
人工智能领域的景观正在迅速演变,而检索增强生成(RAG)成为改变游戏规则的存在。通过将强大的语言模型如LLaMA与高效的检索机制相结合,可以使生成基于事实数据,从而生成高质量、上下文感知的响应。在这篇文章中,我们将探讨如何使用LLaMA(通过Ollama)在Google Colab中实现RAG。本分步骤指南涵盖数据输入、检索和生成三个步骤。
你知道什么是检索增强生成(RAG)吗? 概述RAG 是一种混合方法,通过在生成过程中整合外部知识来源来增强大型语言模型(LLMs)。这确保了响应的准确性并基于真实数据,使 RAG 成为问答系统、文档摘要生成和聊天应用等应用的有效技术手段。
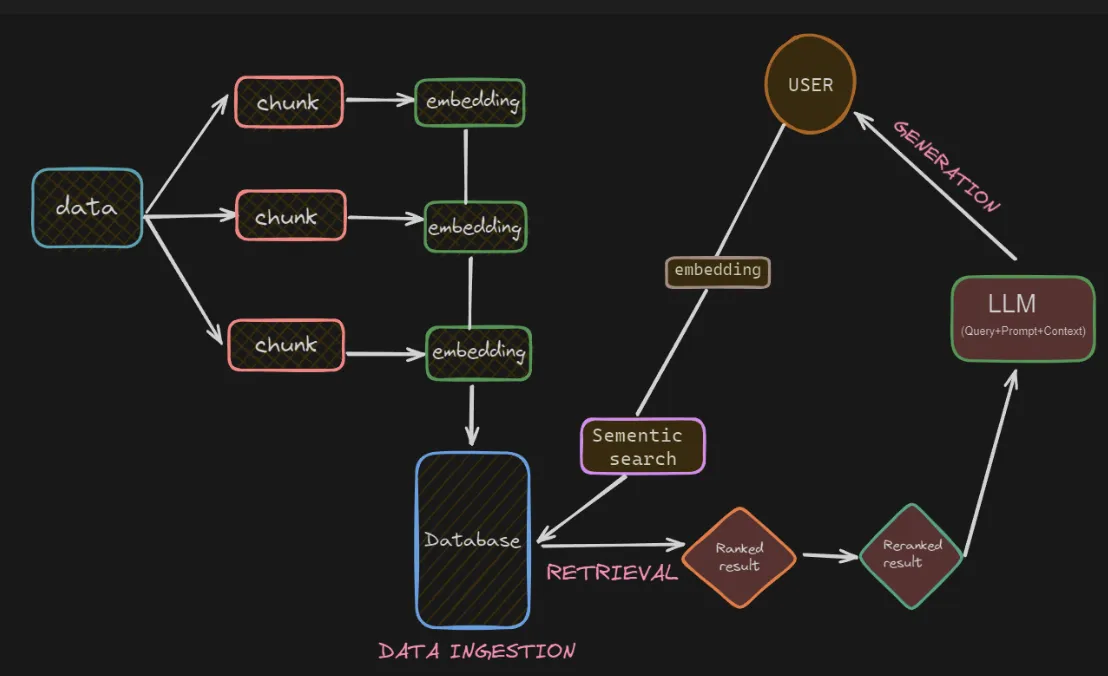
RAG的工作方式RAG系统主要有三个阶段:
数据导入 :
- 首先,收集并预处理文档,比如PDF、网页或数据库。
- 将文档分成更小、可检索的片段,比如使用文本分割器。
数据提取
- 将文档片段存储为向量嵌入在像FAISS这样的向量数据库(vector database)中。
- 根据查询,通过语义相似度检索最相关的片段。
数据生成:
(简单来说,就是数据的制作过程)
- 将检索到的信息提供给大模型,生成基于事实的连贯回答。
- 大模型利用检索到的信息以及其内部知识。
- 准确性:通过以事实数据为基础来减少幻觉。
- 可扩展性:使用向量数据库高效处理大规模数据集。
- 灵活性:与各种大型语言模型和向量数据库工作。
注:LLaMA是Large Language Model Meta AI的简称。
概览
LLaMA,由Meta AI(原Facebook AI)开发,是一系列大型语言模型家族,旨在使先进的自然语言处理技术更为普及。与GPT模型相比,LLaMA更适用于小规模环境,因此对于研究人员和开发者来说更易获取。
主要特点- 高效扩缩
- LLaMA 在不需要大规模基础设施的情况下表现优异。
- 旨在使用有限的计算资源进行高效的微调和推断。
- 多功能
- 支持诸如文本摘要、翻译、情感分析和问答等多种任务。
- 型号和尺寸 :
- LLaMA 有多种大小的版本,从70亿到65亿参数量,开发人员可以根据使用场景和计算限制选择合适的版本。
- 开放存取:
- Meta发布了LLaMA,使其成为一个开源项目,让研究社区能够实验和创新
你知道奥拉玛是什么?
