
时间序列数据对组织来说非常重要,因为它使它们能够分析重要的实时和历史指标。通过展示时间趋势,时间序列数据帮助基于旧数据和新数据的关系做出决策。毫不奇怪,时间序列分析是一个得到了广泛发展的数据分析领域。
然而,数据只有在容易获取时才有价值。这正是能够为时序数据快速搭建仪表板对于希望在团队间展示其分析的组织来说,这就像一个倍增器。
在这篇文章里,我们将介绍 Timescale 的实时聚合,以加快对时间序列数据的聚合查询。此外,我们还将介绍如何构建一个利用 TimescaleDB 特性来处理空气质量数据的示例应用。
连续聚合视图是Timescale对PostgreSQL物化视图的增强版本。它们会像物化视图一样对您的数据进行预聚合,并在后台自动刷新以确保在新数据被添加或旧数据被修改时,数据始终是最新的。因此,无论何时查询连续聚合视图,都将获得最新的结果。
利用连续聚合,TimescaleDB 可以为 PostgreSQL 中用于时间序列的数据启用实时仪表板。通过提升 PostgreSQL 在时间序列数据分析上的性能,TimescaleDB 可以帮助你快速生成仪表板,即使面对大量数据也能做到。
但在我们实际操作连续聚合之前,让我们看看它们内部是如何运作的。
连续聚合的工作原理连续聚合的设计受到了PostgreSQL物化视图的启发,但连续聚合更像是加强版的物化视图。在底层,物化视图实际上是存储聚合查询结果的表,以便可以在无需重新计算的情况下访问到,实际上就是缓存了查询结果。
物化视图的主要问题——尤其是在频繁收集数据的情况下,,比如处理时间序列数据——是每当添加新的数据时,它们就会变得不准确。你可以手动刷新物化视图,但这将重新计算整个汇总,从而减慢汇总过程。
连续聚合不仅能存储查询结果,并在设定的时间间隔自动更新为最新的数据,还会保存旧数据更改的日志,并在用户通过刷新策略设定的计划更新过程中,逐步更新那些已更改的部分。
总而言之,连续聚合功能可以在保持与数据库更新一致性的同时,利用 PostgreSQL 物化视图的计算能力,这对于大规模构建 PostgreSQL 仪表盘来说是一个强大的改进。
