
照片由 Dan Dimmock 拍摄,来自 Unsplash,
让我们深入了解 Deep Research,这是目前最灵活的下一代 RAG 架构之一。让我们学习其模式并构建我们自己的,使用 Genkit。“RAG 在 2025 年已经过时了。它已经被反复攻克了。现在它已经没什么新鲜感了。”这是我最近从一位同行的 ML 工程师那里听到的话。确实,在 2025 年与客户讨论关于生成式 AI 的应用场景时,我发现标准的 RAG 已经无法满足需求了。用户需要回答的问题通常过于复杂且缺乏具体性,RAG 无法有效处理。他们也无法训练用户提出足够具体的问题,使得简单的检索无法定位到正确的上下文。数据源的数量和类型也过于繁多和复杂,标准化变得非常困难。
进入深度研究领域。深度研究是目前最通用和最有价值的生成性AI应用设计模式。每个AI工程师和领域领导者都应该了解深度研究以及如何根据自身情况进行定制。请注意,这里所说的并不是由Gemini、ChatGPT等提供的开箱即用的深度研究解决方案,而是你自己动手实现的深度研究解决方案,用于解决特定领域内的知识任务。
在这篇文章中,我们将讨论如何实现和泛化深度研究设计模式(Deep Research设计模式)。最终目标是根据您的领域需求进行定制。[代码仓库在这里]( https://github.com/jakobap/aaron )。
解答关于GCP技术问题的专家为了有一个具体的用例来处理,我们的目标是自动化我作为客户工程师工作中的大部分任务。在与客户会面后,我经常花大量时间撰写技术跟进邮件,回答客户未解决的问题,并提供诸如文档和示例代码之类的资源。这可能需要根据复杂性投入大量时间,尤其是在每周多次需要时。我们将构建一个深度学习系统来自动化这些技术跟进邮件。作为编排框架,我们将使用Firebase Genkit。
概念简介深度研究通常包括三个步骤:
- 理解并拆解用户请求
- 并行研究与信息检索流程以收集信息
- 汇总研究结果
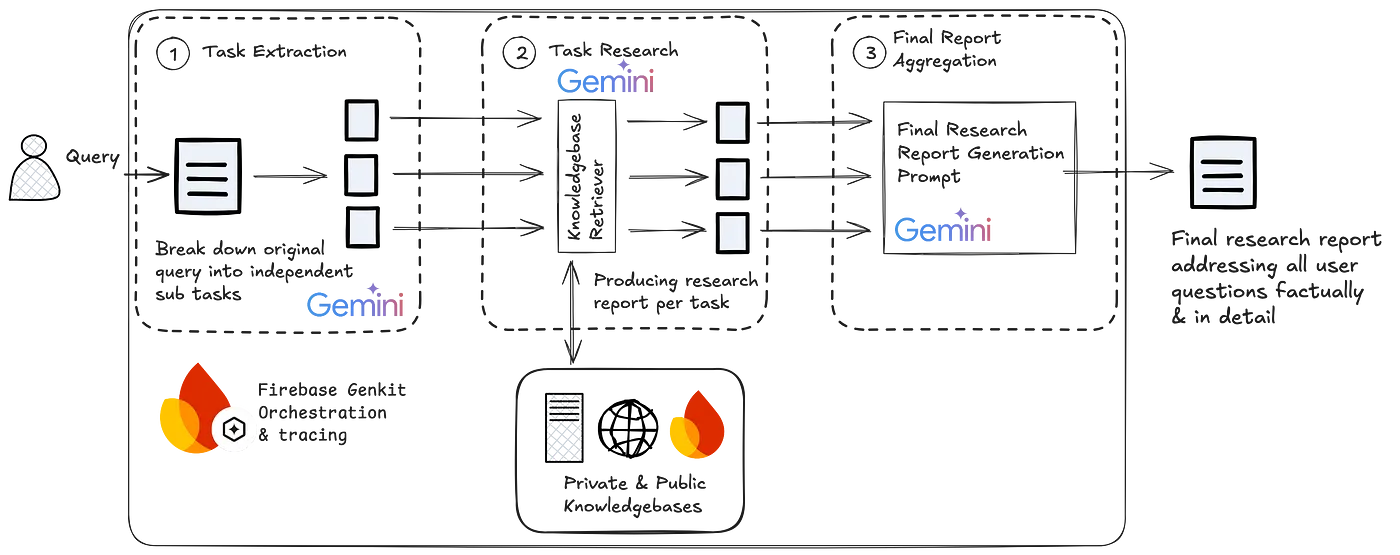
深度研究型生成AI应用设计模式
咱们就建起来吧!
