

所有图片均为作者拍摄
几个月前,苹果低调发布了其第一个公开版本的MLX框架,这个框架填补了PyTorch、NumPy和Jax之间的空白,但优化了对苹果芯片(Silicon)的支持。简而言之,就像这些库一样,MLX是以Python为前端的API,其底层操作主要以C++实现。
以下是关于PyTorch之间相似点和不同点的一些观察。我使用PyTorch及其Apple Silicon GPU硬件加速支持实现了一个自定义的卷积神经网络,并在几个不同的数据集上进行了测试,特别是MNIST数据集、CIFAR-10数据集和CIFAR-100数据集。
下面提到的所有代码都可以在这个链接找到。这里。
- 方法
- 关于MLX的注释
- 性能
- 最后的思考
我首先用PyTorch来实现这个模型,因为我对这个框架更熟悉。该模型有一系列的卷积和池化层,后面跟着几个加入了dropout的全连层。
# 第一个块:Conv => ReLU => MaxPool
self.conv1 = Conv2d(in_channels=channels, out_channels=20, kernel_size=(5, 5), padding=2)
self.relu1 = ReLU()
self.maxpool1 = MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
# 第二个块:Conv => ReLU => MaxPool
self.conv2 = Conv2d(in_channels=20, out_channels=50, kernel_size=(5, 5), padding=2)
self.relu2 = ReLU()
self.maxpool2 = MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
# 第三个块:Conv => ReLU => MaxPool 层
self.conv3 = Conv2d(in_channels=50, out_channels=final_out_channels, kernel_size=(5, 5), padding=2)
self.relu3 = ReLU()
self.maxpool3 = MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
