
本文解释了如何使用网页技术实现实时语音转文字。它介绍了系统架构、组件,以及实现实时功能的技术,包括前端管理的audioStore和transcriptionStore,以及后端的TranscriptionHandler。
实时语音转文字可以实现实时字幕、虚拟助手和语音回复系统功能。此实现采用了 Vue.js 和 Nuxt.js 以及 Pinia 作为前端,使用 Python 和 FastAPI 作为后端,使用 WebSockets 进行通信,并利用 OpenAI 的 Whisper 进行语音转文字。
架构简介实现方式采用的是客户端-服务器架构,分为两个主要部分。
- 前端:负责音频采集、处理、状态控制及用户界面交互。
- 后端:管理语音转文字服务、多线程处理和WebSocket连接。
你可以使用下面的PlantUML图来绘制架构的可视化。
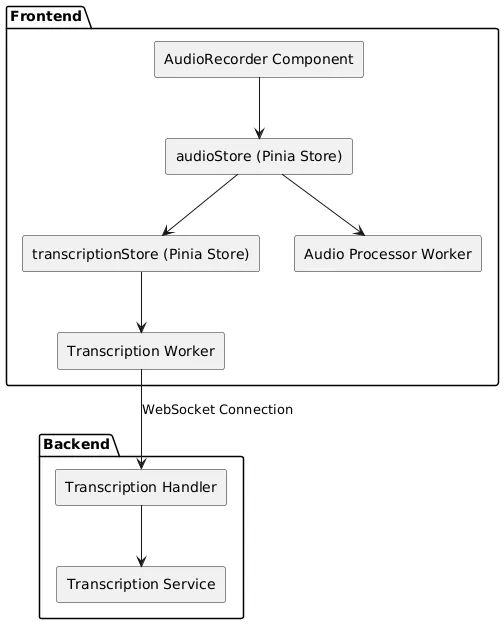
图1:实时转写实现方案的高层架构图。
前端元素 简介前端是用 Vue.js 和 Nuxt.js 搭建的,并使用 Pinia 进行状态管理。其中包括:
- 这些组件:主要负责用户界面和显示。
- Pinia 仓库:管理应用状态和逻辑。
- Web Workers:处理计算密集型任务而不阻塞主线程。
AudioRecorder.vue)
角色:
- 提供开始和停止录制的用户界面。
- 实时显示转写的文字。
- 与
audioStore和transcriptionStore进行交互以支持录音和转写功能。
关键实现细节:
- 这个组件主要处理用户交互并显示信息。
- 它将记录和转录的逻辑委托给相应的 Pinia 存储器。
代码片段:
<template>
<div class="space-y-4">
<div class="flex items-center space-x-2">
<button @click="handleRecordingToggle" :disabled="disabled || audioStore.isStopping">
<span>{{ buttonText }}</span>
</button>
<!-- 其他 UI 元素 -->
</div>
<!-- 显示转录文本 -->
<div v-if="conversationStore.currentRequirement">
<p>{{ conversationStore.currentRequirement }}</p>
</div>
</div>
</template>
<script setup lang="ts">
import { computed } from 'vue';
import { useAudioStore } from '~/stores/audioStore';
import { useTranscriptionStore } from '~/stores/transcriptionStore';
import { useConversationStore } from '~/stores/conversationStore';
const audioStore = useAudioStore();
const transcriptionStore = useTranscriptionStore();
const conversationStore = useConversationStore();
const buttonText = computed(() => {
if (audioStore.isStopping) return '停止...';
return audioStore.isRecording ? '正在录音...' : '开始录音吧';
});
const handleRecordingToggle = async () => {
if (!audioStore.isRecording) {
await audioStore.startRecording(workspaceId, stepId);
} else {
await audioStore.stopRecording(workspaceId, stepId);
}
};
</script>audioStore (Pinia 存储库)
角色:
- 管理音频录制流程。
- 对接
Audio Processor Worker以处理音频。 - 控制录音会话的开始和结束。
- 管理已录音频片段的状态。
关键实施细节:
- 利用Web音频API从用户的麦克风捕获音频。
- 使用
AudioWorklet(音频处理器工作线程(Audio Processor Worker))将原始音频数据处理成WAV格式。 - 存储音频片段并提供相应的管理功能(例如,下载和删除)。
代码段:
// audioStore.ts
import { defineStore } from 'pinia';
export const useAudioStore = defineStore('audio', {
state: () => ({
isRecording: false,
audioChunks: [],
// 其他状态相关的属性
}),
actions: {
async startRecording(workspaceId: string, stepId: string) {
// 初始化媒体流和音频上下文
// 连接到音频处理工作线程
// 开始录音过程
},
async stopRecording(workspaceId: string, stepId: string) {
// 停止媒体流
// 停止音频处理工作线程
// 完成转写
},
// 其他与音频块管理相关的操作
},
});转录存储(Pinia框架的存储)
你的角色:(Your Role)
- 通过 WebSocket 管理与后端的通信。
- 处理并发送音频数据以进行转录。
- 接收转录结果并更新状态。
- 与
Transcription Worker进行 WebSocket 通信接口。
一些关键的实现细节:
- 建立 WebSocket 连接与后端,并维持连接。
- 将从
audioStore接收的音频数据发送到后端。 - 将转录的文字更新到
conversationStore。