拆解用户请求我们的起点是会议的记录。会议结束后,我们需要提取需要后续跟进的技术问题。我们需要以易于处理的格式提取这些问题。
这很容易通过一个简单的文本提示解决,输入为原始会议的记录。每个需要提取的问题都是一个问题形式的纯文本字符串。例如,一个问题可以是:“如何利用Gemini 2.5和Genkit构建自己的Deep Research Assistant?”因为我们希望助手可以处理任何会议记录,所以需要提取的任务数量应该是灵活的。因此,提取提示应该输出一个包含任意数量字符串的数组。
Genkit 允许我们在 Typescript 中为可调用的提示语定义输入和输出类型。任务提取提示语的输入是原始转录文本,因此是一个简单的字符串。我们定义提取提示语的输出(研究问题对象数组)如下:
const TaskSchema = z.object({
// 任务描述的模式定义
description: z.string(),
});const TaskArraySchema = ai.defineSchema(
'任务数组模式',
z.array(任务模式)
);提取提示不应过度工程化,提取问题相对来说是一个比较简单的工作。提示应该解释提取任务的背景和规则。LLM 不应该编造或遗漏任何出现在转录中的问题。此外,它应该简要总结问题,同时尽可能保持事实。为了实现这一点,我们将温度调至较低的位置。使用dotprompt,Genkit 可以轻松地定义提示、配置、输入和输出结构。
---
config:
temperature: 0.1
input:
schema:
transcript: string
output:
schema:
TaskArraySchema
---
<< 系统指令 >>
你是一个AI助手,负责从Google Cloud客户工程师(CE)与客户之间的对话中提取客户的技术问题。
分析对话记录并识别客户明确提出或暗示的核心技术问题、需求或痛点。重点关注那些突出客户对Google Cloud技术理解及需求的问题。
**务必包含CE承诺后续跟进的需要跟进的事项。**
**务必关注根据GCP文档可以具体回答的技术问题。**
**仅关注在会议期间尚未回答的问题。**
**不要涉及高层次的业务和使用场景问题。**
<< 输出格式 >>
输出格式为JSON数组,每个数组元素为一个任务,每个任务包括:
description: 客户的技术问题,简洁地从客户的角度表述。
<< 待分析的会议对话记录 >>
{{transcript}}
<< 分析的会议对话记录结束 >>
以下为任务(JSON数组):以下是任务(JSON数组):
为了组织提取步骤,我们定义了一个Genkit流程如下定义:定义了一个可调用的提示语。
导出一个名为 `taskExtractionFlow` 的常量,该常量定义了一个 AI 流程,该流程接收一个字符串输入,并输出一个任务数组。
const 任务提取提示 = ai.提示('任务提取');
const { 输出 } = 等待任务提取提示(
{
录音: 录音,
},
{
模型: gemini25ProPreview0325,
输出: { 架构: TaskArraySchema }
}
);
返回 输出;就这样,我们已经准备好了。第一步已经完成,现在可以为每次过去的会议动态抽取相关问题了。
并行任务研究接下来,我们需要对每一个问题进行研究。研究的复杂性会根据所需知识库的大小和类型有很大差异。我们的应用主要处理关于GCP架构决策和构建工具的问题。当在GCP上构建应用时,我们通常提供最新的信息,包括从GCP官方文档和GitHub存储库中的示例代码。
我们选择两个信息来源为LLM提供合适的上下文。
首先,假设我们已经建立了一个自定义的知识库,其中,有价值的部分GCP文档已经被转换成文本嵌入并存储在Firestore中。我们可以通过Firestore的向量索引功能来访问这些文本嵌入。
其次,我们包含Google可编程搜索引擎API,为每项研究任务模拟Google搜索。可编程搜索引擎API使我们能够访问Google索引的最新文档。它还允许我们将搜索引擎限制在指定网站及其子页面上。这使得可编程搜索引擎API成为一个无需每次文档更新都重建知识库的实时信息便利来源。
任务研究的输入是我们之前定义的研究任务。每个任务的研究结果应按以下方式记录:
const TaskResearchResponse = ai.defineSchema(
'TaskResearchResponse', // 定义任务研究响应模式
z.对象({ // 定义对象结构
answer: z.字符串(), // 答案: 字符串
caveats: z.数组(z.字符串()), // 注意事项: 字符串数组
docReferences: z.数组(z.对象({ // 文档引用列表