# 第四个块:Linear => Dropout => ReLU 层
self.linear1 = Linear(in_features=fully_connected_input_size, out_features=fully_connected_input_size // 2)
self.dropout1 = Dropout(p=0.3)
self.relu3 = self.relu3 # Corrected to maintain consistency with the original code style and avoid repetition
# 第五个块:Linear => Dropout 层
self.linear2 = Linear(in_features=fully_connected_input_size // 2, out_features=fully_connected_input_size // 4)
self.dropout2 = Dropout(p=0.3)
# 第六个块:Linear => Dropout 层
self.linear3 = Linear(in_features=fully_connected_input_size // 4, out_features=classes)
self.dropout3 = Dropout(p=0.3)
self.logSoftmax = LogSoftmax(dim=1);这种架构对于MNIST数据集的分类来说有些冗余,但我希望用一些较复杂的架构来比较这两个框架。我用CIFAR数据集测试了这个架构,准确率大约在40%左右;还算可以,但对于一个不是ResNet的模型来说,这种表现还算可以。
完成这个实现之后,我写了一个利用MLX的并行版本。我高兴地发现,导入必要的MLX模块并替换掉PyTorch模块之后,大部分的PyTorch代码可以直接复用。
例如,上述代码的 MLX 版本在这里:here;它完全一样,只是命名参数稍有不同。
MLX的一些笔记MLX有几点特性挺有意思的,值得关注一下。
数组MLX的[array](https://ml-explore.github.io/mlx/build/html/python/array.html)类代替了[Tensor](https://pytorch.org/docs/stable/tensors.html);其文档大多将其与NumPy的[ndarray](https://numpy.org/doc/stable/reference/generated/numpy.ndarray.html#numpy.ndarray)进行比较,同时,它也是该框架中各种神经网络层用于及返回的数据类型。