代码片段 如下:
// transcriptionStore.ts
import { defineStore } from 'pinia';
export const useTranscriptionStore = defineStore('transcription', {
state: () => ({
isConnected: false,
transcription: '',
// 其他状态属性等等
}),
actions: {
initializeWorker() {
this.worker = new Worker(new URL('~/workers/transcriptionWorker.ts', import.meta.url), {
type: 'module',
});
this.setupWorkerHandlers();
// 向转录 Worker 发送音频片段
},
setupWorkerHandlers() {
this.worker.onmessage = (event) => {
const { type, payload } = event.data;
if (type === 'MESSAGE') {
this.handleWorkerMessage(payload);
}
// 处理其他类型的消息
};
},
handleWorkerMessage(message) {
if (message.type === 'transcription') {
this.transcription += message.text + ' ';
// 更新 conversationStore 的新转录内容
}
},
async sendAudioChunk(audioChunk: ArrayBuffer) {
// 向转录 Worker 发送音频片段
},
// 其他 WebSocket 连接管理操作
},
});audio-processor.worklet.js)
目的是:
- 处理由
audioStore捕获的原始音频数据。 - 将原始音频流转换成符合 Whisper 模型要求的 WAV 格式。
- 它作为一个
AudioWorklet运行,这是一种在音频渲染线程上执行的高性能音频处理脚本。
关键的实现细节:
- 处理小块的音频数据以支持实时处理。
- 将音频调整采样率为目标采样率(例如,16kHz)。
- 将音频数据编码成16位PCM WAV格式。
下面是一个代码片段 :
// audio-processor.worklet.js
class AudioChunkProcessor extends AudioWorkletProcessor {
constructor(options) {
super();
// 不需要初始化任何内容
}
process(inputs, outputs, parameters) {
// 处理音频数据
// 重采样并编码成 WAV
// 发送处理过的音频数据
return true;
}
}
registerProcessor('audio-chunk-processor', AudioChunkProcessor);transcriptionWorker.ts)
职责:
- 与后端服务器建立 WebSocket 连接,并进行握手。
- 将处理过的音频数据发送到后端进行转录。
- 从后端接收转录的文本,并转发给
transcriptionStore。
实现的关键细节:
- 管理 WebSocket 的生命周期,包括连接、断开和错误处理。
- 处理音频片段的二进制数据传输过程。
- 解析接收到的消息并将其转发到
transcriptionStore。
如下代码段:
// transcriptionWorker.ts
let socket;
onmessage = (event) => {
// 解构消息数据
const { type, payload } = event.data;
switch (type) {
case 'CONNECT':
initWebSocket(payload);
break;
case 'SEND_AUDIO':
socket.send(payload.wavData);
// 发送音频数据
break;
// 其他消息处理
}
};
function initWebSocket({ workspaceId, stepId, transcriptionWsEndpoint }) {
// 初始化WebSocket连接
socket = new WebSocket(`${transcriptionWsEndpoint}/${workspaceId}/${stepId}`);
// 创建并监听WebSocket连接
socket.onmessage = (event) => {
const message = JSON.parse(event.data);
// 发送接收到的消息
postMessage({ type: 'MESSAGE', payload: message });
};
}后端用Python和FastAPI开发。它包括以下内容:
- 转录处理程序 (
handler.py) 负责管理线程、多个WebSocket会话,并协调转录请求。 - 转录服务 (
service.py) 只负责处理音频数据的转录,不涉及线程管理。
handler.py)
负责:
或更自然的表达方式:
负责如下:
- 与客户端的 WebSocket 连接。
- 多线程管理和协调多个 WebSocket 会话。
- 将转录请求排队并分发给转录工作者。
- 处理转录结果并将它们回传给客户端。
关键实现要点 ,
- 使用线程和异步编程高效处理多个连接请求。
- 为转写请求和结果分别维护独立的队列,以确保高效处理。
TranscriptionWorker线程按顺序处理转写请求。- 每个客户端会话都有一个唯一的
session_id用来标识。
代码段:
下面是一个代码片段示例:
# handler.py
import asyncio
import queue
import threading
from fastapi import WebSocket
from .service import TranscriptionService