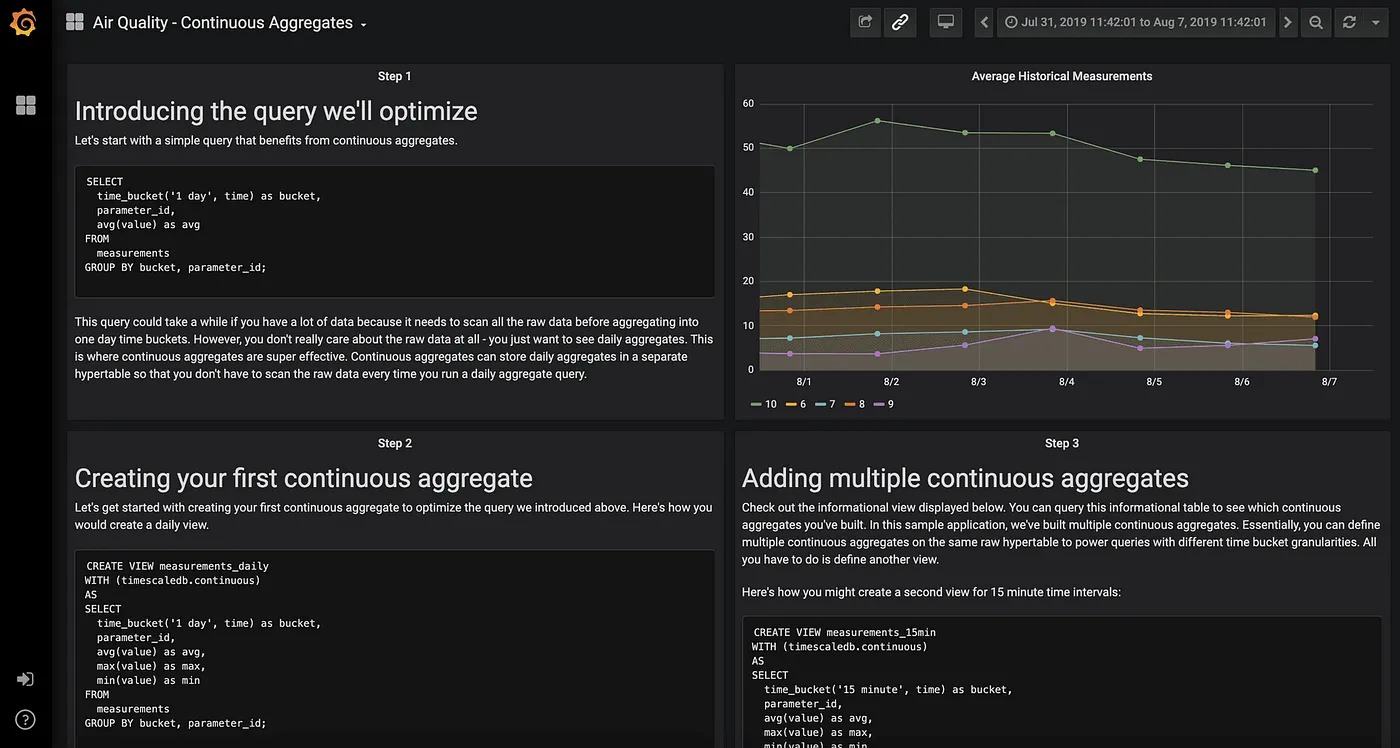
一个带有连续聚合的时间序列仪表板示例让我们通过一个示例应用程序来了解连续聚合技术的工作原理。我们之前在一个关于使用 time_bucket() 函数简化时间序列分析的帖子中介绍了这个应用程序,在之前的帖子中,我们展示了如何使用 TimescaleDB 的 time_bucket() 函数来构建灵活的时间序列图表。
[time_bucket()](https://docs.timescale.com/latest/api?ref=timescale.com#time_bucket) 和 [time_bucket_gapfill()](https://docs.timescale.com/latest/api?ref=timescale.com#time_bucket_gapfill) 是 TimescaleDB 中两个重要的时间序列函数。time_bucket() 用于将任意大小的时间段进行聚合,而当时间桶中有数据缺失或间隙时,gapfill() 就显得尤为重要。这种情况在每秒捕获数千个时间序列数据时非常普遍。这两个函数一起对于分析和可视化时间序列数据来说是必不可少的。
该示例应用程序是用Python编写的。它主要抓取Open AQ(空气质量)API的数据,并解析结果,存储从英国各地空气质量传感器收集的所有测量数据。你可以在此查看代码 这里。
为了让你快速了解连续的数据聚合非常有用,这里有一个我们在空气质量例子中常使用的查询:
SELECT
time_bucket('1 day', time) AS 时间桶,
parameter_id,
AVG(value) AS 平均,
MAX(value) AS 最大,
MIN(value) AS 最小
FROM
measurements
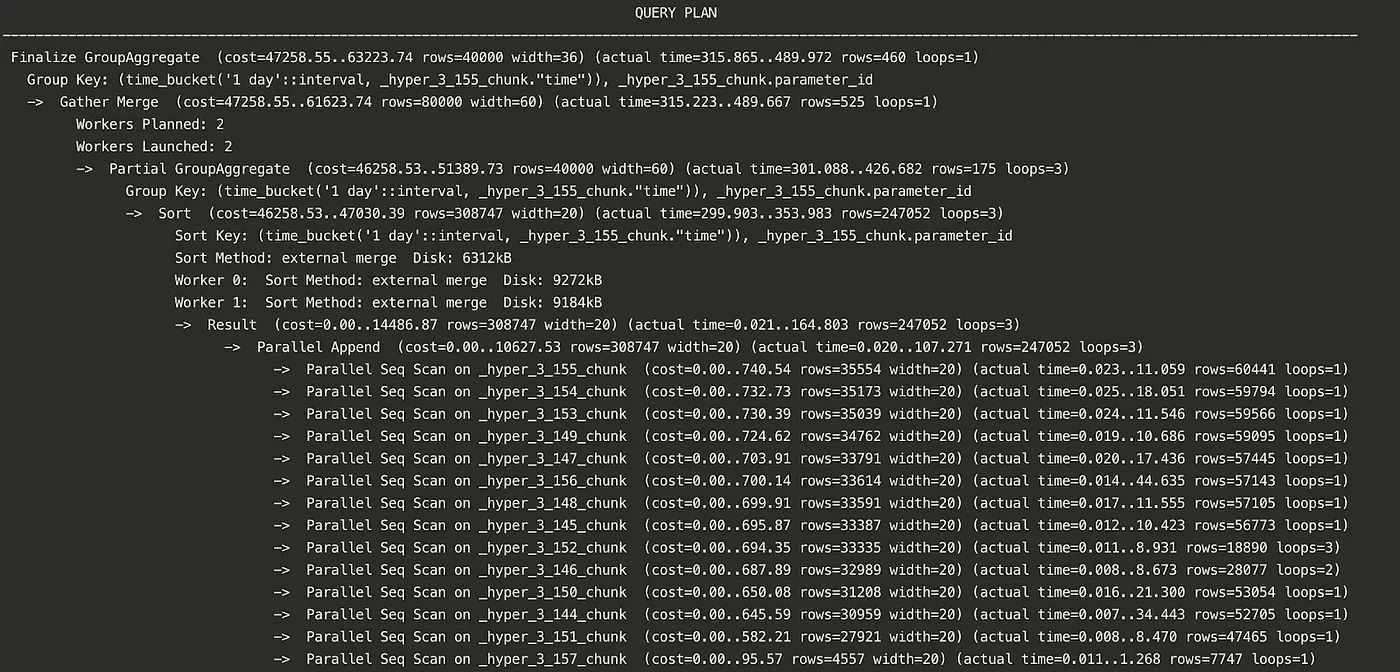