array 大多按你所期望的方式工作,但在将深层嵌套的 np.ndarrays 和 mlx.arrays 相互转换时遇到了一些麻烦,需要做一些 [列表类型转换] 以确保一切正常工作。
在 MLX 中,操作 是惰性求值;也就是说,在惰性构建的计算图里,只有生成程序实际用到的输出的计算才会被执行。
有两种方法可以强制执行运算操作的结果,例如推理:
- 调用
mlx.eval()在输出结果上。 - 不论出于什么原因引用变量的值;例如在日志记录或条件判断中。
这在管理代码性能时可能会稍微复杂一点,因为对任何值的引用(即使是偶然)都会触发对该变量以及依赖图中的所有中间变量的计算。例如:
对任何值的引用(即使是偶然)会触发对该变量及其依赖图中的所有中间变量的计算。
def classify(X, y):
model = MyModel() # 尚未初始化模型
p = model(X) # 尚未计算
loss = mlx.nn.losses.nll_loss(p, y) # 尚未计算
print(f"loss value: {loss}") # 初始化 `model` 并计算 `loss` 和 `p`
mlx.eval(p) # 无操作
# 如果没有上述的 print() 语句,将会返回 `p` 和延迟计算的 `loss`
return p, loss 这种做法也使得在 PyTorch 和基于 MLX 的模型之间构建一对一的基准测试稍微有点困难。由于训练循环可能不会在循环内部评估输出结果,因此需要强制计算以便跟踪实际操作的具体时间。
test_start = time.perf_counter_ns() # 记录开始时间
accuracy, _ = eval(test_data_loader, model, n) # 评估函数,可能需要注释说明具体含义
mx.eval(accuracy) # 强制评估
test_end = time.perf_counter_ns() # 记录结束时间在积累大型隐式计算图和定期评估该图之间存在权衡。例如,我能够懒散地遍历整个模型在数据集上的所有训练周期,仅用几秒钟。然而,最终评估该(假设庞大的)隐式图所需的时间大致与每次批次后执行eval的时间相同。但这并不总是如此。