概述Ollama 是一个旨在简化 LLaMA 模型的部署和使用过程的框架工具。它使开发人员可以本地运行或在云端环境中部署 LLaMA 模型,从而使这些模型更易于在实际应用中使用。
功能特点简单设置:
- Ollama 提供了预配置的环境,可以运行 LLaMA 模型,无需复杂的设置步骤。
- 它支持在各种平台上的部署,包括如 Google Colab 等平台。
模型部署
用户可以通过 Ollama 将 LLaMA 模型作为 API 来使用,从而让这些模型更容易集成到各种应用程序中。
自定义互动方式 :
- 支持微调和定制,以适应特定任务的需求。
性能优化:
- 包含有助于高效推断的工具,即使在硬件资源受限的环境中,如内存有限的GPU上也能运行得很好。
LangChain 是一个用于使用大语言模型和外部工具构建应用程序的框架。Ollama 将 LLaMA 与 LangChain 连接,使开发人员能够进行开发。
- 在本地或云上部署 LLaMA 模型。
- 使用 LangChain 链(如 RetrievalQA),来运行 RAG 流程。
- 事实准确性:RAG通过检索相关信息确保回答基于事实。
- 效率:LLaMA通过减少计算开销提供高性能,确保高效运行。
- 易部署性:Ollama简化了在实际应用中部署和运行LLaMA模型的过程。
- 聊天机器人:基于企业知识库的。
- 客户支持:使用公司手册或政策回答常见问题:
- 教育:提供个性化的学习辅助:
- 医疗:为医疗专业人员总结和检索患者数据:
在我们开始编写代码之前,请确保您已经安装了以下项目:
!pip install langchain # 安装langchain库
!pip install -U langchain-community # 更新安装langchain-community库
!pip install sentence-transformers # 安装sentence-transformers库
!pip install faiss-gpu # 安装faiss-gpu库
!pip install pypdf # 安装pypdf库我们首先用PyPDFLoader加载一个PDF,然后将其分割成较小且有重叠的片段,从而提高检索的准确性。
从langchain.document_loaders导入PyPDFLoader模块
从langchain.text_splitter导入CharacterTextSplitter类
# 加载文件
loader = PyPDFLoader("/content/got.pdf")
documents = loader.load()
# 将文件分割成小块
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=30, separator="\n")
docs = text_splitter.split_documents(documents=documents)FAISS,Facebook AI 相似搜索是一个用于向量相似搜索的灵活高效的库。它支持大规模和快速的嵌入检索。
选择模型类型
您要选择什么样的模型?
我们使用sentence-transformers/all-mpnet-base-v2,这在各种文本任务中表现出色。若需权衡速度和准确性,还可以选择BGE或MiniLM等替代方案。
导入langchain.embeddings的HuggingFaceEmbeddings
导入langchain.vectorstores的FAISS
# 加载嵌入模型:
embedding_model_name = "sentence-transformers/all-mpnet-base-v2"
model_kwargs = {"device": "cuda"}
embeddings = HuggingFaceEmbeddings(
model_name=embedding_model_name,
model_kwargs=model_kwargs
)
# 创建向量仓库
vectorstore = FAISS.from_documents(docs, embeddings)
# 保存并重载向量仓库
vectorstore.save_local("faiss_index_")
persisted_vectorstore = FAISS.load_local("faiss_index_", embeddings, allow_dangerous_deserialization=True)
# 创建检索对象
retriever = persisted_vectorstore.as_retriever()LLaMA(大型语言模型元AI(LLaMA))是一款专为各种NLP任务设计的前沿模型。Ollama简化了在类似Google Colab这样的受限环境中部署LLaMA模型的过程。
安装 Ollama
运行下面的命令来安装并配置 Ollama。
!pip install langchain_ollama # 安装langchain_ollama库
!pip install colab-xterm # 安装colab-xterm库
%xterm # 打开xterm终端
curl -fsSL https://ollama.com/install.sh | sh # 从ollama官网下载并安装脚本
ollama serve & ollama pull llama3.1 # 启动ollama服务并拉取llama3.1模型启动LLaMA
使用LangChain Ollama集成,我们加载了该 LLaMA 模型。
from langchain_community.llms import Ollama
# 创建 LLaMA 模型
llm = Ollama(model="llama3.1")
# 测试一个样例提示
response = llm.invoke("告诉我一个笑话")
print(response)我们将检索器和LLaMA结合成一个RetrievalQA(检索问答)链。从而实现基于摄入文档的互动问答功能。
从langchain.chains导入RetrievalQA模块
# 创建一个RetrievalQA实例
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
# 交互式的查询循环
while True:
query = input("输入你的查询(输入'退出'以退出):\n")
if query.lower() == "退出":
break
result = qa.run(query)
print(result)- 研究助理:快速检索学术论文或书籍中的相关信息。
- 客户支持:构建一个通过参考公司政策或手册来回答常见问题的聊天机器人。
- 知识管理:从大型数据集中总结并提取关键洞察。
- 模型选择:对于大型数据集,推荐使用强大的嵌入模型如MPNet;对于需要更快处理速度的情况,建议使用MiniLM。
- 数据分块:根据数据集和应用场景调整分块大小和重叠。
- 安全考量:在处理敏感信息时,确保符合数据隐私规定。
通过 RAG 和 LLaMA,由 Ollama 提供支持,你可以构建强大且可靠、高效且理解上下文的 NLP 应用程序。FAISS 用于检索,LLaMA 用于生成,这种组合为许多行业提供了灵活的解决方案。快来试试吧,让您的创造力引导您的实现!
想了解更多:
- Sentence Transformers
- 句子转换器
- LangChain 使用说明





