
用 Docker 在本地运行大型语言模型(LLMs)?没错,你没有听错。现在 Docker 不仅能运行容器镜像,还能做更多。借助 Docker Model Runner,你可以在本地运行和互动大型语言模型(LLMs)。
显然,我们在开发方面已经看到了向AI和生成式AI的巨大转变。开发一个生成式AI驱动的应用程序并不容易,从成本到设置都有诸多麻烦。正如往常一样,Docker 一如既往地出手相助,让它擅长的事情更加简单:让生成式AI开发变得更简单,这样开发人员可以更快地构建和发布产品和项目。我们可以在本地机器上直接运行AI模型!是的,它支持在没有容器的情况下运行模型。目前,Docker Model Runner 处于Beta阶段,仅适用于带有Apple Silicon的Docker Desktop for Mac,并且需要 Docker Desktop版本 4.40 或更高版本。
在这篇文章中,我们将探讨Docker模型运行器的优点以及如何在不同场景下使用它。那我们就直接开始吧!
Docker 模型的好处-
开发者的流畅体验:作为开发者,我们最不喜欢的一个方面就是频繁地在不同任务间切换上下文和使用多种工具,而Docker则简化了这一切,降低了学习曲线。
-
GPU 加速:Docker Desktop 直接在您的主机上运行 llama.cpp。推理服务器可以利用 Apple 的 Metal API,直接访问 Apple Silicon 的 GPU 加速功能。
-
OCI 资源文件:将 AI 模型存储为 OCI 资源文件,而不是以 Docker 图像的形式存储。这样可以节省磁盘空间,并减少不必要的数据提取。这样做不仅能提高兼容性,还能增强适应性,因为这是业界广泛采用的标准格式。
- 全部本地化:无需处理云LLM的API密钥问题、限流、延迟等麻烦,本地绑定产品,无需支付昂贵的费用。更重要的是,数据隐私和安全也得到了更好的保障。llama.cpp会根据需要动态加载模型到内存中。
确保你已经安装了 Docker Desktop v4.40 或更高版本。安装后,请进入 设置 > 开发中的功能 并开启 开启 Docker 模型运行器。你还可以启用 启用主机端 TCP 支持 以便从你的本地主机进行通信(我们将在下面演示如何使用该功能)。
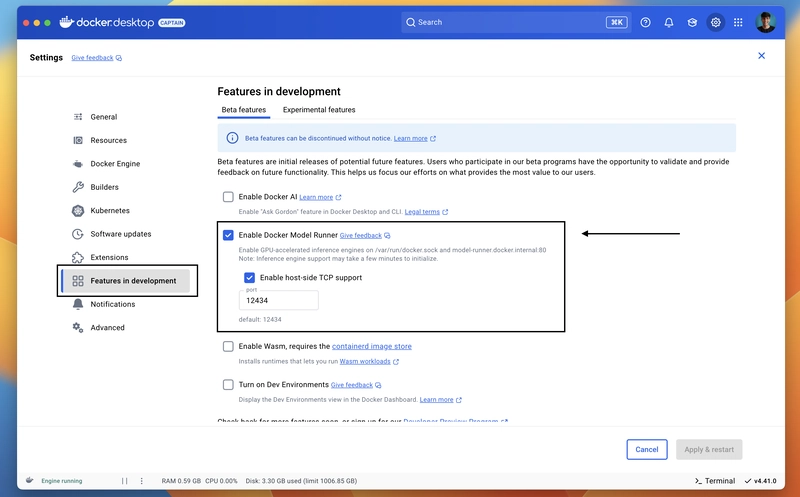
一旦完成,请点击应用并重启系统,我们就完成了。为了测试是否正常工作,打开任意终端,在终端中输入docker model,你会看到所有可用命令的列表,这表明一切设置都已成功。
所以,要与这些大型语言模型交互,我们目前有两种方法(请继续关注),一种是通过命令行界面(CLI),另一种是通过API(兼容OpenAI)。使用CLI操作API非常直观。我们可以在运行的容器内部或本地主机上直接通过API与它们交互。下面让我们详细看看这些方法。
从命令行 CLI
如果你用过 Docker CLI(几乎是每个用过容器的开发者都用过的),并用过诸如 docker pull、docker run 等命令,Docker 使用了类似的模式,唯一的不同在于增加了一个名为模型的子命令,因此,要拉取一个模型,可以使用命令 docker model pull <模型名称>;若要运行已拉取的模型,则使用 docker model run <模型名称>。这样使事情变得简单得多,因为不需要为新工具学习新命令。
下面是一些目前支持的命令。还有一些即将加入(其中一些是我特别喜欢的)。敬请关注!
