlrd.open_workbook(file, formatting_info=True)
wb = copy(rb)
ws = wb.get_sheet(0)
i = 0
j = 1 + temp while i < 100:
ws.write(j,0,name[i].get_text())
ws.write(j,1,company[i].string)
ws.write(j,2,money[i].string)
ws.write(j,3,address[i].string)
ws.write(j,4,fadate[i].get_text())
ws.write(j,5,detail[i].string[3:])
ws.write(j,6,detail2[i].string[5:])
ws.write(j,7,detail3[i].string[5:])
ws.write(j,8,detail4[i].string[3:])
ws.write(j,9,detail0[i].get_text())
i = i + 1
temp = j
print('写入第'+str(j)+'条数据')
j = j + 1
wb.save(keyword+'职位信息.xls') except IndexError as e:
wb.save(keyword+'职位信息.xls')
print('共'+str(j-1)+'条数据')
time.sleep(5)
file = keyword+'职位信息.xls'
rb = xlrd.open_workbook(file, formatting_info=True)
wb = copy(rb)
ws = wb.get_sheet(0)
time3 = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print('文件写入成功:'+time3)
print('休眠3秒')
print('3')
time.sleep(1)
print('2')
time.sleep(1)
print('1')
time.sleep(1)
print('休眠结束') return tempstep7:主程序设计
现在我们完成了各个模块,再进行主程序设计,下面是这个程序的一个思路。
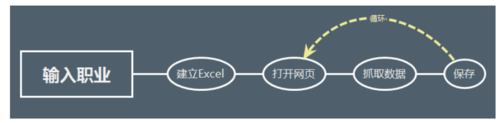
程序实现思路.png
while p < 90:
这里我们循环90次,也对应最多能查看的90页。
def main():
keyword = input('请输入职位:')
time1 = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
time0 = time.time()
print('爬虫启动:'+time1)
createxls(keyword)
listurl = geturllist(keyword)
p = 0
k = 0
temp = 0
while p < 90:
url=listurl[k]
html = openurl(url)
temp = writexls(html,k,temp,keyword)
p = p + 1
k = k + 1
time3 = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print('爬取结束:'+time3)
file = keyword+'职位信息.xls'
print('文件保存在:'+file)
time00 = time.time()
print('耗时:'+str(time00 - time0)+'seconds')
main()
input('回车退出')这是之前爬的一份Python的招聘信息:
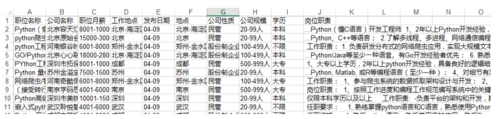
Python招聘.png
作者:机智出品
链接:https://www.jianshu.com/p/713e4e4dd5b4