class TranscriptionHandler:
def __init__(self):
self.transcription_service = TranscriptionService()
self.active_connections = {}
self.output_queues = {}
self.loop = asyncio.get_event_loop()
self.worker = TranscriptionWorker(self.transcription_service, self.loop)
self.worker.start()
async def connect(self, websocket: WebSocket, workspace_id: str, step_id: str) -> str:
await websocket.accept()
session_id = str(uuid.uuid4())
self.active_connections[session_id] = websocket
self.output_queues[session_id] = asyncio.Queue()
self.worker.result_queues[session_id] = self.output_queues[session_id]
asyncio.create_task(self._receive_audio(websocket, session_id))
asyncio.create_task(self._send_results(websocket, session_id))
await websocket.send_json({"type": "session_init", "session_id": session_id})
return session_id
async def _receive_audio(self, websocket: WebSocket, session_id: str):
while True:
audio_data = await websocket.receive_bytes()
request = TranscriptionRequest(session_id=session_id, audio_data=audio_data, timestamp=time.time())
self.worker.request_queue.put_nowait(request)
async def _send_results(self, websocket: WebSocket, session_id: str):
while True:
result = await self.output_queues[session_id].get()
await websocket.send_json(result)录音转写员:
- 一个独立的线程,依次处理转录请求。
- 与
TranscriptionService交互来进行实际的转录。
class TranscriptionWorker(threading.Thread):
def __init__(self, transcription_service: TranscriptionService, loop: asyncio.AbstractEventLoop):
super().__init__()
self.transcription_service = transcription_service
self.request_queue = queue.Queue()
self.result_queues = {}
self.loop = loop
def run(self):
while True:
request = self.request_queue.get()
if request is None:
break # 关闭指令
transcription = self.transcription_service.transcribe(request.audio_data)
if request.session_id in self.result_queues:
result_queue = self.result_queues[request.session_id]
asyncio.run_coroutine_threadsafe(
result_queue.put({
"type": "transcription",
"text": transcription,
"timestamp": request.timestamp
}),
self.loop
)service.py)
手柄:
- 使用OpenAI Whisper模型对音频数据进行转录。
- 不处理线程;当处理请求时,
TranscriptionWorker会调用它。
一些关键的实现细节如下:
- 启动Whisper模型和处理器。
- 根据系统能力选择合适的设备和数据类型。
- 无需担心线程管理,因为线程管理由
TranscriptionHandler和TranscriptionWorker来处理,专注于转录即可。
代码片段。
# service.py
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
class TranscriptionService(metaclass=SingletonMeta):
'''
单例元类的转录服务类
'''
def __init__(self):
self.device, self.torch_dtype = self._setup_device_and_dtype() # 设置设备和数据类型
model_id = "openai/whisper-large-v3-turbo"
self.model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id,
torch_dtype=self.torch_dtype,
low_cpu_mem_usage=True,
use_safetensors=True,
).to(self.device)