MLX 提供了通过 编译 来优化纯函数执行的性能。这能通过直接调用 mlx.compile() 或者在纯函数上添加注解 @mlx.compile 来实现。
在用编译函数的时候,但需要注意的是,有一些坑与状态修改相关;这些问题在文中有所提及。
看来这会将逻辑编译成Metal着色器语言(MSL),并在GPU上运行(我之前在这里研究过MSL:这篇文章)。
API 兼容性和代码约定如上所述,将我的大部分PyTorch代码转换成基于MLX的等效代码很容易。不过也有一些不同之处,:
需要注意的是,原文结尾的冒号在翻译中可以保留,或者根据上下文选择使用破折号来引出后面的详细说明。这里选择保留原文的冒号以保持一致性。
- 神经网络的各个层各自需要不同配置的输入。例如,
[mlx.nn.Conv2d](https://ml-explore.github.io/mlx/build/html/python/nn/_autosummary/mlx.nn.Conv2d.html#mlx.nn.Conv2d)需要输入图像使用NHWC格式(其中C表示通道维度),而[torch.nn.Conv2d](https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html)则需要NCHW;还有其他一些例子。这需要一些条件张量/数组的重新排列。 - 很遗憾,目前 MLX 没有提供类似于 PyTorch 的相对“简单”的数据集和数据加载器,我不得不自己手工实现了一个类似的东西:这里。
- 模型实现,继承自
nn.Module,不需要重写forward()方法,而是重写__call__()方法来进行推理。 - 我认为这可能是因为函数编译的可能性以及上面提到的惰性求值支持,使用 MLX 优化器进行训练的过程与典型的 PyTorch 模型有些不太一样。与后者不同,我们通常习惯于使用类似这样的标准格式:
# 对每个数据批次进行迭代
for X, y in dataloader:
# 使用模型对输入数据进行预测
p = model(X)
# 计算损失值
loss = loss_fn(p, y)
# 清除优化器中的梯度
optimizer.zero_grad()
# 反向传播计算梯度
loss.backward()
