
Ragas 是一个用来评估检索增强生成(RAG)系统性能的框架,这些系统结合了语言模型(LLMs)和外部知识检索功能。它提供了一种结构化的评估方法,可以通过一系列的指标来评估 RAG 管道中的生成器和检索器组件,而不需要大量的标注数据集。
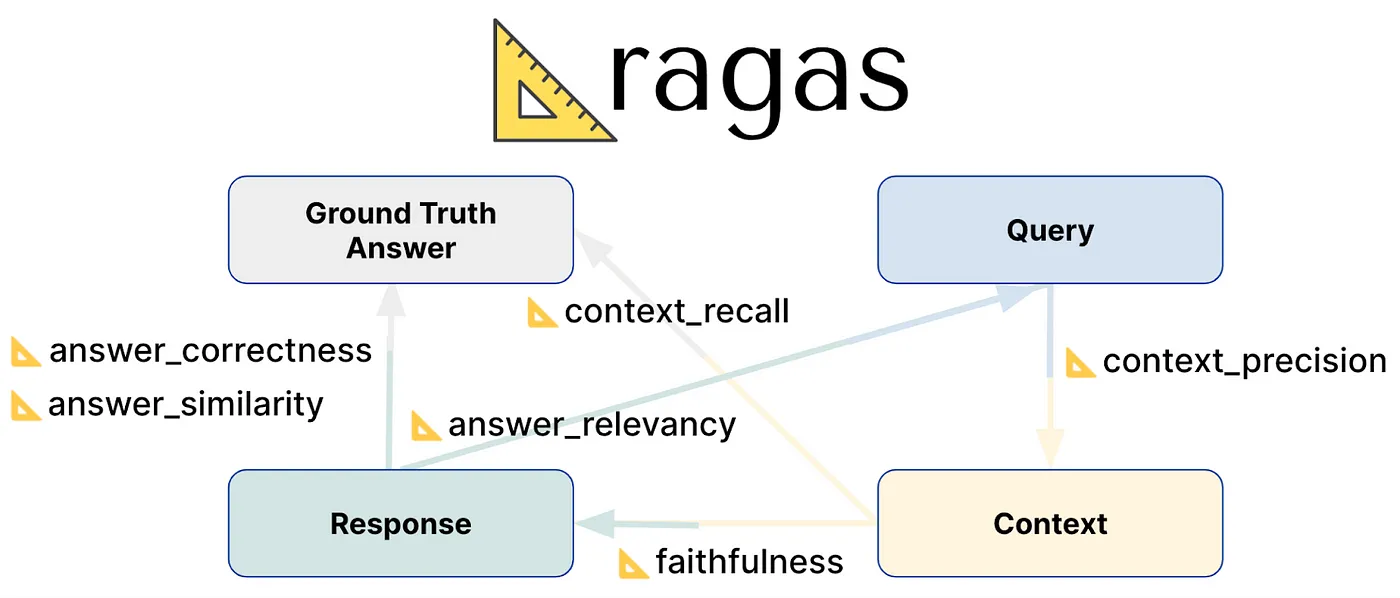
Ragas 提供了多种指标来评估您的 RAG 系统的不同方面:
- Retriever:提供
context_precision和context_recall以衡量您的检索系统的性能。 - Generator(LLM):提供
faithfulness以衡量幻觉,并提供answer_relevancy以衡量答案与问题的相关性。 - Faithfulness — 测量答案在给定问题上下文中的忠实度。
- Context_precision — 测量检索出的上下文与问题的上下文精确度,反映检索管道的质量。
- Answer_relevancy — 测量答案与问题的答案相关度。
- Context_recall — 测量检索器检索所有必要信息以回答问题的上下文召回率。
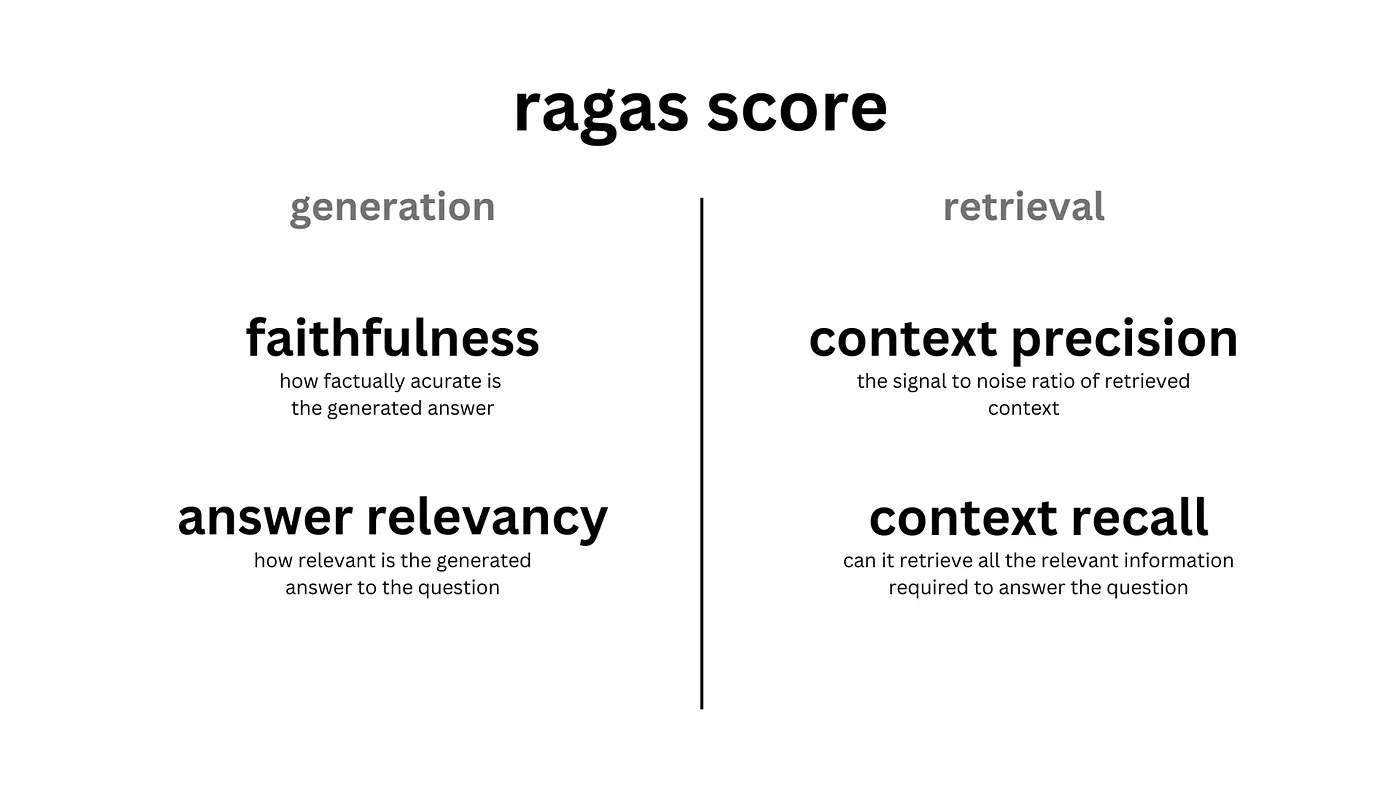
Ragas框架使用四个主要指标对RAG管道进行全面评价。
_Faithfulness:_此指标评估生成答案的事实准确性,通过检查答案中的陈述是否得到提供的上下文的支持。它是通过分析生成的答案中的每个陈述与上下文的有效性来计算的。_Answer Relevancy:_此指标衡量生成的答案与问题的相关性和直接关联性。_Context Relevancy:_此指标评估检索上下文的信噪比,确定回答问题所需句子数量与检索到句子总数的比例。_Context Recall:_此指标检查生成答案所需的所有必要信息是否都能在检索到的上下文中找到。它将地面实况答案中的陈述与检索到的内容进行比较。
这测量了生成的答案与给定上下文之间的事实一致性。它根据答案和检索的上下文进行计算。答案被归一化到0到1的范围内,数值越大表示一致性越高。
生成的答案被认为是准确的,如果可以从中推断出所有陈述。为了确认这一点,首先会从答案中识别出一系列声明。然后,将这些声明与上下文比对,查看是否可以从中推断出这些声明。评分将根据这些检查给出。
from ragas.database_schema import SingleTurnSample
from ragas.metrics import Faithfulness
sample = SingleTurnSample(
user_input="When was the first super bowl?",
response="The first superbowl was held on Jan 15, 1967",