self.processor = AutoProcessor.from_pretrained(model_id)
device_arg = self._get_pipeline_device()
self.pipe = pipeline(
"automatic-speech-recognition",
model=self.model,
tokenizer=self.processor.tokenizer,
feature_extractor=self.processor.feature_extractor,
torch_dtype=self.torch_dtype,
device=device_arg,
)
self.sampling_rate = 16000 # 设置采样率
# 加载模型和处理器 # 加载模型和处理器
def transcribe(self, audio_data: bytes) -> str: # 定义一个 transcribe 方法来处理音频数据
transcription = self.pipe(audio_data) # 使用管道处理音频数据
return transcription.get("text", "").strip() # 返回处理后的文本关注点分离的强调:
**TranscriptionHandler**:管理线程任务,处理多个 WebSocket 会话,确保转写请求被高效处理。**TranscriptionService**:专注于转写逻辑,不涉及线程管理,使其更易于重复使用和维护。
多个组件协同工作来处理数据流,捕捉、处理、传输并转录实时音频。
数据流程图: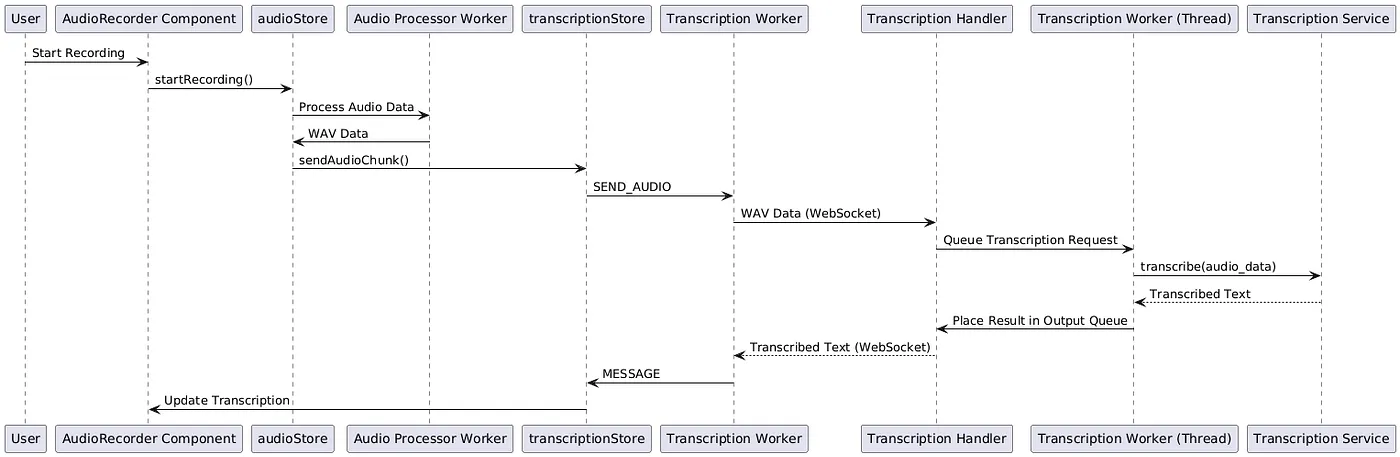
图2——前端与后端组件之间的详细数据流动,着重展示线程与会话的管理。
步骤说明- 音频捕获:用户开始录音,通过
AudioRecorder组件启动录音。 - 开始录音:
AudioRecorder调用audioStore.startRecording()。 - 音频处理:
audioStore设置Audio Processor Worker来将原始音频数据处理成WAV格式。 - 数据传输:处理后的音频片段从
audioStore发送到transcriptionStore,并通过Transcription Worker发送到服务器端。 - 会话管理:
TranscriptionHandler接受WebSocket连接并分配一个唯一的会话ID。 - 线程和队列管理:
TranscriptionHandler通过TranscriptionWorker线程来排队转录请求并管理线程操作。 - 转录处理:
TranscriptionWorker依次处理请求,并调用TranscriptionService进行转录。 - 结果传递:转录的文字被放入输出队列并通过WebSocket连接发送回前端界面。
- 状态更新:
Transcription Worker将转录的文字发送到transcriptionStore,transcriptionStore更新conversationStore。 - 显示:
AudioRecorder组件实时显示转写的文字。
- 目的:高效处理多个客户端连接及转写请求。
- 实现:
TranscriptionHandler使用异步任务来管理这些 WebSocket 连接。- 单独的
TranscriptionWorker线程顺序处理来自所有客户端的转写任务。 - 请求被放入队列,结果通过每个会话特有的输出队列发送回去。
好处有:
- 资源效率:通过使用单个工作线程进行转录,提高了资源利用效率,特别是在处理Whisper这样的大型模型时尤为重要。
- 可扩展性:能够同时处理多个客户端,而不会产生多余的线程或进程。
- 目的:减少延迟,确保实时转写顺畅。
- 实现:
- 音频数据被处理成块并发送,以实现逐步转写。
- 前端和后端均采用异步编程,以处理任务而不阻塞主线程。
- 目的:将繁重任务从主线程转移出去,以防止 UI 卡顿。
- 使用 Worker 的组件:
音频处理 Worker用于音频格式转换。Transcription Worker用于处理 WebSocket 通信处理。
TranscriptionHandler 中的多线程
为什么这很重要:
- 高效地管理多个 WebSocket 会话。
- 保证繁重的转录任务不会阻塞主事件循环的运行。
要点:
- TranscriptionHandler 管理每个会话的单独输入和输出队列。
- TranscriptionWorker 线程从共享队列中处理请求,并将结果返回到相应的会话中。
代码突出显示:
# handler.py
class TranscriptionHandler:
# 初始化方法
def __init__(self):
self.worker = TranscriptionWorker(self.transcription_service, self.loop)
self.worker.start()
# 异步连接方法
async def connect(self, websocket: WebSocket, workspace_id: str, step_id: str) -> str:
# 分配 session_id 并设置相关队列
# 启动后台任务来接收和发送数据- TranscriptionHandler :管理会话的生命周期、线程管理和请求与响应之间的关系。
- TranscriptionService :仅仅关注转写逻辑,使其模块化并易于测试。
转换步骤:
- 重采样:必要时,将采样率改为16kHz。
- 编码::将PCM数据打包成带有正确头部信息的WAV文件。
这段代码示例:
// audio-processor.worklet.js
process(inputs, outputs, parameters) {
// 收集样本
// 当收集的样本数量足够形成一个块时:
// - 转换为16位PCM
// - 创建WAV头
// - 将头与PCM数据合并
// - 通过postMessage发送这个块
}最后,这是结论。
这实现为构建实时转录应用程序提供了基础。模块化架构便于轻松集成新功能和优化性能。完整源代码可在GitHub上找到,并且有一个在线演示可供查看。您可以在您的应用程序中自由使用它。