# 更新模型参数
optimizer.step()MLX鼓励并似乎期望采用如下格式,如下格式取自文档和仓库中的一个示例:
def loss_fn(model, X, y):
return nn.losses.cross_entropy(model(X), y, reduction="mean") # (计算均值)
# 定义了 `loss_and_grad_fn` 为 `nn.value_and_grad(model, loss_fn)`
loss_and_grad_fn = nn.value_and_grad(model, loss_fn)
# 使用偏函数装饰器定义 `step` 函数来处理每个批次的数据,并返回损失值
@partial(mx.compile, inputs=model.state, outputs=model.state)
def step(X, y):
loss, grads = loss_and_grad_fn(model, X, y)
optimizer.update(model, grads)
return loss
# 通过 `batch_iterate` 函数以批次大小(`batch_size`)处理训练图像(`train_images`)和标签(`train_labels`)
for X, y in batch_iterate(batch_size, train_images, train_labels):
loss = step(X, y)这还行,但比我想象的要复杂一点。不过,一切都还挺熟悉的。
性能以下所有结果均来自我的 MacBook Air M2,需要注意的是,
这个CNN有三种配置:PyTorch CPU,PyTorch GPU,和MLX GPU。为了简单检查,在30多个epoch后,三种配置在准确率和损失方面的比较结果如下:
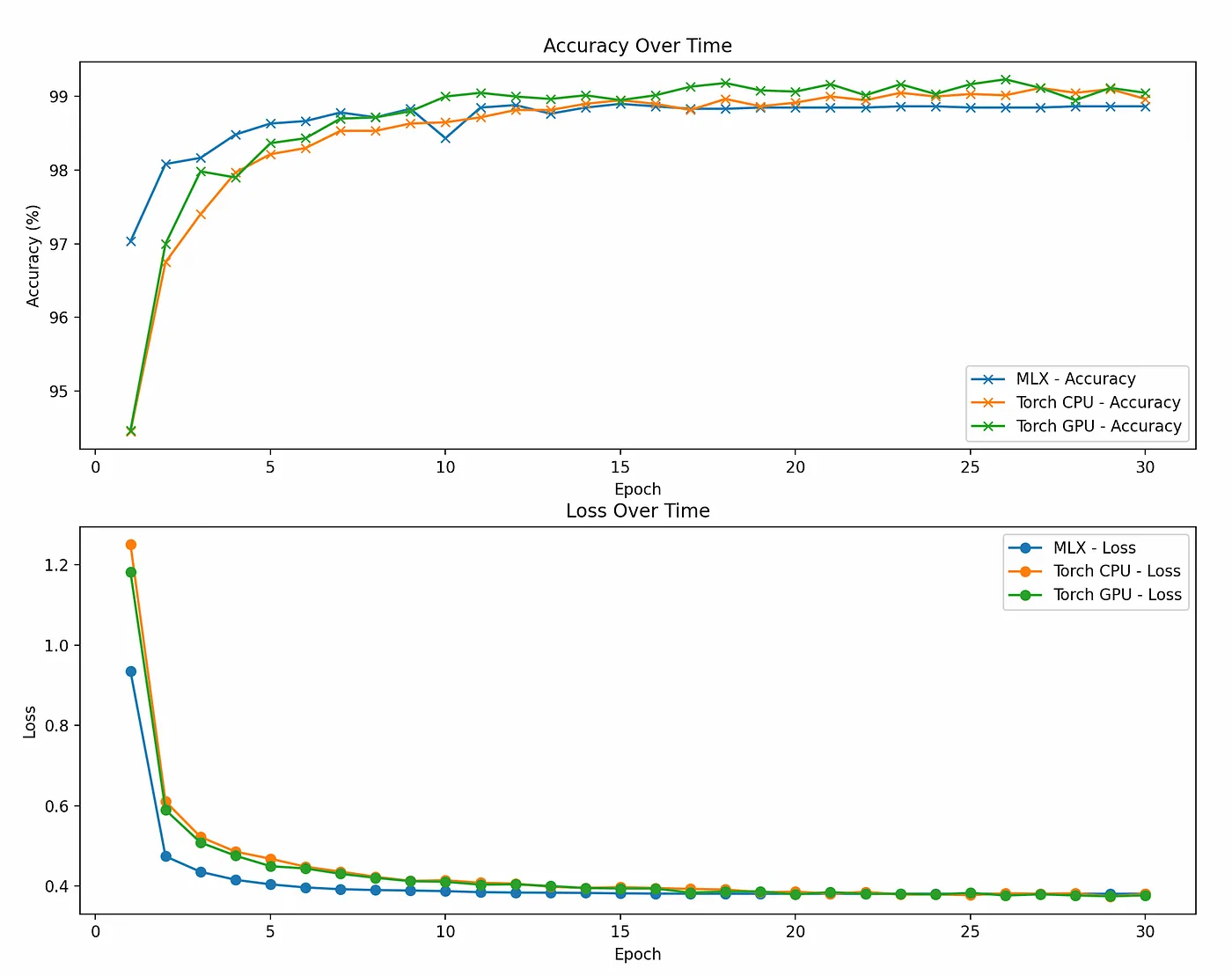
准确性和损失值在30个周期内的演变;可视化代码示例可以在相关链接的仓库中找到。
这里的结果都差不多,但是基于MLX的模型似乎比PyTorch模型更快地达到稳定,这很有趣。
此外,MLX模型的准确性总是稍微低于PyTorch框架的模型。我不太清楚是什么原因导致了这种差异。
在运行性能方面,我还发现了一些有趣的性能结果。
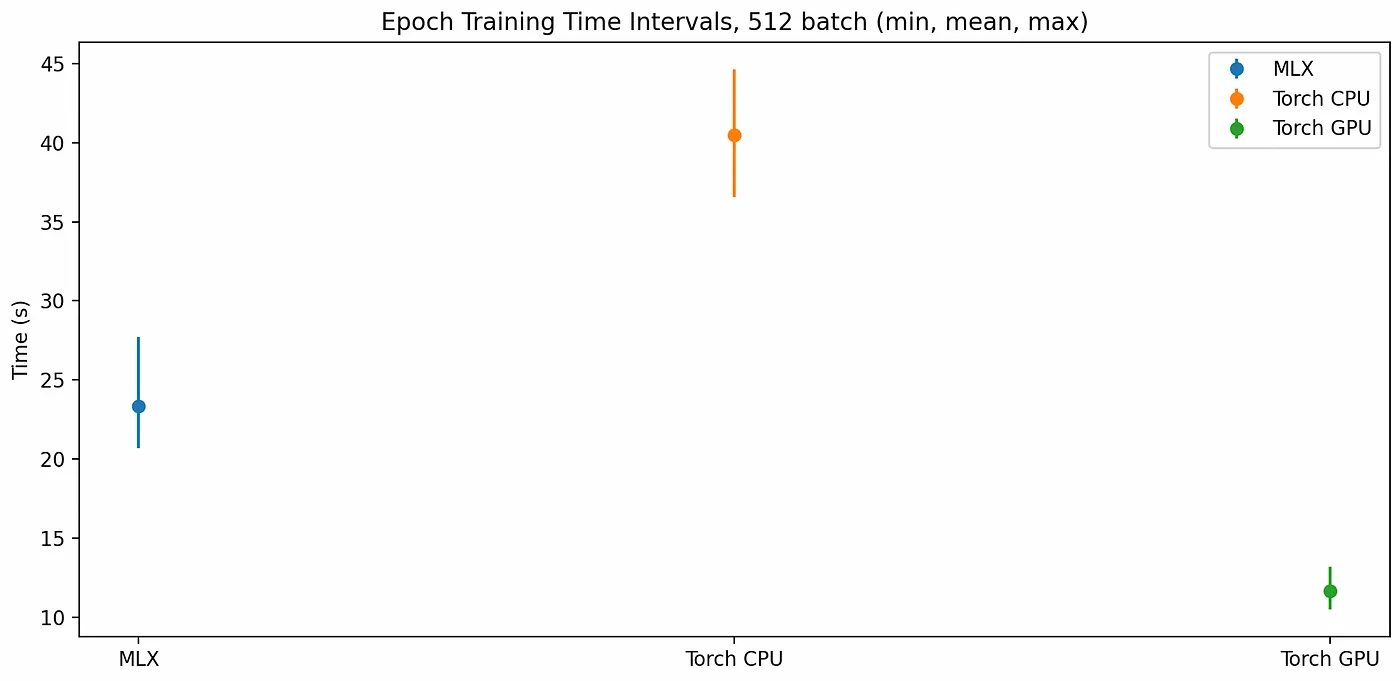
在三种不同设置下,每个训练周期的运行时间波动情况