GROUP BY 时间桶, parameter_id;你会注意到我们的查询横跨所有时间,并将数据按一天的间隔进行分桶。一天间隔的分桶计算以及从磁盘读取所有这些数据的开销都比较大。我运行这个查询的表目前大约有70万行数据。你可以想象,随着数据量的增加,这个查询可能会变得越来越慢。
以下是一个查询计划示例。看看要计算这个查询需要做多少工作!
为了加快这个进程,我写了一个连续聚合表。
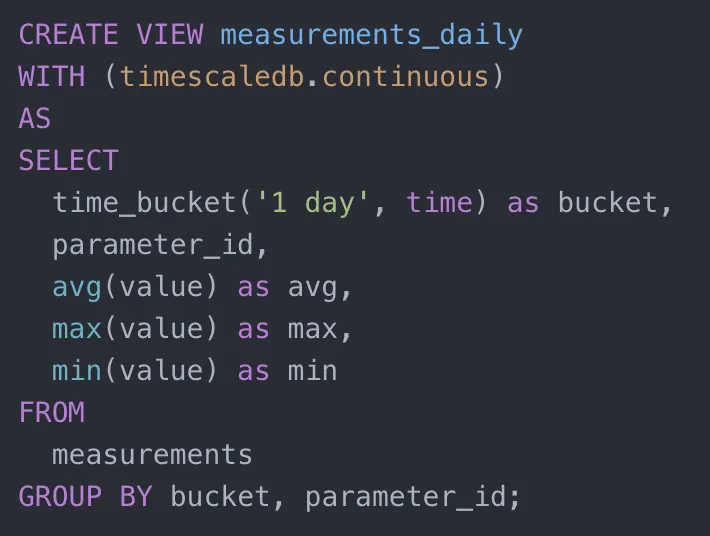
现在,让我们尝试直接查询 measurements_daily 表中的相同数据。这样就不再需要扫描那么多数据,查询计划因此大大简化。
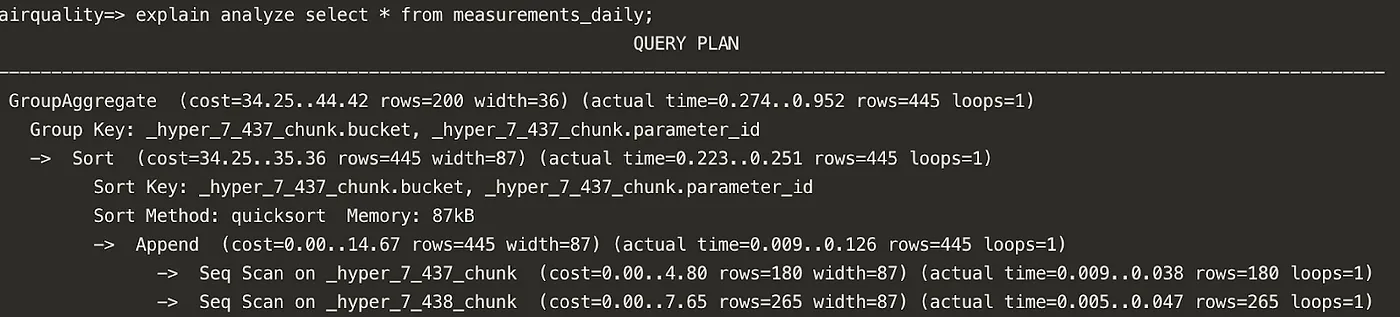
默认情况下,连续聚合表从版本 2.11 开始仅被物化。
timescaledb.materialized_only 默认为 true 状态,但当设置为 false 时,它可以将实时数据与原始的超表(hypertable)中的数据结合,并与连续聚合的 materialized 部分相结合。
看看在官方文档中的所有选项。
创建连续聚集后,如果你使用 WITH NO DATA 选项,它不会更新或生成新的数据,并且会等待刷新数据的调用。Timescale 提供了刷新数据的策略,允许我们定义刷新物化视图的时间间隔。
SELECT add_continuous_aggregate_policy('measurements_daily',
start_offset => INTERVAL '1月',
end_offset => INTERVAL '1 天',
schedule_interval => INTERVAL '1 小时');创建策略政策后,您可以在 timescaledb.jobs 视图中查看一下。
SELECT * FROM timescaledb_information.jobs;
job_id | 1001