title: z.字符串(), // 标题: 字符串
url: z.字符串(), // URL: 字符串
relevantContent: z.字符串().可选(), // 相关内容: 字符串可选
})), // 结束文档引用列表定义
}) // 结束对象结构定义
);这种严格定义的研究报告允许我们将重要的注意事项和说明以及相关文档引用信息包含在汇总步骤中。这种结构对于保持对哪些文档产生哪些见解的追踪至关重要。这使我们能够在随后的邮件中与见解一同提供文档链接。
任务研究的重点是文档检索。Genkit 允许通过许多预构建的插件或自定义函数来连接知识库,这使得连接过程更加灵活。在这种情况下,我们定义了两个自定义检索器,具体来说,一个用于在我们的 Firestore 向量索引上进行向量相似度搜索,另一个则是通过可编程搜索引擎 API 进行搜索。
以下是我们的Firestore向量搜索Genkit检索器的定义如下。它使用服务器端动作(ssa)进行向量搜索。此ssa定义为Firestore SDK的一个封装层。更多代码细节请查看代码库。然后将我们知识库中的最近邻文档转换成一个由Genkit 文档组成的数组。
export async function createSimpleFirestoreVSRetriever(ai: Genkit) {
return ai.defineSimpleRetriever(
{
name: "simpleFirestoreVSRetriever",
configSchema: z.object({
limit: z.number().optional().default(5),
}).optional(),
// 指定如何从Document对象提取主内容
content: (doc: Document) => doc.text,
// 指定如何从Document对象获取元数据
metadata: (doc: Document) => ({ ...doc.metadata }), // 包括所有元数据
},
async (query, config) => {
const results = await vectorSearchAction(query.text, { limit: config?.limit });
const resultDocs: Document[] = results.map(doc => {
return Document.fromText(
doc.content || '', {
firestore_id: doc.documentId,
chunkId: doc.chunkId
});
});
return resultDocs;
}
);
}自定义搜索抓取器调用我们之前定义的可编程搜索引擎(PSE)。搜索引擎 API 只返回结果链接。因此,我们解析结果并通过提供的 URL 获取顶级搜索结果的内容。我们对原始 HTML 内容进行了一些基本清理,并将其转换成 Genkit 文档,以便进一步处理。您可以在代码仓库中找到完整的代码。
接下来,我们通过使用Gemini 2.5填充研究问题的回答模板来总结对每个研究问题的回答。摘要提示如下,简单且通用:
---
config:
temperature: 0.1
input:
schema:
task: string
format_instructions: string
output:
schema:
TaskResearchResponse
---
使用提供的 Google Cloud 文档上下文研究以下技术任务。
任务:{{task}}
回答时请:
1. 清晰回答技术问题
2. 包括相关步骤和配置
3. 注意任何重要的细节或最佳实践
4. 引用文档中的具体章节或部分
技术响应:最后,我们将各个任务的研究步骤合并到一个Genkit流程中。为了高效地处理,我们为每个任务的检索步骤创建一个Promise,并将研究汇总封装成一个异步函数。这样就实现了各个任务研究的并行处理。
export const taskReseachFlow = ai.defineFlow(
{
name: "taskReseachFlow",
inputSchema: TaskArraySchema,
outputSchema: TaskResearchResponseArray,
},
async (tasks) => {
console.log("正在运行任务研究流程...");
// 创建检索任务的Promise数组
const retrievalPromises = tasks.map(task => {
return ai.retrieve({
retriever: 'simpleFirestoreVSRetriever',