retrieved_contexts=[
"The First AFL–NFL World Championship Game was an American football game played on January 15, 1967, at the Los Angeles Memorial Coliseum in Los Angeles."
]
)
scorer = Faithfulness()
await scorer.single_turn_score(sample)爱因斯坦是什么时候在哪里出生的?
背景:阿尔伯特·爱因斯坦(1879年3月14日出生的)是一位德国出生的理论物理学家,被广泛认为是有史以来最伟大和最有影响力的科学家。
准确回答:爱因斯坦出生在1879年3月14日的德国。
爱因斯坦的出生信息:爱因斯坦于1879年3月20日出生在德国。
让我们来看看如何通过低评分来计算忠实度。
步骤 1: 把生成的答案拆成单独的句子。
声明:
- 爱因斯坦出生在德国。
- 爱因斯坦出生于1879年3月20日。
步骤2:对于每个生成的句子,检查它是否可以从提供的信息中推导出来。
- Statement 1: 是
- Statement 2: 不是
第三步: 使用上面的公式计算忠实性。
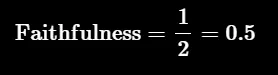
评估标准“答案相关性”(例如,答案的相关性)用于评估生成的答案与给定提示的相关程度。如果答案不完整或包含冗余信息,那么得分会较低,而较高的得分则表示答案与问题更加相关。此指标的计算采用了特定的方法或标准。
相关性的定义是原始user_input与多个通过逆向工程生成的基于response的人工生成的问题之间的平均余弦相似度:
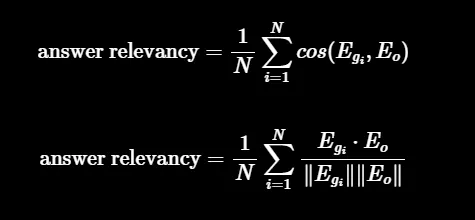
如下。
- Egi 是生成的问题 i 的嵌入表示。
- Eo 是原始问题的嵌入表示。
- N 表示生成的问题数量,默认为 3。
from ragas import SingleTurnSample
from ragas.metrics import ResponseRelevancy
sample = SingleTurnSample(
user_input="第一届超级碗是什么时候举办的?",
response="第一届超级碗是在1967年1月15日举行的",
retrieved_contexts=[
"第一届美式足球联盟对抗国家橄榄球联盟的世界冠军赛于1967年1月15日在洛杉矶纪念体育场举行。"
]
)
scorer = ResponseRelevancy()
await scorer.single_turn_ascore(sample)请问,法国在哪里?它的首都是哪儿?