训练模型时,基于PyTorch的CPU上的模型不出所料地用时最长,每个epoch需要36到45秒。运行在GPU上的MLX模型则每个epoch大约需要21到27秒。而PyTorch通过MPS设备在GPU上运行时,在这方面明显占优,每个epoch只需10到14秒。
在一万张图像的测试数据集上进行分类显示了一个不同的故事。
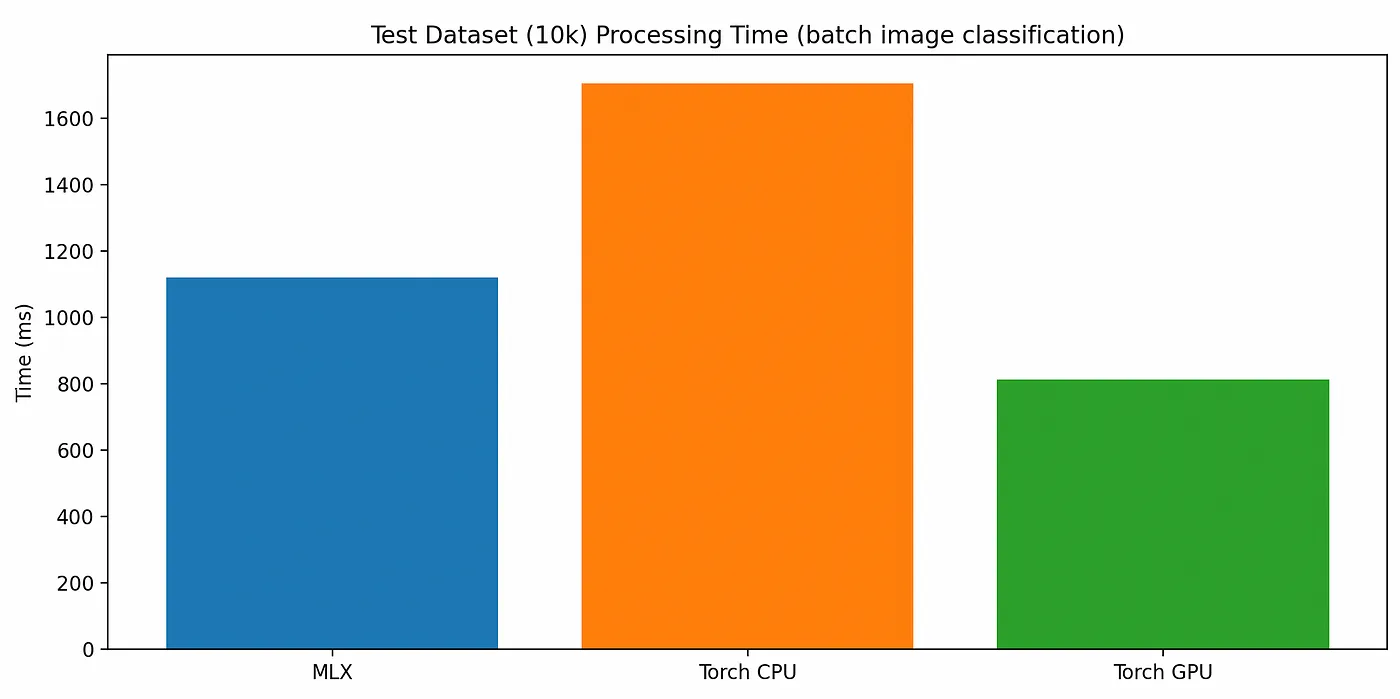
每个模型版本分类测试数据集中的所有10,000张图像所需的总时间,批量大小为512,
使用CPU的模型大约需要1700毫秒来分类所有10k张图片,每次处理512张,而使用GPU的模型则分别只需要1100毫秒(“MLX”)和850毫秒(“PyTorch”)来完成这个任务。
但是,当逐个而不是批量处理图像时。
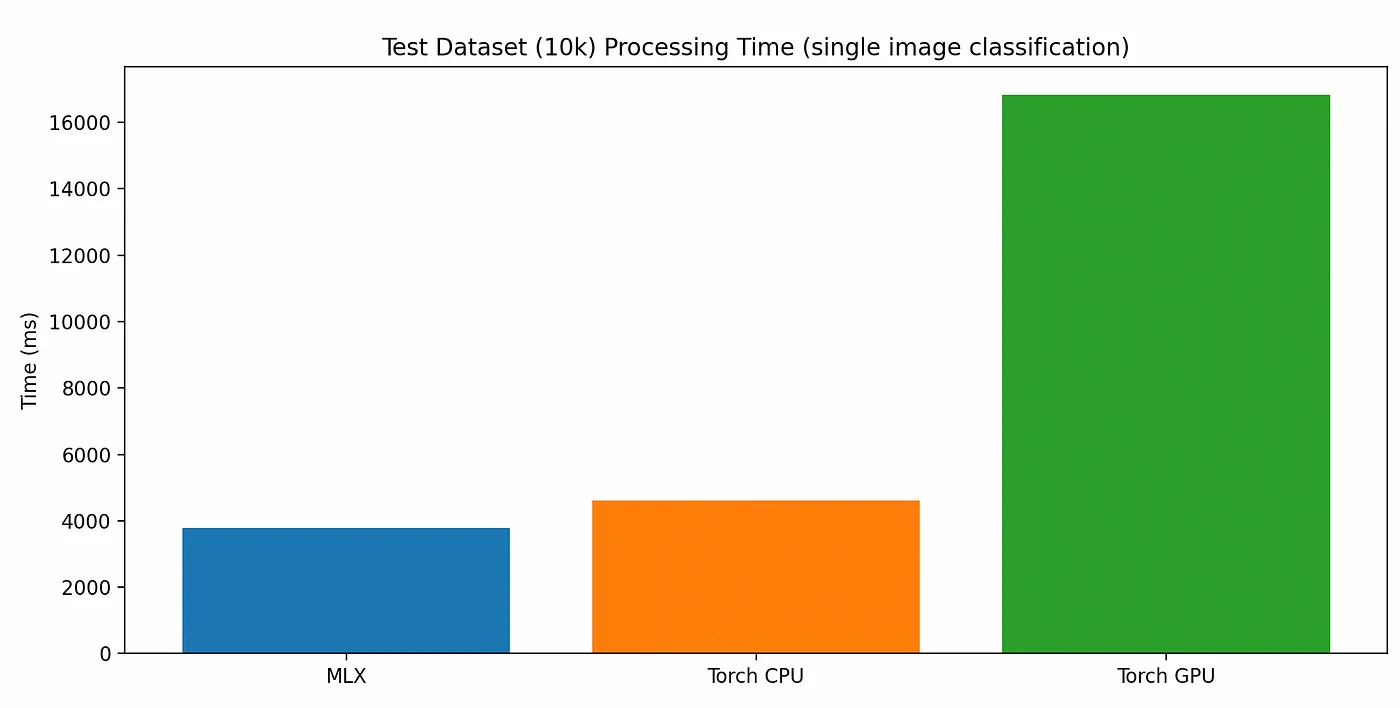
每次处理一张,共处理一万张图片,每种模型变体的总耗时;这些图片来自数据集中的所有10k张图片。
苹果的硅芯片(Apple Silicon)使用了一种称为“统一内存模型”的技术,这意味着当在 PyTorch 中通过类似 .to(torch.device("mps")) 的方式将数据和模型 GPU 设备设置为 mps 时,实际上并没有将数据移动到物理 GPU 的专用内存。因此,PyTorch 在初始化苹果的硅芯片 GPU 以执行代码时的开销似乎比较大。如上所述,在处理并行批量工作负载时,它的表现非常出色。但在对单个记录进行分类的训练后,其表现远远不如 MLX 快速启动 GPU 执行的能力。
注:如有特定上下文,可以进一步明确翻译。
简要查看基于 MLX 的模型的 cProfile 输出,按累计执行时间从高到低排序的结果:
ncalls tottime percall cumtime percall filename:lineno(function)
426 86.564 0.203 86.564 0.203 {内置函数 mlx.core.eval}
1 2.732 2.732 86.271 86.271 /Users/mike/code/cnn/src/python/mlx/cnn.py:48(训练)
10051 0.085 0.000 0.625 0.000 /Users/mike/code/cnn/src/python/mlx/model.py:80(__call__)