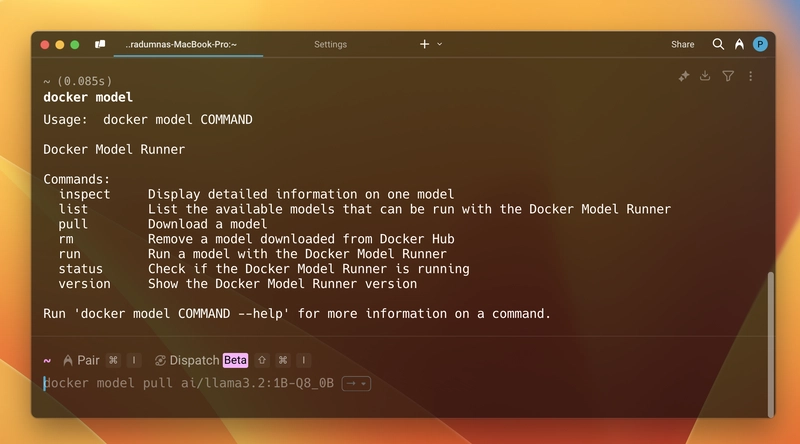
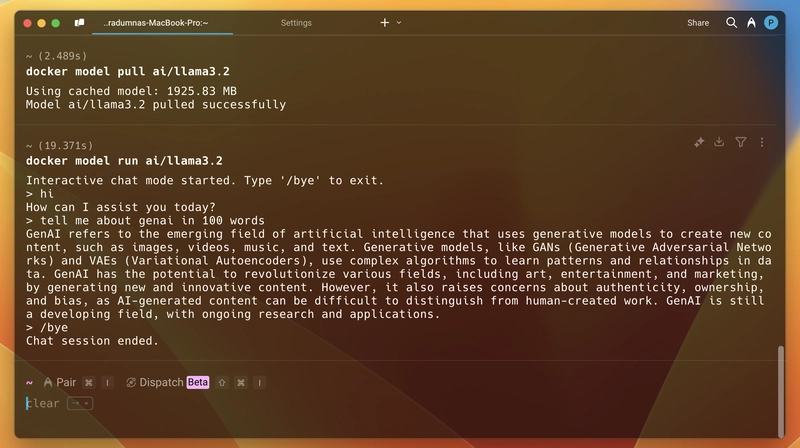
现在,要运行一个模型,我们首先需要将其拉取下来。例如,我们将运行 llama3.2。您可以在 Docker Hub 的 GenAI 目录 中找到所有可用的模型。打开终端并运行 docker model pull ai/llama3.2。拉取时间会根据模型大小和您的网速而有所不同。拉取完成后,运行 docker model run ai/llama3.2,它将启动一个类似于正常聊天机器人或 ChatGPT 的聊天模式。完成后,只需输入 /bye 即可退出交互式聊天模式。附上一张截图:
看这个终端截图: 如图所示
来自 OpenAI 的 API。
Model Runner的一个令人惊叹的功能是它支持与OpenAI兼容的端点。我们可以多种方式与API互动,比如在运行中的容器里,或者从主机通过TCP或Unix套接字访问。
我们将看到一些不同的示例,但是在那之前,这里列出了可用的端点。无论我们是通过容器内部还是主机来与 API 交互,这些端点都将保持不变,唯一变化的是主机。
# OpenAI 接口示例
GET `/engines/llama.cpp/v1/models`
GET `/engines/llama.cpp/v1/models/{namespace}/{name}`
POST `/engines/llama.cpp/v1/chat/completions`
POST `/engines/llama.cpp/v1/completions`
POST `/engines/llama.cpp/v1/embeddings`
注意:您可以省略 llama.cpp 这部分。全屏,退出全屏
容器内的
在容器内部,我们将使用http://model-runner.docker.internal作为基础的URL,并可以访问任何上述提到的端点。例如,我们将访问/engines/llama.cpp/v1/chat/completions端点来进行会话。
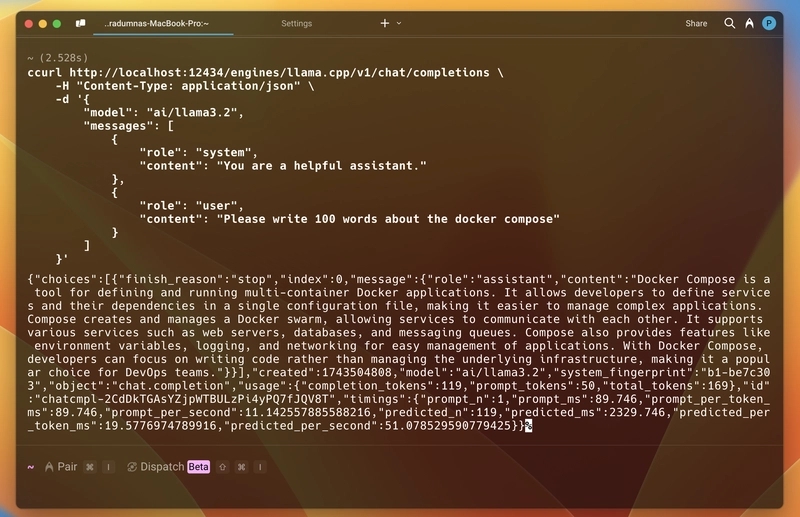
我们将使用 curl。你可以看到它使用了类似的结构,与 OpenAI API 类似。确保你已经拉取了想要用的模型。
curl http://model-runner.docker.internal/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/llama3.2",