低相关性回答:法国在西欧,这和问题相关性不高。
简单说就是:法国位于西欧地区,巴黎是它的首都。
我们要通过两个步骤来计算答案和问题的相关性。
-
第一步: 使用大型语言模型(LLM)从给定的答案中生成’n’个变体问题。例如,对于第一个给定的答案,LLM可能会生成以下可能的问题:
-
问题 1: “法国位于欧洲的哪个部分?”
-
问题 2: “法国在欧洲的地理位置位于哪里?”
-
问题 3: “你能指出法国在欧洲的哪个区域吗?”
- 第二步: 计算生成的问题与原问题之间的平均余弦相似度。
召回指的是成功找到的相关文档或信息的数量。它主要是确保不遗漏重要结果。召回率越高,意味着遗漏的相关文档就越少。简单来说,召回的重点就是不要错过任何重要的信息。计算召回率时,总是需要一个参照标准来进行对比。
通过 user_input、reference 和 retrieved_contexts 计算得出,该指标的取值范围在 0 到 1 之间,值越高表示性能越好。此指标利用 reference 作为 reference_contexts 的代理,这样也使得该指标更容易使用,因为标注参考上下文可能非常耗时。为了估算 reference 中上下文的召回率,需要将其分解为声明,每个声明都将在 reference 回答中被分析,以确定它是否可以归因于检索到的上下文。在理想情况下,reference 中的所有声明都应该能够归因于检索到的上下文。

from ragas.dataset_schema import SingleTurnSample
from ragas.metrics import LLMContextRecall
sample = SingleTurnSample(
user_input="埃菲尔铁塔位于哪个城市?",
response="埃菲尔铁塔坐落在巴黎。",
reference="埃菲尔铁塔位于巴黎。",
retrieved_contexts=["检索到的上下文信息:['巴黎是法国的首都。']"],
)
context_recall = LLMContextRecall()
await context_recall.single_turn_ascore(sample)上下文准确度是一个衡量retrieved_contexts中相关片段比例的指标,其中retrieved_contexts是指检索到的上下文片段。它通过计算每个片段的准确率@k的平均值来得出。准确率@k是指在等级k中,相关片段数量与总片段数量的比例。

其中 K 是 retrieved_contexts 中片段的总数,vk∈{0,1} 表示第 k 个的相关性标记。
这个指标可以在你既有检索到的内容,又有与 user_input 关联的参考上下文时使用。为了判断检索到的内容是否相关,这种方法会利用大语言模型来比较 retrieved_contexts 中的每个片段与 response。
from ragas import SingleTurnSample
from ragas.metrics import LLMContextPrecisionWithoutReference
context_precision = LLMContextPrecisionWithoutReference()
sample = SingleTurnSample(
user_input="埃菲尔铁塔位于哪里?",
response="埃菲尔铁塔位于巴黎。",
retrieved_contexts=["埃菲尔铁塔位于巴黎。"],
)
await context_precision.single_turn_ascore(sample) from datasets import Dataset
import os
from ragas import evaluate
from ragas.metrics import faithfulness, answer_correctness
data_samples = {
'question': [
'第一届超级碗是什么时候举行的?',
'谁赢得过最多的超级碗比赛?'
],
'answer': [
'第一届超级碗在1967年1月15日举行',
'新英格兰爱国者队已经六次赢得超级碗冠军'
],
'contexts': [
[
'美式足球联盟与全国橄榄球联盟的第一次世界冠军赛于1967年1月15日在洛杉矶纪念体育场举行。'
],
[
'绿湾包装工队...位于威斯康星州的绿湾。',
'包装工队...参加的是全国橄榄球联盟的比赛。'
]
],
'ground_truth': [
'第一届超级碗在1967年1月15日举行',
'新英格兰爱国者队已经六次赢得超级碗冠军'
]
}
dataset = Dataset.from_dict(data_samples)
score = evaluate(dataset, metrics=[faithfulness, answer_correctness])
df = score.to_pandas()
df.to_csv('score.csv', index=False)