30153 0.079 0.000 0.126 0.000 /Users/mike/Library/Python/3.9/lib/python/site-packages/mlx/nn/layers/pooling.py:23(_sliding_windows)
30153 0.072 0.000 0.110 0.000 /Users/mike/Library/Python/3.9/lib/python/site-packages/mlx/nn/layers/convolution.py:122(__call__)
1 0.062 0.062 0.062 0.062 {内置函数 _posixsubprocess.fork_exec}
40204 0.055 0.000 0.055 0.000 {内置函数 relu}
10051 0.054 0.000 0.054 0.000 {内置函数 mlx.core.mean}
424 0.050 0.000 0.054 0.000 {内置函数 step}我们在某些层函数上花了一些时间,但大部分时间都花在了 mlx.core.eval() 这个地方,这是有道理的,因为在图的这个阶段,实际的计算正在发生。
使用 [asitop](https://github.com/tlkh/asitop) 来可视化来自 MacOS 的 powertools 数据:
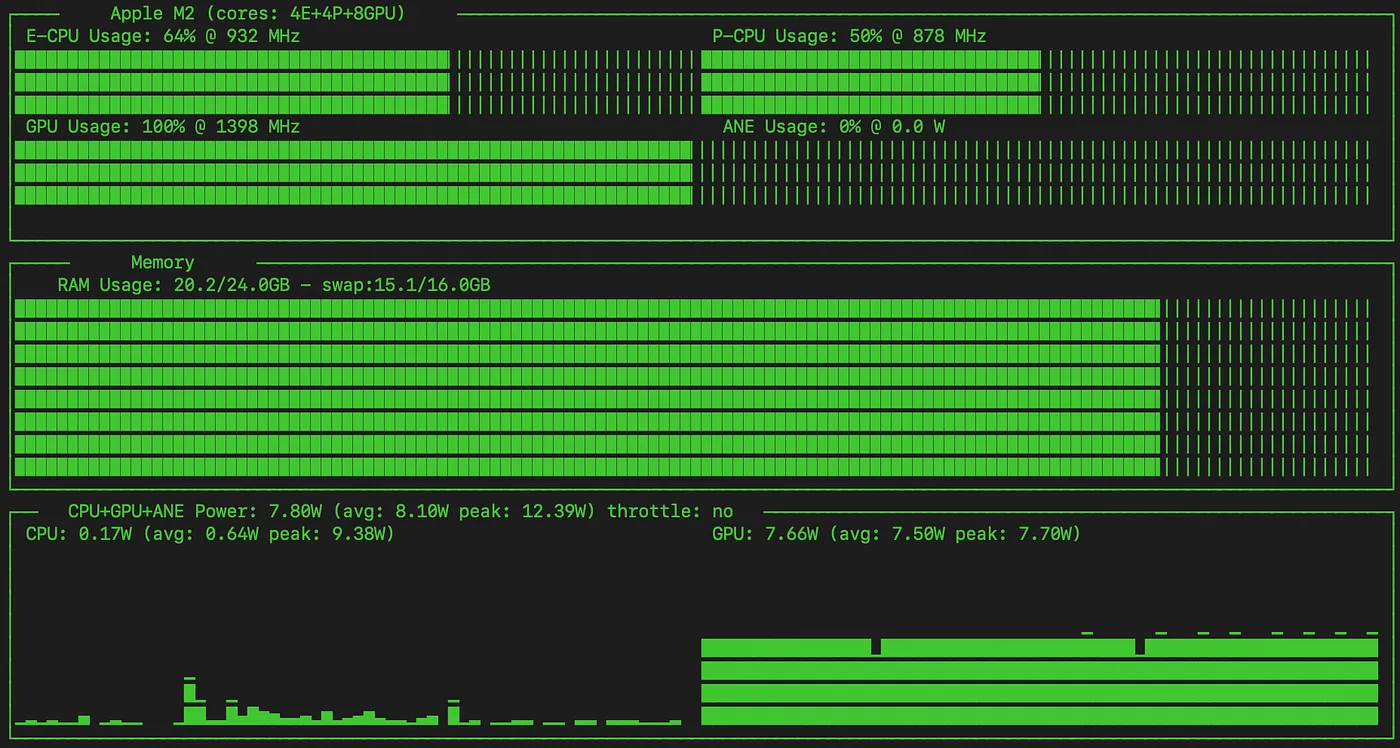
MLX 模型, 功率历史
可以看到,在这个模型的训练过程中,GPU已经满载运行,其运行频率达到了1398 MHz。
现在我们来看看 PyTorch GPU 版本。
ncalls tottime percall cumtime percall filename:lineno(function)
15585 41.385 0.003 41.385 0.003 {方法 'item' 的 'torch._C.TensorBase' 对象}
20944 6.473 0.000 6.473 0.000 {内置方法 torch.stack}
31416 1.865 0.000 1.865 0.000 {内置方法 torch.conv2d}
41888 1.559 0.000 1.559 0.000 {内置方法 torch.relu}
31416 1.528 0.000 1.528 0.000 {内置方法 torch._C._nn.linear}