"messages": [
{
"role": "system",
"content": "你是一个乐于助人的助手。"
},
{
"role": "user",
"content": "请写一篇大约100字的短文介绍docker compose。"
}
]
}'切换到全屏 退出全屏
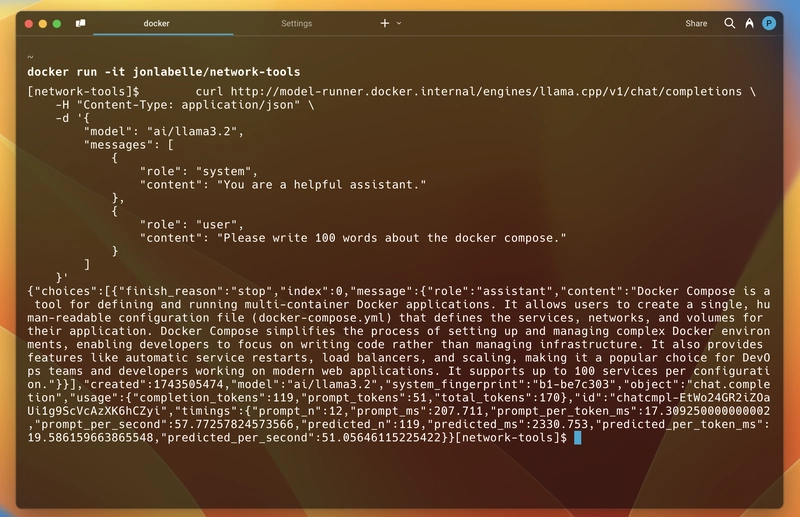
所以,为了测试它是否能在运行中的容器内部工作,我以交互模式运行了 jonlabelle/network-tools 容器镜像,并使用上述 curl 命令向 API 发送请求。它成功了。
如下面的回复所示,回复以 JSON 格式给出,包括生成的消息、token 使用量、模型详情和响应时间,符合标准格式。
 (这是一张终端的界面截图。)
(这是一张终端的界面截图。)
主持人说的
正如我之前所说,要与A进行互动,请确保已启用TCP。你可以访问 localhost:12434 来检查是否正常工作。你会看到一条消息,显示 Docker 模型运行器。服务正在运行。
这里,我们将使用http://localhost:12434作为基础网址,并且遵循相同的端点。同样地,对于curl命令,我们只需将基础网址替换为http://localhost:12434,其他内容保持不变。
curl http://localhost:12434/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/llama3.2",
"messages": [
{
"role": "system",
"content": "你是个乐于助人的小伙伴。"
},
{
"role": "user",
"content": "请写一个关于Docker Compose的100字介绍。"
}
]
}'全屏,退出全屏
试试在终端里运行一下
它将以与另一个相同的 JSON 格式返回响应,包括生成的消息、使用的 Token 数量、模型信息以及响应的耗时。
有了这种 TCP 支持,我们不再局限于与容器内的应用程序交互,而是可以与任何地方的应用程序进行交互。
关于博客的内容就说这么多。你可以在官方文档里了解更多关于Docker Model Runner的信息。请关注Docker的公告,会有更多新内容发布。一如既往,很高兴你能读到最后——非常感谢你的支持。我经常在Twitter分享一些小贴士(这永远都是Twitter :))。你也可以在那里联系我。