application_name | 刷新连续聚合策略 [1001]
schedule_interval | 01:00:00
max_runtime | 00:00:00
max_retries | -1
retry_period | 01:00:00
proc_schema | _timescaledb_internal
proc_name | policy_refresh_continuous_aggregate
owner | postgres
scheduled | t
config | {"start_offset": "1 month", "end_offset": "1 day", "mat_hypertable_id": 2}
next_start | 下一次开始时间
hypertable_schema | _timescaledb_internal
hypertable_name | _materialized_hypertable_2
check_schema | _timescaledb_internal
check_name | policy_refresh_continuous_aggregate_check还有可以调用的(刷新连续汇总)函数,用于将特定时间范围内的数据转换为实体数据。策略的优势在于它们可以在后台运行,像工作者一样,随着新数据不断到来而持续更新。
如果数据改变,该策略也会跟踪需要更新的部分,并在下次刷新时一起处理,从而管理和更新连续汇总。
下一步:在这种情况下,连续聚合功能可以大大减少运行历史聚合查询所需的磁盘吞吐量和计算需求,是一项非常有用的工具。
如果你准备好了,可以试试看这个教程。如果你刚接触TimescaleDB,可以免费试用,不需要信用卡此处链接。
本文由 Diana Hsieh、Ana Tavares 和 Jônatas Davi Paganini 撰写,最初发布于2023年12月19日的Timescale 官方博客的此处,最后更新于2024年1月9日。