31416 1.322 0.000 1.322 0.000 {内置方法 torch.max_pool2d}
10472 1.064 0.000 1.064 0.000 {内置方法 torch._C._nn.nll_loss_nd}
31416 0.952 0.000 7.537 0.001 /Users/mike/Library/Python/3.9/lib/python/site-packages/torch/utils/data/_utils/collate.py:88(collate)
424 0.855 0.002 0.855 0.002 {方法 'run_backward' 的 'torch._C._EngineBase' 对象}
5 0.804 0.161 19.916 3.983 /Users/mike/code/cnn/src/python/pytorch/cnn.py:176(eval)有趣的是,最常用的函数是 Tensor.item(),这个函数在代码的多个地方用于计算损失和准确率,也可能在较低的层中被使用。如果在训练过程中不跟踪损失和准确率,整体训练性能可能会有显著的提高。
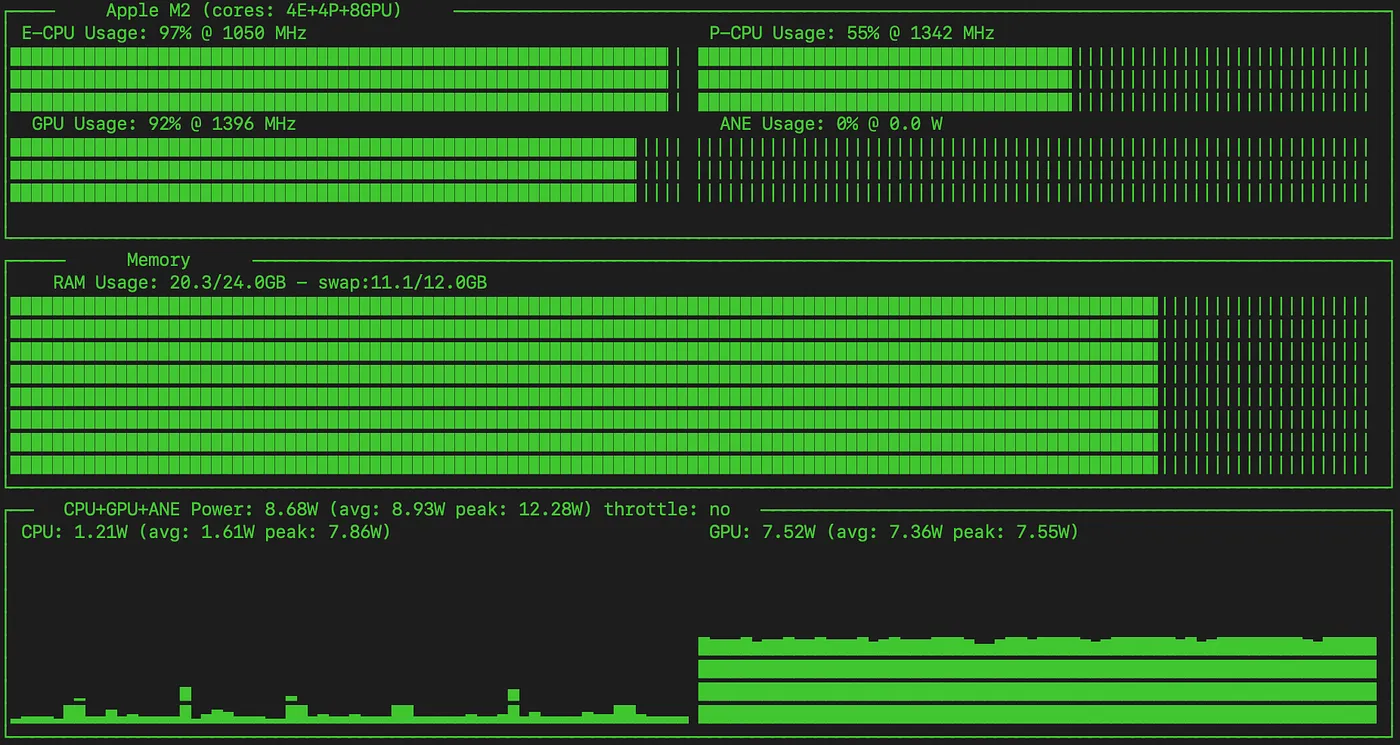
从历史的角度看 — PyTorch GPU 模型的运行
与MLX模型相比,PyTorch版本在训练过程中没有看到其GPU使用率超过95%,并且在CPU的E核心和P核心上也有更均衡的使用。
有趣的是,MLX模型更依赖于GPU,不过训练速度却慢了很多。
两个模型(基于CPU或GPU的)似乎都没有使用ANE(Apple神经引擎)。(Apple Neural Engine)
最后MLX很容易上手,对于有PyTorch和NumPy使用经验的人来说,这应该也是这样。虽然一些开发者文档略显简略,但由于其目的是提供与这些框架API兼容的工具,所以很容易通过相应的PyTorch或NumPy文档轻松填补任何空白(例如,SGD [1] [2])。
MLX模型的整体表现还不错;我不清楚自己是否期望它能持续优于PyTorch的mps设备支持。虽然使用PyTorch在GPU上训练似乎快得多,但对于这一模型而言,尤其是大规模的单个项目预测,通过MLX要快得多。这可能是我的MLX配置原因,也可能是框架本身的特性,真不好说(如果是前者——请随时在GitHub上提交问题!)