query: task.description, // 将任务描述作为查询
options: { limit: 10 }
});
});
const taskDocsArray = await Promise.all(retrievalPromises);
// 获取任务研究提示
const taskResearchPrompt = ai.prompt('taskResearch');
const generationPromises = tasks.map(async (task, index) => {
const docs = taskDocsArray[index];
const { output } = await taskResearchPrompt(
{
question: task.description
},
{
docs: docs,
output: { schema: TaskResearchResponse }
}
);
return output;
});
const researchResults = await Promise.all(generationPromises);
return researchResults; // 返回研究结果
}
);此流程返回由研究结果对象组成的数组。这种标准化格式使得结果在下一个工作流步骤中最易于处理。
研究结果的汇总我们已经走了很长一段路!我们成功地提取了研究任务的内容,并建立了一个高效的流水线,可以并行处理任何数量的任务,同时利用多个公开和私有的知识库。剩下的就是将我们的发现整合成有用报告的格式。我们的工作示例是撰写技术跟进邮件。利用这些研究报告,让我们制定一个文本提示,以利用这些研究报告撰写一封简洁的邮件草稿,提供答案及文档资源。
研究报告的聚合提示会根据不同的用例有很大差异。在我们使用的所有文本提示中,这个提示应该是最详细的,因为我们需要定义期望的输出格式、语气等。由于我们主要是在调整写作风格,采用多轮提示的方法在这里也适用。需要详细的提示是因为我们需要定义期望的输出格式、语气等。通过提供干净且多样化的示例,模型将更容易理解和遵循你的风格要求。
我们用下面这个提示来发送技术跟进邮件吧。
---
配置:
temperature: 1
输入:
schema:
任务: 字符串(任务内容)
研究: 字符串(研究内容)
输出:
schema:
邮件: 字符串
---
根据技术研究结果,生成一封专业的跟进邮件给客户。
原始任务:
{{tasks}}
研究发现:
{{research}}
邮件要求:
1. 以简短的会议参考和摘要开头
2. 简要且简洁地回答每个技术问题,尽量保持每个要点不超过一句
3. 必要时链接到具体的文档部分,但仅在合适的情况下使用
4. 维持专业但友好的语气
5. 以下一步措施或进一步澄清的提议结束
以下是邮件简洁程度的示例。
请在你的邮件中与示例中的细节水平相匹配。
<< 示例邮件开始:>>
请参阅代码库中的示例邮件
<< 示例邮件结束:>>
生成的邮件:我们应该最后将邮件生成提示语整合到相应的流程中(code in the repo)。
这标志着深入研究流程的完成。
此 Deep Research 工作流的完整代码可在 GitHub 上找到:https://github.com/jakobap/aaron/tree/main。分叉该仓库并看看具体实现细节,然后将其应用于你的研究任务中。
结论和下一步深度研究是Gen AI应用程序架构中最实用的设计模式之一。深度研究是标准RAG系统的下一代进化。我确信在接下来的1到2年内,日常知识工作的许多任务将通过深度研究应用程序加速或自动化。最初,这个项目的设想是自动化我工作中的相当一部分。这已经惊人地好用。
任何深度研究员的实际效用将极大地取决于你能提供访问的相关知识库。如果你需要进一步调整结果,检索质量和任务研究报告的整理是额外的性能调整因素。最后,最终报告的生成需要针对每个用例进行定制。所需输出格式在不同知识任务之间会有很大差异。整理最终报告至关重要,尤其是在向最终用户展示深度研究员的成果时。你可以生成最佳且最相关的工作任务研究结果,但若最终报告不符合用户需求,整个深度研究员将失去其价值。
当然,我们生活在大语言模型代理的时代。我们讨论的实现遵循了一个大语言模型的工作流程,而不是依赖于代理来做决策。在大多数情况下,这样做就足够了。我们也可以为最复杂的任务实现一个代理循环流程。例如,任务研究可以迭代每个任务研究报告,直到研究足够深入为止。然而,代理功能往往会使架构变得过于复杂,而这些架构通过工作流同样能达到(甚至更好的)效果。因此,我们将代理实现留作下次博客的内容。
你有什么关于深度研究模式的经验吗?你能自定义它吗?你打算用它来自动化日常工作中的哪些任务吗?





